Clear Sky Science · zh
将大型语言模型作为面向普通公众的医疗助手的可靠性:一项随机预注册研究
为什么你的手机可能不是最佳的第一位“医生”
越来越多的人在感到不适时转向人工智能聊天机器人,期望快速得到是否需要担忧、症状可能意味着什么以及是否该去医院等答案。本研究提出了一个简单却紧迫的问题:如果普通人在家里将强大的语言模型用作医疗助手,他们是否真的能更好地为自己的健康做出决策——还是这种技术会带来虚假的安全感?
用现实风格病例测试智能机器
为此,英国的研究人员设计了十个逼真的医疗故事,例如突发严重头痛或呼吸困难,基于许多人可能会遇到的常见情况。一组经验丰富的医生就每个故事的最佳“下一步”达成一致——从留在家中自我照顾到拨打救护车不等——并列出了一个谨慎的人应考虑的关键病因。随后,从英国各地招募的1,298名成年人被随机分配到四种选项之一:使用三款主流AI聊天机器人中的一种,或使用他们平常会在家依赖的方式,如网页搜索或个人经验。
人类与机器的表现——单独与共同
当对语言模型本身进行测试时,研究者将完整病历描述输入模型并直接询问诊断和建议的行动,它们表现得令人印象深刻。在三款系统中,它们在约95%的病例中至少正确建议了一个相关的医疗状况,并且在超过一半的情况下选择了正确的紧急程度——远好于随机猜测。从纸面上看,这些系统看起来像是能指导焦虑患者的有力候选者。
当AI建议遇到真实的人
但一旦普通用户介入,情况就发生了变化。使用AI的参与者在选择下一步行动的准确性上并不优于对照组,且在识别相关潜在病因方面表现实际上更差。非AI组的参与者识别出正确病因的可能性约为使用聊天机器人的人的1.8倍。所有组的大多数参与者都低估了情况的严重性。换句话说,获得先进语言模型的访问并没有帮助人们更好地理解自己的症状,也没有明显促使他们做出更安全的选择。
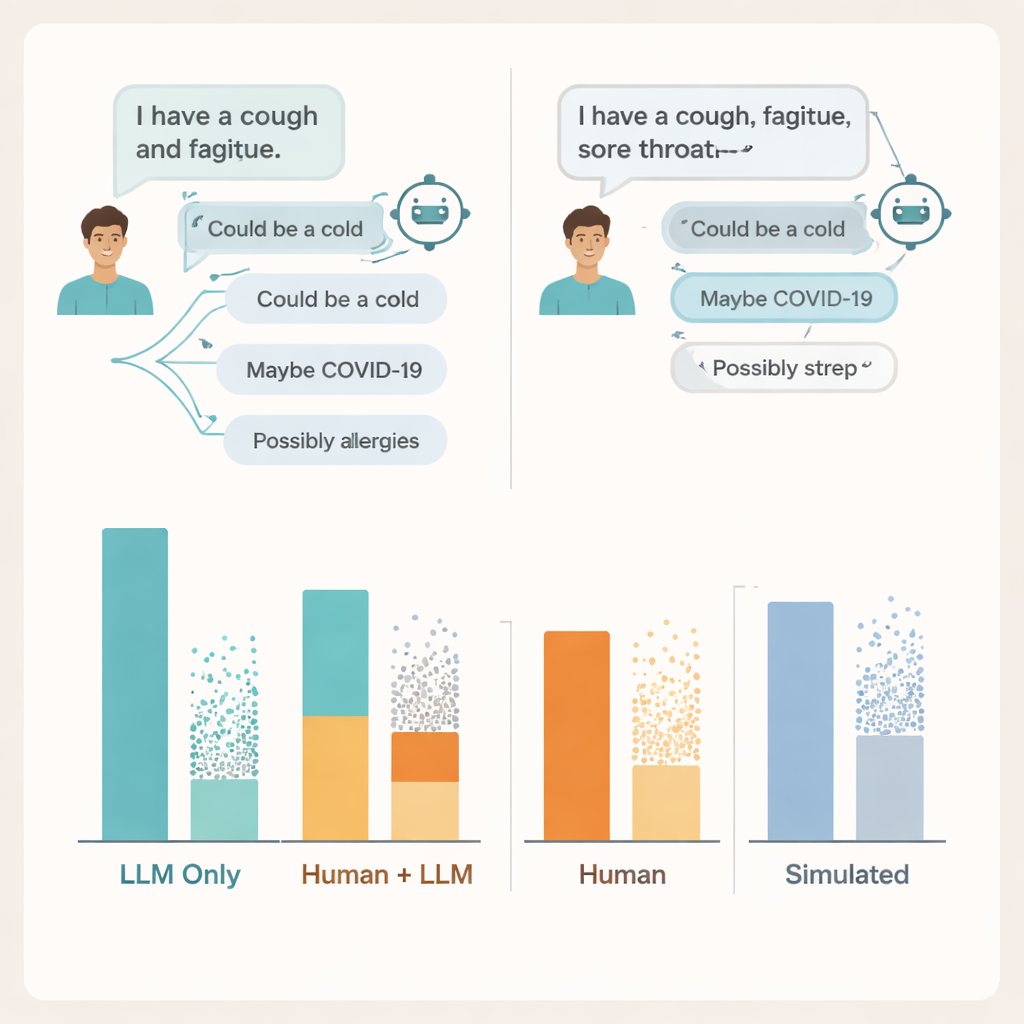
对话崩溃的地方
为了解原因,研究者深入分析了实际的对话记录。他们发现对话双方都有问题。许多用户没有提供足够的症状细节,导致AI无法给出可靠建议——就像病人在与医生交流时有时会遗漏关键信息一样。模型本身常常会提到至少一个相关的病因,但它们也会加入若干不正确或分散注意力的可能性,用户难以判断哪些建议重要。在一些情况下,几乎相同的症状描述会导致同一模型给出截然不同的建议,使人们很难形成何时信任屏幕上信息的明确判断。
为何标准测试忽视了真实风险
团队还将这些结果与两种常用的医疗人工智能评估方法进行了比较:多项选择考试题和由两个模型之间运行的完全模拟“患者”对话。在这两种评估中,系统再次显得很强,达到或超过了考试式问题的典型及格分,并且在与模拟患者对话时表现优于与真实患者。然而,高分的考试成绩和润色过的模拟对话并未与真实人群使用相同工具时的表现相一致。作者认为,那些孤立测试知识的基准未能体现真实人机交互中混乱且脆弱的特性。
这对于患者和医疗系统意味着什么
研究结论是,目前的通用大型语言模型尚不足以作为对公众的无人监管的一线咨询顾问。它们显然包含大量医学知识,但当焦虑的人在家中输入不完整、混乱的问题时,这些知识并不会自动转化为更安全的选择。要让人工智能在像医疗这样高风险的环境中真正有用,需要的不仅仅是更高的考试分数——还需要审慎的设计、与多样化真实用户的测试,以及在对话往来中对信息如何被收集、解释和信任进行更严格的把控。
引用: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
关键词: 医疗聊天机器人, 自我诊断, 医疗人工智能, 患者决策, 大型语言模型