Clear Sky Science · zh
由语言模型引导的哺乳动物代谢物的预测与发现
我们体内的隐秘化学
每一滴血液或尿液都包含数以千计的小分子,它们反映了我们的饮食、生活方式以及是否生病。然而对大多数这些分子,科学家并不知道它们的名称或功能。本文介绍了 DeepMet,一种人工智能系统,它“阅读”这些分子的“语言”,并预测哪些分子在我们当前的 人类与动物化学图谱中尚未被记录。通过将实验引向最有前景的候选者,DeepMet 帮助研究者揭示这些化学暗物质,进而更好地理解机体如何运作。
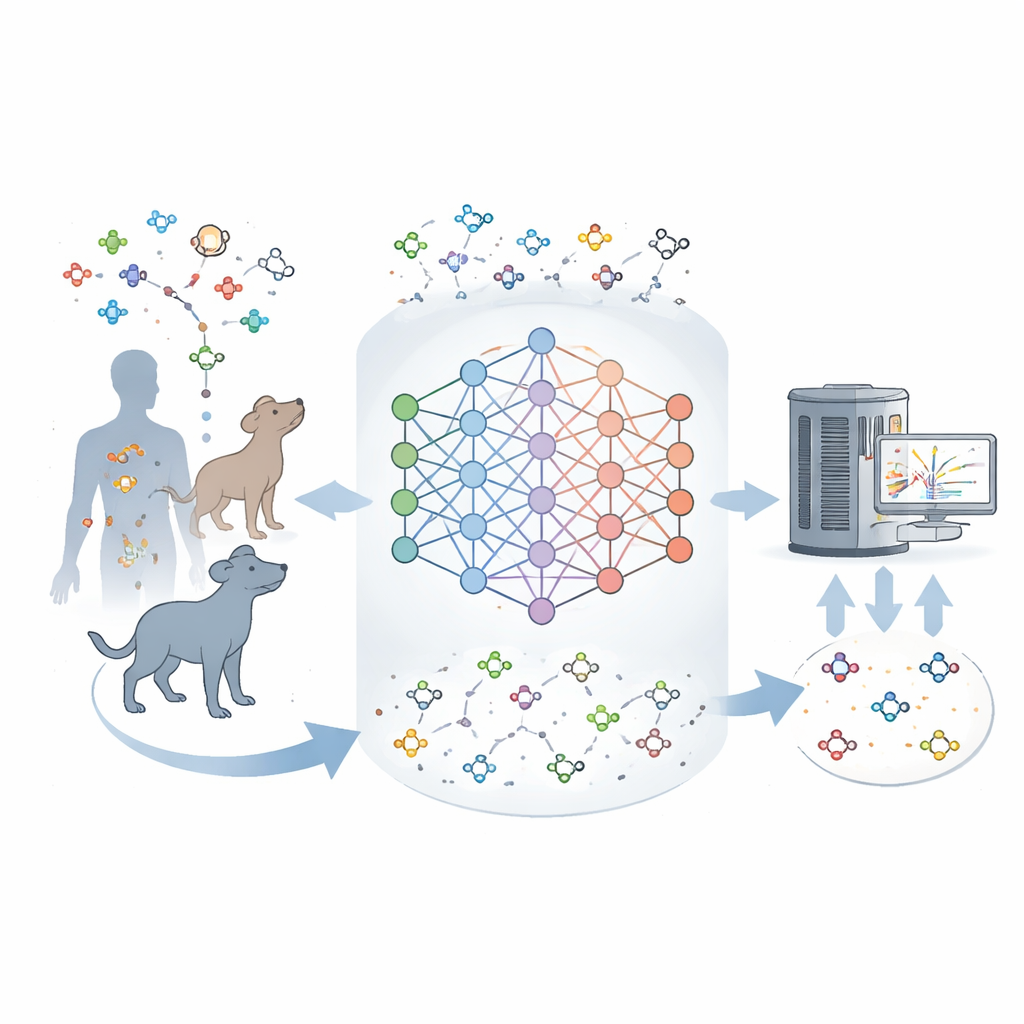
为何如此多分子仍然未知
现代仪器可以同时对组织样本中的数千种分子进行称重和部分指纹化。但将这些指纹转化为精确定结构却很困难。现有数据库列出了许多已知代谢物,然而在真实样本中观测到的大多数信号并未与这些目录中的任何项匹配。这一差距表明当前的代谢图谱并不完整,许多哺乳动物中的天然分子尚未被描述。作者们着手构建一种工具,能够从已知代谢物中学习,然后构想出最有可能缺失的分子,类似语言模型预测句子中可能出现的单词的方式。
教会机器代谢的“语法”
研究团队将一个名为 DeepMet 的神经网络在大约 2000 种确证的人体代谢物上进行训练,将每个代谢物编码为描述其结构的短字符串。在最初对类药物分子进行训练以学习一般化学规则之后,DeepMet 在这套代谢物上进行了微调。当要求它生成新结构时,模型产生的分子分布落在与真实代谢物相同的化学空间区域,甚至再现了许多已知类型的酶促反应,尽管从未被明确告知这些反应规则。换句话说,DeepMet 似乎内化了将糖类、氨基酸等基本构件连接成生物学上现实的小分子的未明文“语法”。
预测哪些新分子很可能存在
研究人员随后从 DeepMet 中抽样生成了十亿个候选分子,并统计每种独特结构出现的频次。重复出现频率高的结构往往更像已知代谢物,与它们共享常见的化学核心并对应合理的酶促转化。为检验这些高频候选是否对应真实分子,团队将 DeepMet 的预测与在模型训练数据截止后被加入人类代谢组数据库的代谢物进行了比较。DeepMet 已经生成了其中大多数后续发现,并将许多列为其最可能的候选。在成千上万的高排名但数据库中缺失的结构中,作者采购或合成了 80 种,并通过质谱在真实人类样本中进行检测。他们确认了若干此前未被识别的代谢物的存在,其中一些即便出现在已有文献中也曾被忽视。
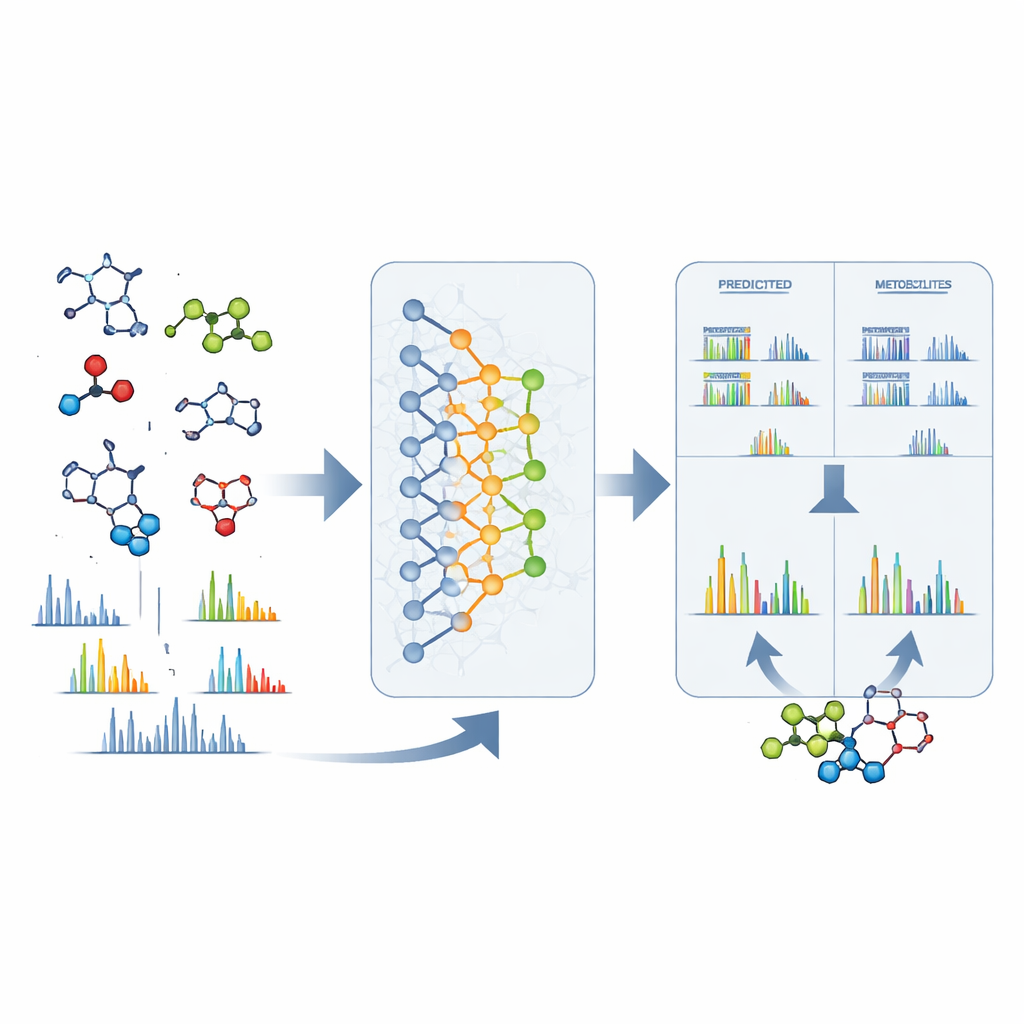
从原始信号到具体结构
当质谱仪观测到未知峰时,DeepMet 也很有用。仅给出一个神秘分子的精确质量,模型就能列出许多可能具有相同质量的结构,并按其“代谢物样”程度对它们进行排序。在近三分之一的测试案例中,正确结构位居首位;在更多情况下,它出现在少数高排名候选中,且通常在形状上与模型首选项非常相似。为进一步缩小范围,作者将 DeepMet 与另一个预测每个候选在质谱中如何碎裂的软件结合使用。将这些预测的碎片模式与实际实验谱图匹配,大致将鉴定准确率提高了一倍。用这种组合方法在大型公共数据集上搜索,得到了许多此前匿名信号的暂定结构,并指出了在疾病、饮食和微生物组状态间存在差异的代谢物。
照亮生命的化学暗物质
通过将从数据中学到的化学直觉与对质谱的强大模式匹配相结合,DeepMet 提供了一条有针对性且实用的新代谢物发现路线图。它尚不能揭示所有未知分子——部分结构与其见过的样本相差太远,某些异构体在没有专门方法的情况下仍然不可区分。但这项研究表明,类语言模型的工具不仅能“发明”逼真的分子,还能预测出生物学家随后在动物和人体中证实的真实化合物。对普通读者而言,结论是人工智能现在可以帮助化学家系统性地揭示我们体内的隐秘化学,可能发现新的生物标志物、追踪饮食–微生物–宿主之间的联系,并逐步把今天的代谢暗物质变成明日的详尽生物学图谱。
引用: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
关键词: 代谢组学, 化学语言模型, DeepMet, 质谱, 代谢暗物质