Clear Sky Science · zh
德国人类基因组-表型档案(GHGA)元数据模型在欧洲基因组学领域的语义对齐
为什么共享基因组数据需要的不只是文件
现代医学越来越依赖读取我们的DNA来诊断疾病并定制治疗方案。但基因组学的真正力量在于能将来自多家医院和多个国家的数据合并使用。要做到这一点,必须以清晰、兼容的方式描述每个数据集,并严格遵守像欧洲GDPR这样的隐私法规。本文解释了德国人类基因组-表型档案(GHGA)如何构建一个详尽的“描述体系”,以便在欧洲范围内发现、理解并安全共享有价值的基因组数据。
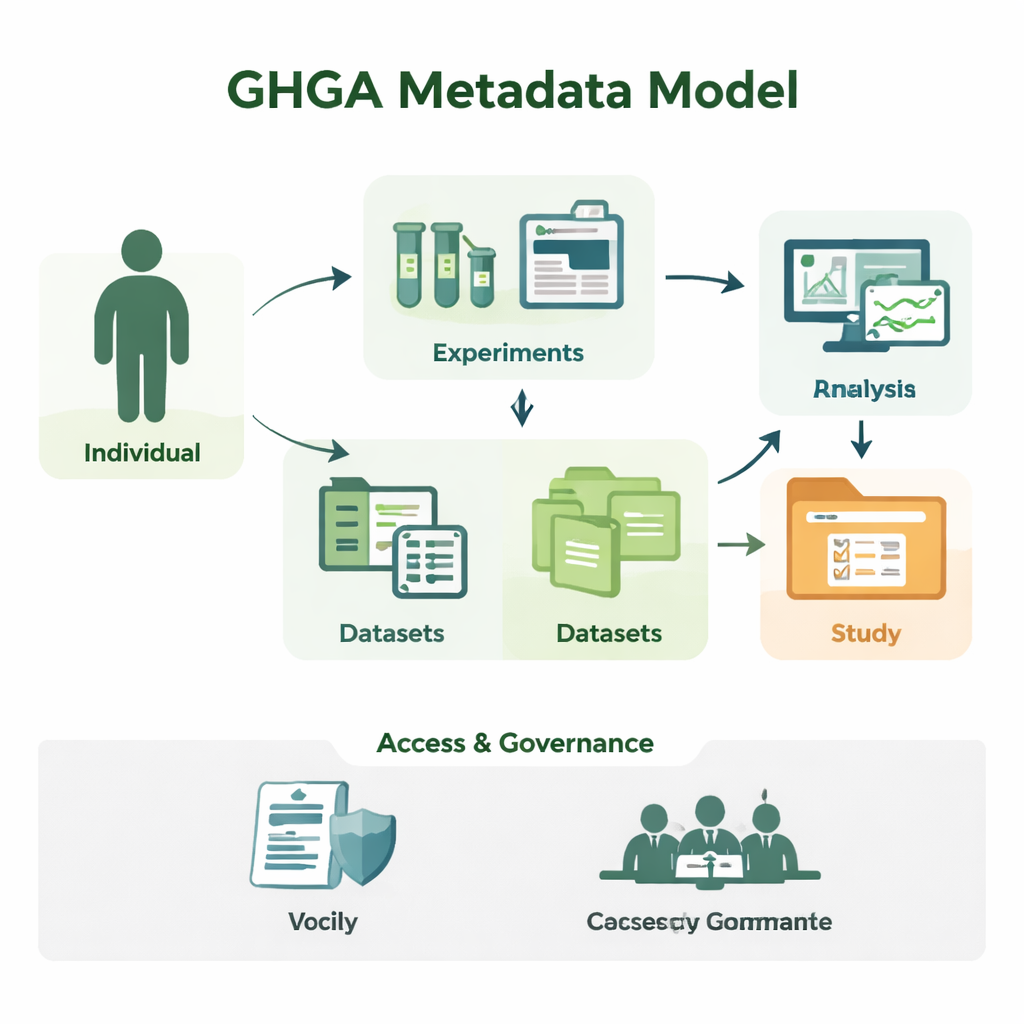
从原始序列到可理解的研究
基因组研究产生大量序列数据,但单独看一份由DNA字母组成的文件没有意义。研究人员需要知道样本来自谁、使用的是哪种组织、实验如何进行以及在何种条件下可重复使用数据。GHGA将这些周边信息作为元数据进行捕获。其模型把元数据组织为16个构建模块,例如参与研究的个体(“Individual”)、采样、执行的实验与分析、生成的数据文件,以及将它们打包的研究和数据集。通过将科学细节与诸如访问条件等管理性信息分离,该模型映射了真实实验室和数据门户的工作方式,但以计算机可可靠处理的形式呈现。
保持数据有用同时使人不可识别
由于GHGA处理敏感的人类健康数据,团队必须在设计模型时保证科学信息丰富,但不易识别数据背后个体。欧洲GDPR规定,任何可以合理地将信息关联回个人的内容都应视为个人数据,即使姓名已被移除。文章描述了一项细致的隐私分析,显示像年龄、邮编和罕见诊断等细节的组合可能揭示身份。作为回应,GHGA的公共门户避免使用精细的地理位置信息,将年龄分为宽泛的区间而非使用确切年份,并将详细的诊断编码合并为更粗的类别。通过这种方式,研究人员仍能判断某个数据集是否与其研究相关,而单独识别某人的难度则变得不切实际。
检验与欧洲基因组生态系统的兼容性
为了真正有用,GHGA的元数据必须融入更广泛的欧洲基因组档案与工具网络。因此,作者逐项将他们的模型与另外四个广泛使用的框架进行比较:两版欧洲基因组-表型档案(EGA)、ISA-tab标准以及荷兰医疗界的FAIR Genomes模型。他们开展了一项详细的“对应表”工作,逐一检查每个GHGA字段在其他模型中是否有等价项,反之亦然。结果发现,GHGA的多数关键属性在其他地方都有明确对应,尤其是在描述研究、样本、实验、分析和文件格式方面。这意味着GHGA的数据集可以与存储在其他欧洲系统中的数据一起被理解和整合。
寻找共同点——以及仍然缺失的内容
通过此次比较,团队提取了25个出现在五个模型中至少三者的“共识”元数据字段。这些字段涵盖了诸如参与者性别与健康状态、使用的组织类型、测序和仪器类型、分析方法、文件格式以及基本研究描述和联系方式等要点。这些共享字段与现有的最低报告指南相一致,可作为任何新建基因组数据门户的核心检查清单。与此同时,分析也揭示了一些模型收集但GHGA目前省略或仅以灵活的自由文本形式接受的信息,例如确切的采样与测序日期、被排除的诊断以及详细的联系人姓名。许多此类省略是为隐私和匿名性做出的刻意权衡。
这对未来健康研究意味着什么
总体而言,研究表明GHGA的元数据模型详尽、灵活并与国际惯例紧密对齐,同时仍遵循严格的欧洲隐私法规。它已覆盖其他档案视为必需的所有字段,并可扩展以支持单细胞与空间组学等新技术。通过提供一种清晰的方式来描述基因组研究涉及的对象与事项、数据如何产生以及在何种条件下可重复使用,GHGA有助于将孤立的数据孤岛转变为互联的研究资源。对患者而言,这提高了他们捐献的数据在未来多年内能安全地为跨境发现和更好治疗做出贡献的可能性。
引用: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
关键词: 基因组数据共享, 元数据标准, 隐私与GDPR, GHGA, 个体化医学