Clear Sky Science · zh
CNeuroMod-THINGS:用于视觉神经科学的高密度采样fMRI数据集
为什么看图片能揭示我们思维的运作方式
每天,我们的眼睛接收成千上万幅图像——从咖啡杯和智能手机,到狗、树木和拥挤的街头。背后,大脑快速识别所见事物,并常常将其记住。CNeuroMod-THINGS 项目旨在以非凡的细节捕捉这种隐性活动,创建了在人们观看真实世界图片时采集的最深度的大脑数据集之一。该资源旨在推动下一代脑科学与人工智能研究。
构建丰富的大脑反应库
团队没有在数百名志愿者身上各做一两次扫描,而是反复扫描了四名高度投入的参与者。每位受试者回访33到36次,在更广泛的 CNeuroMod 项目中累计约200小时的脑成像,专门用于图片的时间也有数十小时。在这些实验中,参与者观看了多达4320张来自 THINGS 图像集合的不同照片,该集合覆盖720类日常物体类别,如工具、动物、交通工具和家具。这样的图片选择确保呈现出视觉世界的多个侧面,而非仅仅集中于少数流行对象。

在核磁共振扫描仪内进行的记忆游戏
为了保持参与者的注意力并检测记忆,研究者将图片观看设计成连续识别游戏。每个试次,一张图片显示在屏幕中央,参与者躺在核磁共振扫描仪中。使用定制的视频游戏式控制器,参与者报告他们认为该图片是新见的还是之前见过的,并对该判断给出置信度。大多数图片出现三次:首次出现、同次访问中几分钟后再次出现,以及往后某次访问中再次出现,通常相隔约一周。该设计使团队能够在跟踪相应大脑活动变化的同时,比对同一图片的短期与较长期记忆表现。
捕捉来自视觉与记忆的详细信号
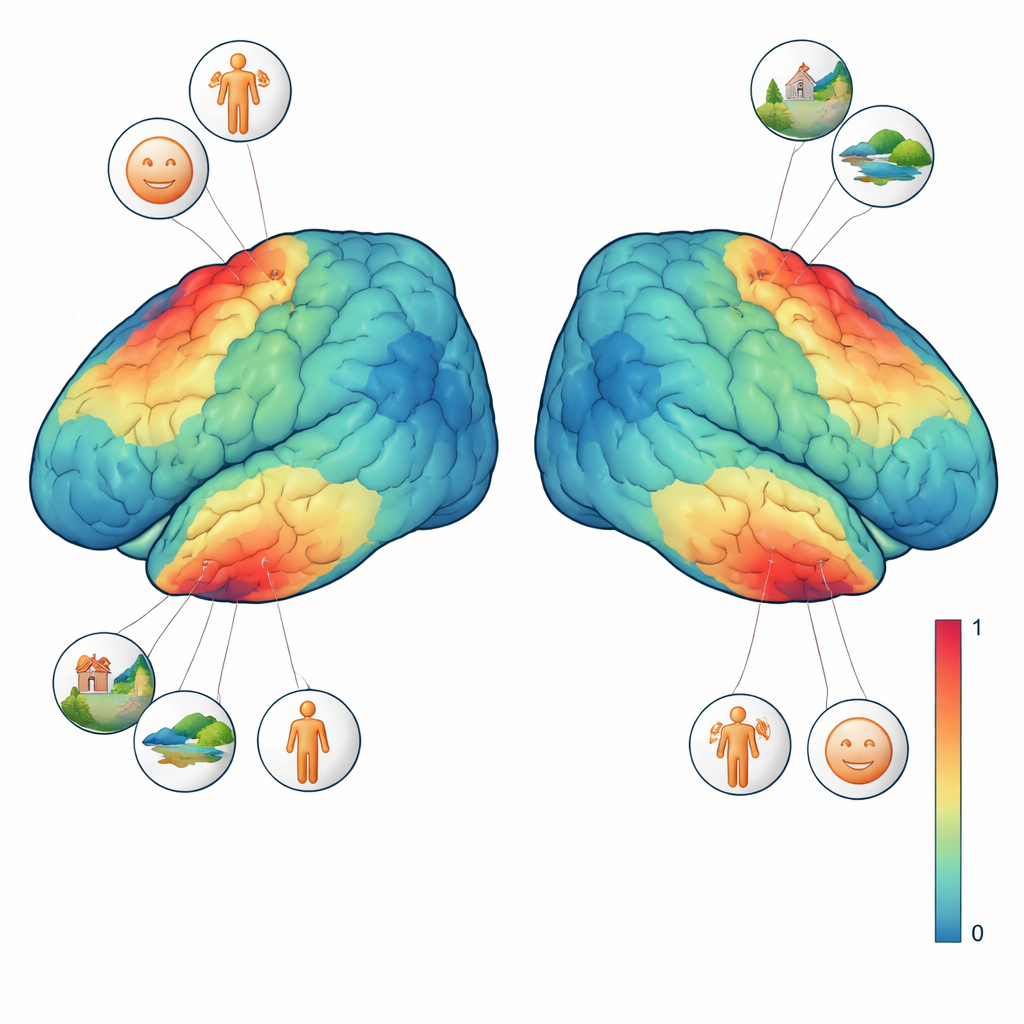
该数据集远不止简单的“开/关”脑活动度量。作者使用先进分析方法,估计每一次试次和每张图片在脑扫描中每个微小三维像素(体素)上的独立反应。他们还使用眼动追踪摄像头记录注视位置,监测呼吸和心率,并测量头部运动。质量检查显示信号极为稳定:参与者几乎每次试次都有回应,注视大多集中在屏幕中心附近,且移动非常小。在关键视觉区域——已知对面孔、身体或场景有强烈反应的区域——每次出现同一图片都会产生高度一致的活动模式。这些模式足够强,以至于当将反应绘制成简化的二维图时,具有相似含义的图像(例如动物或交通工具)倾向于聚集在一起。
绘制大脑不同区域关注的内容
为更好地解读这些信号,四名参与者中的三位完成了额外的视觉测试。在一项测试中,扫掠的形状在纹理背景上移动,以揭示每个大脑区域“看见”视野的哪一部分。在另一项测试中,展示了短段的面孔、场所、身体部位、人物和通用物体,以定位偏好某类图像的区域。将这些定位任务与主要实验结合,研究团队可以提出精确问题,例如:单个体素是在有面孔出现时反应更强,还是在整个场景可见时反应更强?结果显示,面孔选择性区域在任何类型的面孔出现时反应最强,而场景选择性区域则偏好背景丰富的图像(如房间、街道或风景),即使画面中没有人。这些细致的偏好在单张图像甚至单个体素水平上都可观察到。
为更智能的视觉模型奠定基础
本质上,CNeuroMod-THINGS 是一个经过精心策划的公共资源,而非一次性的研究结果。所有脑数据、眼动记录、行为反应、图像注释与分析代码都在开放许可下免费共享。由于相同的四位参与者还在许多其他任务中接受过扫描——观看电影、玩电子游戏、听故事——研究者现在可以构建详细的、针对个体的模型,将受控实验与更自然的体验联系起来。对非专业人士而言,结论是我们现在拥有一个高分辨率的“查找表”,展示真实人类大脑对数千张日常图片的反应。这将帮助科学家检验有关视觉感知与记忆的假设,并指导设计更像人类看世界的人工视觉系统。
引用: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
关键词: 功能性磁共振成像(fMRI), 视觉感知, 物体识别, 脑数据, 记忆