Clear Sky Science · zh
一种可泛化的人脑 MRI 分析基础模型
教计算机读取脑部扫描
磁共振成像(MRI)让医生在无需手术的情况下查看活体大脑,但要理解这些影像仍然在很大程度上依赖人类专家和大量有标签的数据集。本研究提出了 BrainIAC,一种“通用大脑引擎”,它从数万张未标注的脑部扫描中学习,然后可以快速适应多种医学问题——从估计大脑年龄到勾画肿瘤——通常只需少量示例。对患者而言,这类技术最终可能意味着更快的诊断、更好的治疗规划,以及即便在专业能力有限的医院也能使用先进影像工具的机会。
为什么脑部扫描对计算机来说很困难
脑部 MRI 信息丰富但杂乱。单个人可能使用几种不同的设置进行扫描,每种设置突出不同的组织或疾病特征。医院采用各种扫描仪和协议,因此影像在不同地点之间可能差异很大。除此之外,精细的专家标注——例如精确绘制肿瘤边界或跟踪长期生存情况——既昂贵又稀缺。传统的人工智能系统通常针对单一狭窄任务在经过挑选的数据集上训练。当被要求在新的医院、罕见疾病或非专门为其设计的问题上工作时,它们往往表现欠佳。
一个核心模型应对多种脑部任务
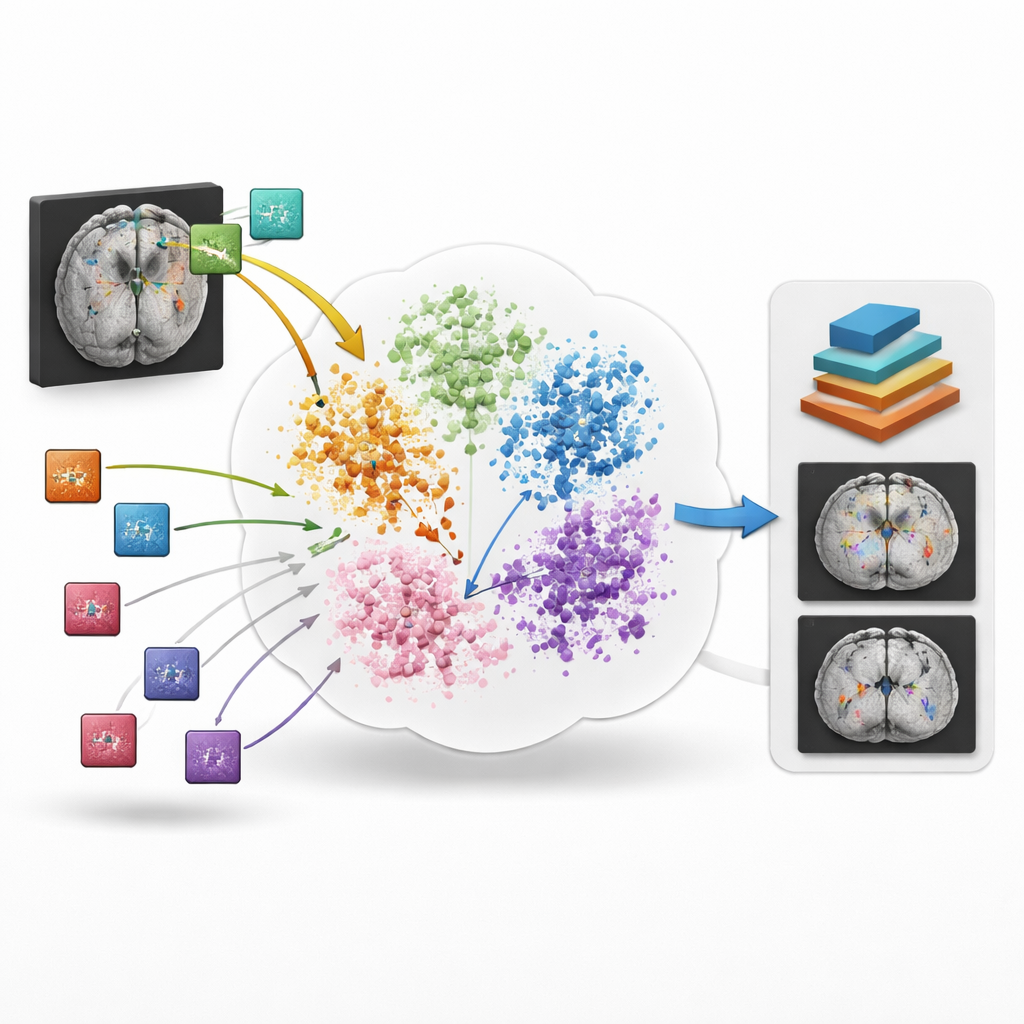
BrainIAC 采用不同路径:它不是一次学一个任务,而是先从 34 个数据集的 32,015 份 MRI 扫描中学习大脑结构和疾病的一般“语言”,这些数据涵盖十种神经疾病,完整数据池接近 49,000 份扫描。该模型以自监督方式训练,意味着不需要人工标签。它观察从整脑扫描中切出的许多小的三维补丁,并学习判断两份经过不同增强处理的补丁是来自同一位置还是来自不同大脑。通过在内部表征空间中将匹配的补丁拉近、将无关的补丁推远,BrainIAC 构建了一种灵活的表示,描述了健康与病变大脑在不同年龄、扫描仪和医院间的常见外观。
将大脑引擎投入使用
一旦学得了这一核心表征,研究人员便在七个具体任务上测试 BrainIAC,这些任务反映了真实的临床问题。包括按 MRI 序列类型对扫描进行分类、估计大脑的表观年龄、预测脑肿瘤是否携带关键基因突变、预测侵袭性肿瘤患者的生存期、将早期记忆问题与正常衰老区分开、估计中风发生的时间以及在影像上勾画肿瘤。对每个任务,他们比较三种策略:从头在该任务上训练模型、使用为其他目的构建的早期医学影像模型作为起点,或微调 BrainIAC 已学得的大脑特征。总体来看,BrainIAC 在各方面要么与替代方法相当,要么表现更好,尤其在标注数据有限时优势明显。
在数据稀缺时也能表现良好
一个重要考验是当有标签的数据极度稀少时系统的表现,这在罕见疾病或昂贵的影像研究中经常发生。团队探索了仅使用常规模型训练数据 10% 的情形,以及更严苛的“少样本”设置——每个类别仅有 1 或 5 个标注示例。在这些紧张条件下,BrainIAC 始终比从头训练的模型或其他可用的基础模型给出更准确的预测。例如,它能更好地区分细微的 MRI 序列类型、更准确地预测肿瘤的基因特征和生存期,并使用更少的注释图像画出更清晰的肿瘤轮廓。该模型在人工加入常见 MRI 伪影(如对比度偏移或与扫描仪相关的畸变)时也表现更稳定,表明它学到了稳健的特征而非脆弱的捷径。
这对患者和临床医生意味着什么
为了评估 BrainIAC 是否关注临床上有意义的区域,作者生成了可视化的“注意力图”,显示模型在做决策时关注的位置。这些图突出了诸如海马体(用于早期记忆问题)、白质区域(用于年龄估计)以及肿瘤核心(用于基因与生存预测)等结构——这些区域与人类专家的直觉一致。因为 BrainIAC 可插入不同的分析管道并能通过最少的额外训练进行适配,它为未来的影像工具提供了灵活的骨干,包括与临床病历或基因数据潜在的结合。
迈向更聪明、更易获取的脑影像
总体而言,研究表明单一、经过精心训练的基础模型可以作为多种脑部 MRI 任务的有力起点,常常优于必须每次从头重建的专用系统。对非专门人士来说,关键要点是 BrainIAC 像一个广泛受过教育的“读脑器”,只需少量示例就能快速掌握新技能。尽管它并不能取代针对性模型或医学判断,但它为使基于影像的高级预测更准确、更稳健、更广泛可用奠定了重要基础,尤其是在难以收集大量标注数据的情形下。
引用: Tak, D., Garomsa, B.A., Zapaishchykova, A. et al. A generalizable foundation model for analysis of human brain MRI. Nat Neurosci 29, 945–956 (2026). https://doi.org/10.1038/s41593-026-02202-6
关键词: 脑部 MRI, 医疗人工智能, 基础模型, 自监督学习, 神经影像学