Clear Sky Science · zh
使用检索增强语言模型合成科研文献
为什么跟上科学进展如此艰难
每年都有数百万篇新的科研论文出现在网上。没有任何一位研究者能阅读完全部这些论文,而重要的医疗疗法、气候洞见和技术突破可能就隐藏在这信息洪流中。本文探讨先进的人工智能系统是否能够帮助科学家在这片研究海洋中检索并将其编织成清晰、可信的综述——同时避免虚构内容。
一种新型的研究助理
作者介绍了 OpenScholar,这是一种专为阅读和综合科研文献而构建的人工智能系统。不同于通用聊天机器人,OpenScholar 与一个约4500万篇论文的巨大全开放数据库(称为 OpenScholar DataStore)紧密相连。当科学家提出问题时——例如如何冷却悬浮纳米粒子或哪些方法在大脑成像中效果最好——系统先在该数据库中搜索相关片段,然后撰写带有行内引文的答案,类似人工撰写的综述文章。它会重复这一过程多次,自我批评和改进草稿,以提升表达清晰度、完整性和引文质量。
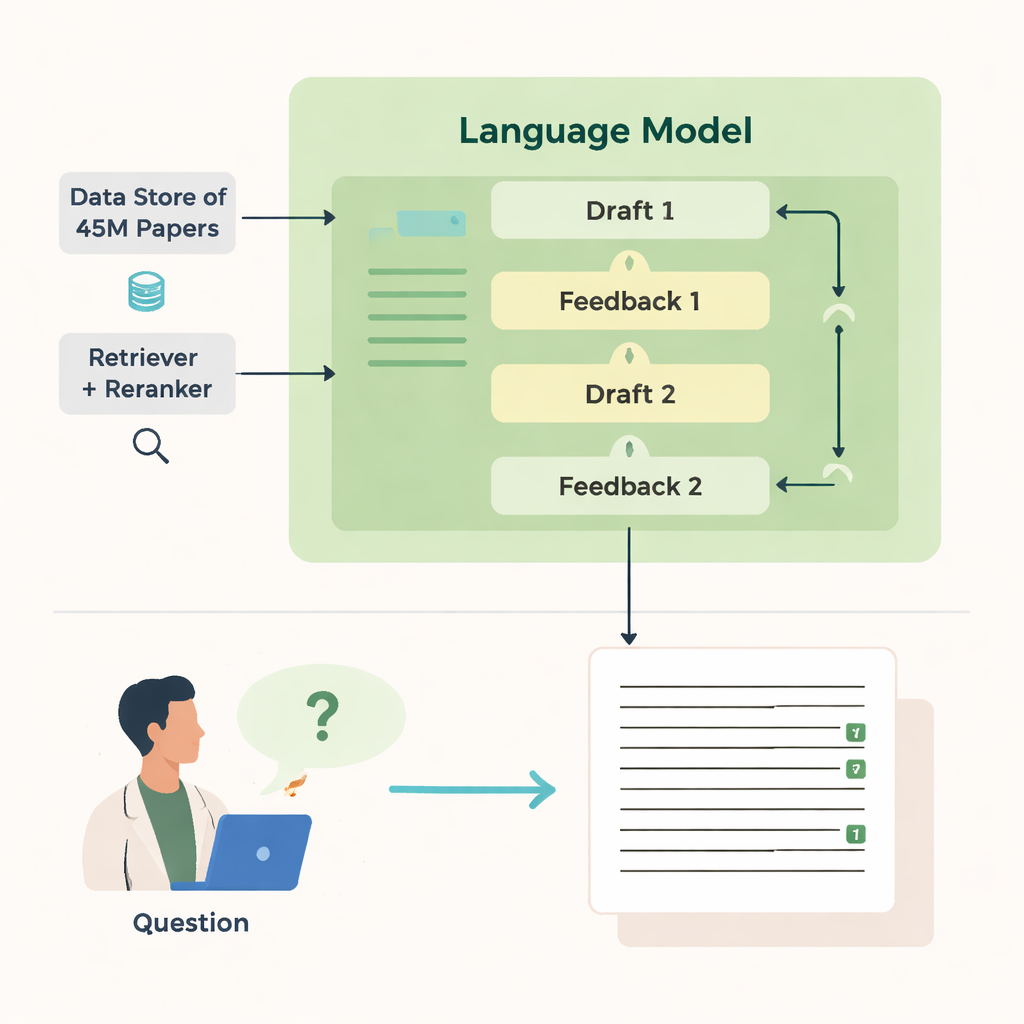
它如何检索与撰写
OpenScholar 的能力来自若干协调工作的组件。一个“检索器”模块扫描数百万篇文章的预先计算文本嵌入,以找到有价值的片段,而一个“重排序器”则重新排列这些片段以聚焦最相关的内容。语言模型随后利用这些证据生成带有编号参考文献的长篇答案。初稿完成后,模型会对自身生成反馈——指出缺失的视角、薄弱的结构或证据不足之处——并在需要时触发更有针对性的检索。随后它改写答案,融入新论文并调整引文。最后一步检查确保那些需要支持的陈述得到至少一条检索到的来源支撑。
检验论断和引文
为了评估 OpenScholar 是否真正有用,作者创建了 ScholarQABench,这是一个旨在模拟真实文献综述问题的大型基准。它包含近3000个专家撰写的问题以及数百个涉及计算机科学、物理学、神经科学和生物医学的长答案。重要的是,这些问题通常需要阅读多篇论文,而不仅仅是一篇摘要。团队在多个维度上评估系统:事实正确性、答案对关键点的覆盖程度、写作清晰度以及引文与原始论文的一致性。他们将自动化检测与来自博士级专家的详细评分结合起来,专家们将 AI 生成的答案与人工写作的答案进行对比。
胜过强大聊天机器人并匹配专家水平
在该基准测试上,OpenScholar 的表现超过了标准语言模型和早期仅在通用聊天机器人上叠加检索功能的工具。一个紧凑的、参数量为 80 亿的版本(完全基于开放数据训练)在要求更高的多篇论文综合任务上,优于 GPT-4o 和一个名为 PaperQA2 的竞争系统,尽管后者依赖更大的专有模型。一个显著发现是常见聊天机器人出现“编造”参考文献的频率非常高:在 78%–90% 的案例中,它们的引文列表包含不存在或不支持相关论断的论文。相比之下,OpenScholar 的引文准确性可与人类专家相比。当专家直接比较答案时,他们大约一半时间更偏好 OpenScholar-8B 的回答,而在基于 GPT-4o 的 OpenScholar 管道中这一比例约为 70%,主要因为该 AI 涵盖了更多相关研究并将其组织得更清晰。
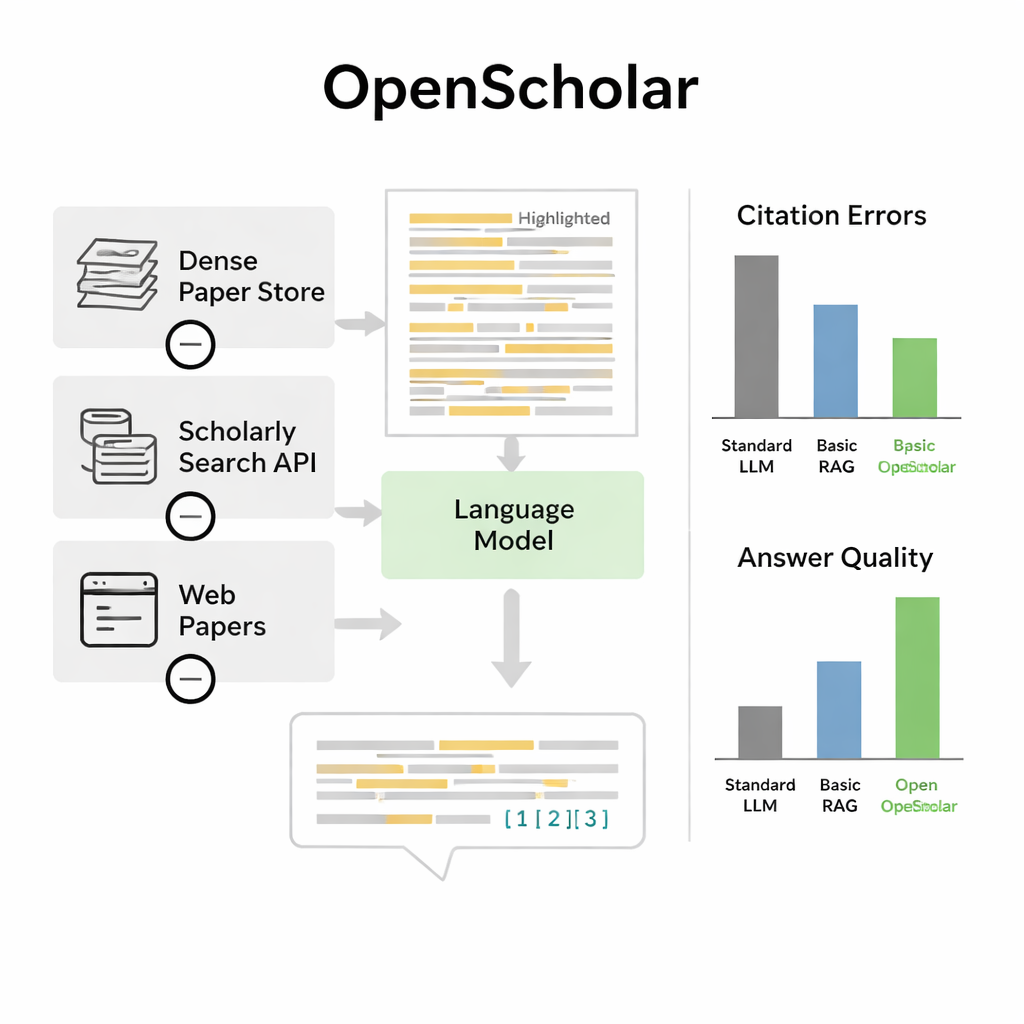
局限与未来改进方向
尽管取得这些进展,作者强调 OpenScholar 并不能取代科学家。该系统仍可能遗漏最具代表性的论文、过度强调次要工作或引入事实性错误,尤其是在更小规模的模型中。该基准本身也有局限:它主要关注计算机科学、生物医学和物理学,而经专家精心注释的问题数量仍相对有限,因为专家时间成本高昂。评估也难以完全捕捉更微妙的品质,例如引文是否突出真正的奠基性工作,或答案是否能够实际指导新的实验。
这对日常科学意味着什么
对非专业人士而言,主要结论是:经过精心设计的 AI 工具在已经能够帮助科学家更高效地导航科研文献,前提是这些工具与真实数据相连并遵循严格的证据与透明性标准。OpenScholar 表明,当一个 AI 系统从头构建以检索、核查并引用真实论文——并且其性能经由人类专家测试时——它能够生成既可读又可验证的文献综述。在实践中,这类工具可让研究者更多地专注于设计实验和解读结果,同时仍让人类掌握判断什么是真实且重要的最终权力。
引用: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
关键词: 科研文献综述, 检索增强语言模型, OpenScholar, 引文准确性, AI 研究工具