Clear Sky Science · zh
蛋白质-蛋白质相互作用是遗传相互作用网络中表型互作(表位互作)的主要来源
这对理解基因为何重要
当医生或基因检测告诉我们某个基因“导致”某种疾病时,听起来似乎很直接。但事实上,任一基因的效应常常强烈依赖于其他基因同时在做什么。本文深入探讨了为何基因改变的组合会出现难以预测的行为,并指出很多这些意外可以追溯到这些基因所编码的蛋白在细胞内如何实际相互结合。理解这种联系可以提高我们预测疾病风险的能力,并帮助发现可针对癌症等疾病中薄弱环节的药物靶点。
每个细胞内的两张隐形地图
生物学家使用两类强有力的地图来理解细胞如何工作。一类是遗传相互作用图,展示当两个基因同时受损时细胞会怎样:有时双重改变比预期严重得多,有时则更温和。这种非线性叠加效应称为表位互作(epistasis),它使得仅从DNA预测性状变得困难。第二类是蛋白质-蛋白质相互作用图,绘制哪些蛋白质会物理接触以形成复合物和通路。直到现在,这两张图通常是分开研究的,二者之间的紧密程度尚不清楚。
蛋白结合强度如何塑造基因-基因效应
作者将来自酵母和人类细胞的大规模数据集合并,这些数据同时测量了蛋白质相遇的频率及其结合的强弱。然后,他们在这张物理图景上叠加遗传相互作用数据。一个清晰的模式出现了:那些其蛋白形成强并且平衡良好的复合物的基因对——即两方的丰度相近并大致呈1:1结合——在双基因丢失时往往表现出强烈的负相互作用。通俗地说,单独敲除任一基因会对细胞有一定伤害,但同时失去两者则尤其致命,反映出该共享蛋白复合物的核心作用。相比之下,较弱或更不平衡的蛋白结合则表现出更温和且多样化的遗传效应。
把结合强度转化为网络层面的预测
仅知道哪些蛋白接触并不足够;关键在于这些接触有多紧密。为此,研究者使用定量质谱来估算结合亲和力——蛋白对多容易解离——跨越数千个相互作用。他们发现,随着结合强度增强,相应基因间的平均负遗传相互作用沿着一条平滑的S形曲线变化,这与结合位点随浓度增加而被占据的曲线非常相似。该规律在酵母和人类细胞中都成立。利用这一定量关系,他们展示了可用蛋白结合数据部分重建遗传相互作用网络的结构,从蛋白测量中重新出现了相关基因的簇群。
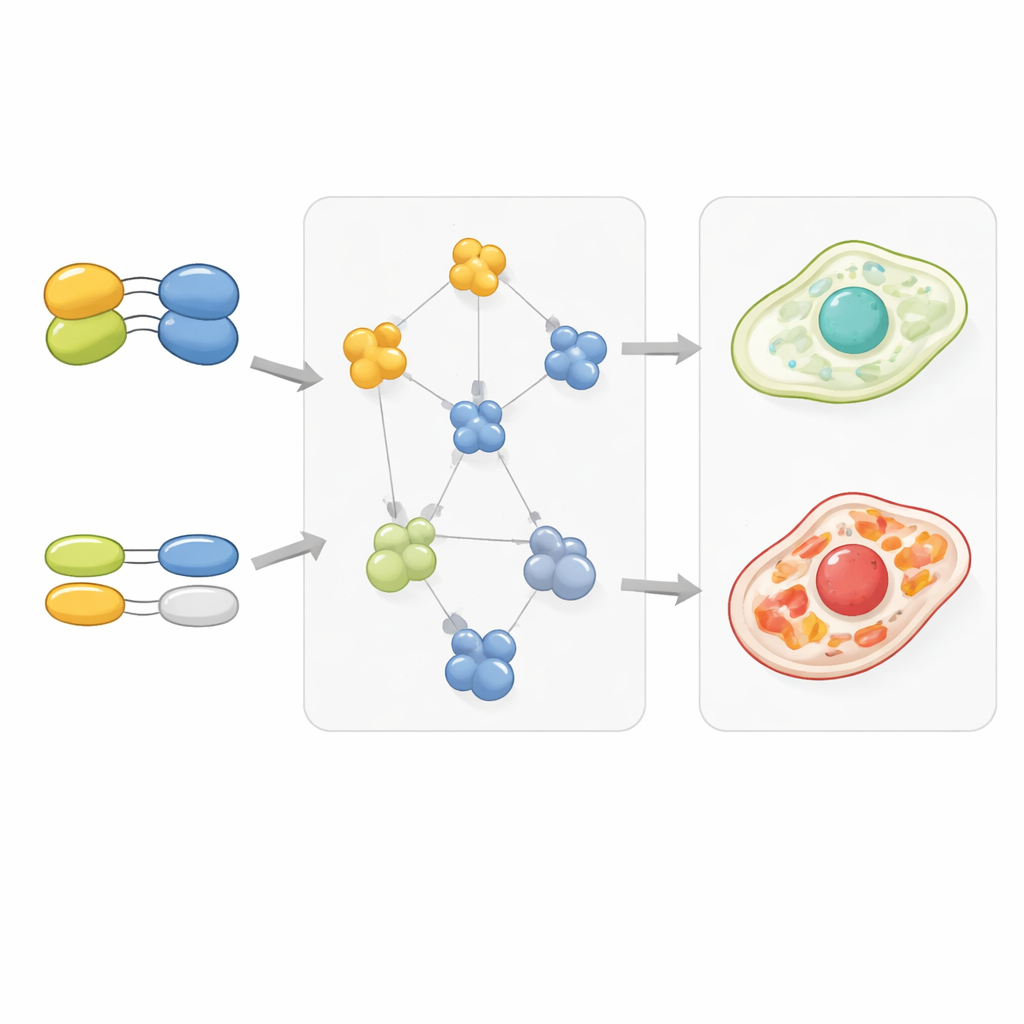
基因重复与细胞布线模式
研究还考察了具有重复基因(称为旁系基因,paralogs)的情况,这类基因常常互为备用。含有一个或两个重复体的基因对往往与其他基因显示较弱的遗传相互作用,提示冗余会减缓失去单个拷贝的影响。显著的是,由重复基因编码的蛋白也倾向于与其伙伴结合得更弱,仿佛进化降低了粘合力以在额外拷贝存在时保持复合物组分的平衡。当重复体在序列和功能上发生更大分化时,通常会出现一份保留强而集中的相互作用,而另一份失去或减弱许多接触,这一模式与这些基因在与细胞其余部分的遗传相互作用中所观察到的变化一致。
将细胞系统连接在一起的共享枢纽
超越个别配对,作者还探问遗传图与蛋白图的宏观形态是否匹配。他们发现,在遗传相互作用数据中聚集在一起的一组基因常常与已知的蛋白复合物高度对应。同样重要的是,相同类型的“连接器”蛋白经常在两张图中桥接这些复合物,形成反复出现的“模块-连接器-模块”模式。例如,穿梭货物通过核孔的转运因子和像Ras这样的信号蛋白在物理网络和遗传网络中都作为共享的连接器,连接着远端的细胞过程。
这对基因、疾病与治疗意味着什么
对非专业读者的核心信息是,许多令人困惑的基因-基因效应并非神秘:它们是因为那些基因所编码的蛋白在物理上相互依赖,而这种依赖的强度是可以测量的。通过将遗传表位互作与蛋白结合的化学性质联系起来,这项工作使我们更接近于预测突变组合如何影响细胞,包括在人类疾病中的影响。从长远看,这样的整合地图可能帮助识别一组基因——当同时作为靶点时——能够选择性地削弱癌细胞,或揭示恢复被扰乱蛋白网络平衡的新方法。
引用: Castellanos-Girouard, X., Serohijos, A.W.R. & Michnick, S.W. Protein-protein interactions are a major source of epistasis in genetic interaction networks. Nat Commun 17, 2398 (2026). https://doi.org/10.1038/s41467-026-69152-2
关键词: 遗传相互作用, 蛋白质网络, 表位互作, 蛋白质复合物, 系统生物学