Clear Sky Science · zh
利用拉曼光谱与化学计量学揭示橄榄油鉴定的关键峰特征
为什么橄榄油造假问题值得关注
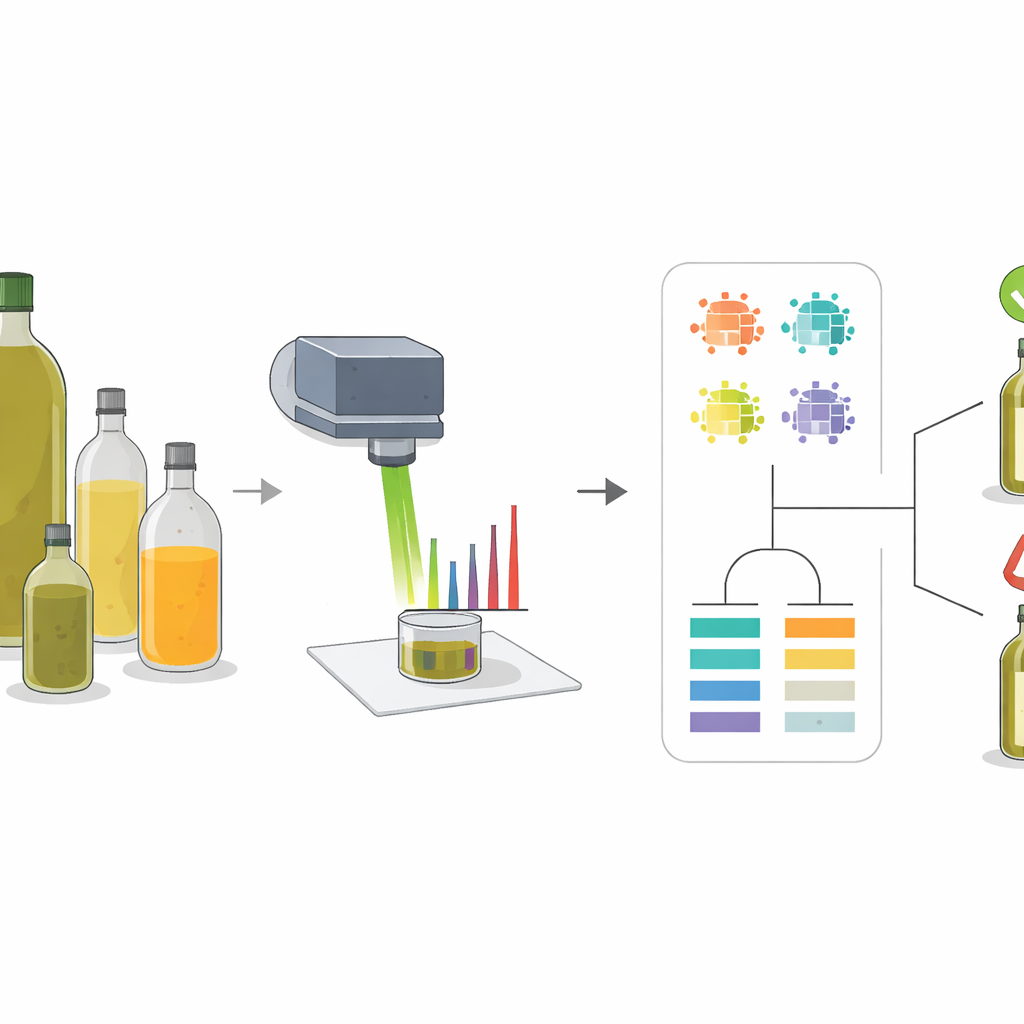
当你为一瓶橄榄油支付溢价时,你期望得到的是真正的橄榄油,而不是偷偷掺入更便宜籽油的混合物。由于橄榄油价值较高且全球贸易复杂,欺诈和标签不实是常见问题。本研究提出了一种快速、无损的方法,通过用激光照射油样并让智能计算程序读取隐藏的化学指纹来识别此类伎俩。该方法旨在通过更容易核验瓶中内容物是否与标签相符,来帮助保护消费者、守法的生产者和监管机构。
用光读取油的指纹
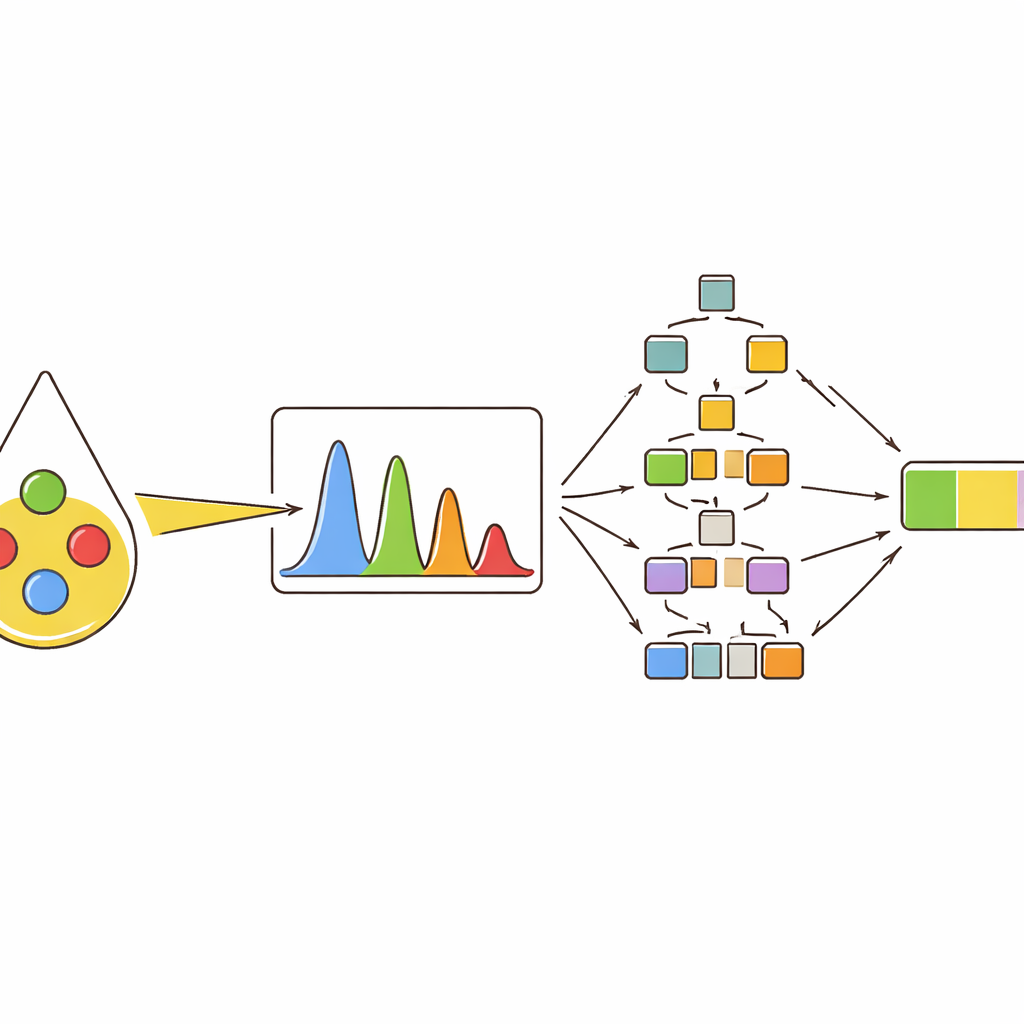
研究人员使用了一种称为拉曼光谱的技术,方法是将一束聚焦光照射到样品上并测量光如何散射回去。不同分子的振动方式各不相同,会在得到的光谱中留下峰值图案,有点像条形码。橄榄油与常见的掺混物(如葵花籽油、菜籽油和玉米油)在脂肪酸组成和天然色素上不同,因此它们的光谱并不相同。通过研究纯油和精心配制的混合物的这些模式,团队能够识别出一小组“关键峰”,这些峰的形状和强度会随着混合物中橄榄油含量的变化而可靠地改变。
寻找最具信息量的信号
团队没有仅依赖单一测量,而是从每个重要峰提取了多个描述量:高度(强度)、所覆盖的面积、中高处的宽度以及与其它峰面积的比较。然后他们使用聚类和相关性图来观察这些描述量如何将不同油类分组,以及在橄榄油含量增加时如何变化。与色素(如β-胡萝卜素)以及特定不饱和脂肪类型相关的峰尤其具有信息性。例如,某些峰在橄榄油比例升高时会变强,而另一些峰则因与亚油酸(在葵花籽油中更丰富)相关而减弱。这种多特征视角捕捉到的微妙差异,若只使用单一强度值将会被忽略。
让算法区分真品与掺假品
为将这些光谱指纹转化为实用决策,作者训练了多种机器学习模型。首先,他们要求模型对十种油类进行分类,包括四种纯油和六种二元与三元混合物。基于树的算法——随机森林和梯度提升树——表现最好,在给定完整峰特征集时几乎将所有样本正确分到相应类别。接着,采用同类模型进行数值预测:估算二元和三元混合物中橄榄油的实际百分比。再次,基于树的方法优于更传统的方法,即便当不同油的光谱信号高度重叠时,也能准确追踪橄榄油含量。
打开智能模型的黑箱
许多强大的机器学习工具难以解释;它们可能效果良好,但很少提供为何做出某一决定的原因。为了解决这一点,研究使用了一种解释方法,为每个输入特征分配对最终预测的贡献值。这显示出少数特定峰主导了模型的判断,且这些峰会根据数值将预测的橄榄油含量一致地推高或压低。在不同的混合类型以及对仅含少量橄榄油的超市商业样品测试中,相同的峰反复出现为最重要的特征。对于这些真实样品,最佳模型对橄榄油含量的估计非常接近真实值,支持了该方法的准确性和透明性。
这对你家瓶装油意味着什么
通俗地说,这项工作表明,经过良好设计且可解释的计算模型解读的快速光学扫描,可以判断一瓶“橄榄油”是纯正、被严重稀释,还是介于两者之间。通过聚焦于少数稳健的光谱特征并在先进但可解释的算法中结合它们,研究人员构建了一个可整合进常规质量检测的工具,甚至可能出现在便携设备中。虽然仍需对更多产区、品种和欺诈类型进行更广泛的测试,但这一框架指向了一个前景:确认像橄榄油这样高价值食品的真实性,将变得更快速、更便捷且更可靠。
引用: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
关键词: 橄榄油鉴定, 食品欺诈检测, 拉曼光谱, 机器学习, 食用油质量