Clear Sky Science · zh
通过文本挖掘辅助的机器学习预测与发射波长的实验验证
将科学文本转化为光
每年,科学家们会发表数以万计关于发光材料的论文——这些材料被用于手机屏幕、医学扫描仪和辐射探测器等设备。埋藏在这些论文中的,是不同材料发射何种颜色的测量数据,但这些信息分散、不一致地写成,并且难以被计算机利用。本研究展示了如何自动读取这些文献,将其转化为大规模且可靠的数据集,然后用机器学习预测新材料将发出何种颜色的光——帮助研究人员更快地设计出更好的荧光体。
为什么发光材料很重要
荧光体是吸收能量并以可见光重新发射的材料。它们是超高清显示、白光 LED、医学成像和辐射探测等技术的核心。工程师希望荧光体发出特定颜色、在高温下保持明亮并尽量减少能量浪费。在过去二十年中,这类材料的研究激增,科研文献中充满了关于化学配方和发射波长的详细报告。然而这些数据大多被锁在非结构化文本中——以段落、图注和实验部分的短语形式出现,写给人类阅读而非计算机处理。 
教会计算机阅读材料论文
作者们构建了一个针对荧光体文献定制的文本挖掘管道。与其使用通用的语言工具,他们设计了能理解化学家实际如何书写配方的规则,尤其是针对“掺杂”材料——即在主体中加入少量另一种元素的情况。他们的系统能够正确识别诸如主体晶格后跟若干掺杂离子及其浓度等复杂名称,并将这些名称与表示发射波长的相邻数值关联起来。系统还处理了棘手的表述,例如句子中写着“它在630 nm发射”但未重复材料名称,或一段中同时提到多种材料和多组波长。通过将每个句子按包含的材料和属性数量分类,然后为每种情形选择匹配算法,该管道大大减少了数值与材料之间的混淆。
从成分到颜色构建干净的映射
将该管道应用于16,659篇期刊文章后,团队提取了约6,400个可靠的“材料—发射”对:包括荧光体的配方、其发射峰波长、单位以及论文的数字标识符。严格的测试显示在识别完整荧光体配方并将其与正确发射值关联方面具有很高的准确性。有了这个结构化的数据集,研究者们将注意力集中在一个尤为重要的家族上:掺Eu²⁺(二价铕)离子的材料,其发射可根据周围晶体环境覆盖可见光谱的广泛区间。他们为每个主体计算了具有物理意义的描述符——如晶体结构细节、键长和电子带隙——并使用特征选择方法将这些描述符缩减到对颜色预测最重要的少数字段。
让机器学习预测发光
接下来,作者训练并比较了若干机器学习模型,以从这些描述符预测发射波长。一种名为 XGBoost 的算法表现最佳,在未见测试数据上达到了约0.91的决定系数(R²)——这强烈表明模型捕捉到了结构与颜色之间的关键关系。为验证该方法在现实中的可行性,他们利用模型提出了若干有前景的Eu²⁺掺杂硫化物和氮化物荧光体,实验室合成了四个候选材料并测量了它们的发射。观测到的波长与预测值仅相差约10纳米,表明模型的“猜测”与实验现实非常接近。 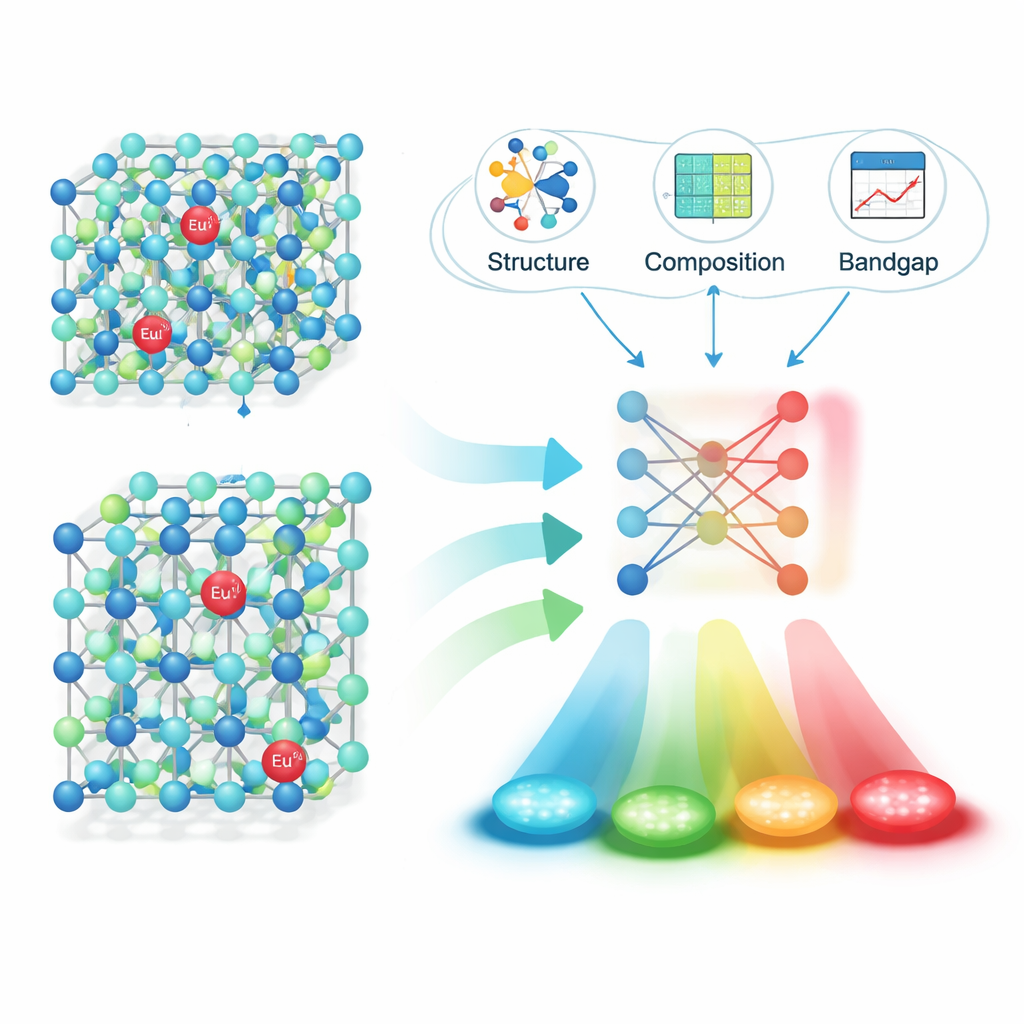
从论文走向实用设计
对于非专业读者,核心信息是这项工作将分散的、由人撰写的论文转化为一个连贯、可检索的图谱,将“材料由什么组成”与“它发出何种颜色”联系起来。通过自动化阅读、组织和学习步骤——然后通过真实实验确认预测——该研究勾勒出一个闭环:文本 → 数据 → 模型 → 新材料。该框架可扩展到亮度、稳定性等其它属性,甚至可用于其它类别的功能材料。由此,它指向了一个未来:科学家们不再依赖大量试错的实验工作,而能快速锁定最有前途的配方,从而加速更好照明、显示和传感技术的开发。
引用: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
关键词: 发光材料, 文本挖掘, 机器学习, 荧光体, 发射波长预测