Clear Sky Science · zh
scLong:一种用于捕捉单细胞转录组学中长程基因上下文的十亿参数基础模型
教计算机读懂细胞的隐秘语言
你体内的每个细胞都像一座繁忙的城市,基因在复杂的模式中开关运作。现代单细胞 RNA 测序能够监听到每个单独细胞的活动,但得到的却是海量且难以消化的数字。本论文介绍了 scLong,一种大规模人工智能模型,旨在理解这些复杂的基因活动模式,包括那些旧方法常常忽略的微弱信号。其目标是帮助研究者弄清在基因被关闭或激活、添加药物或疾病发生时细胞如何响应。
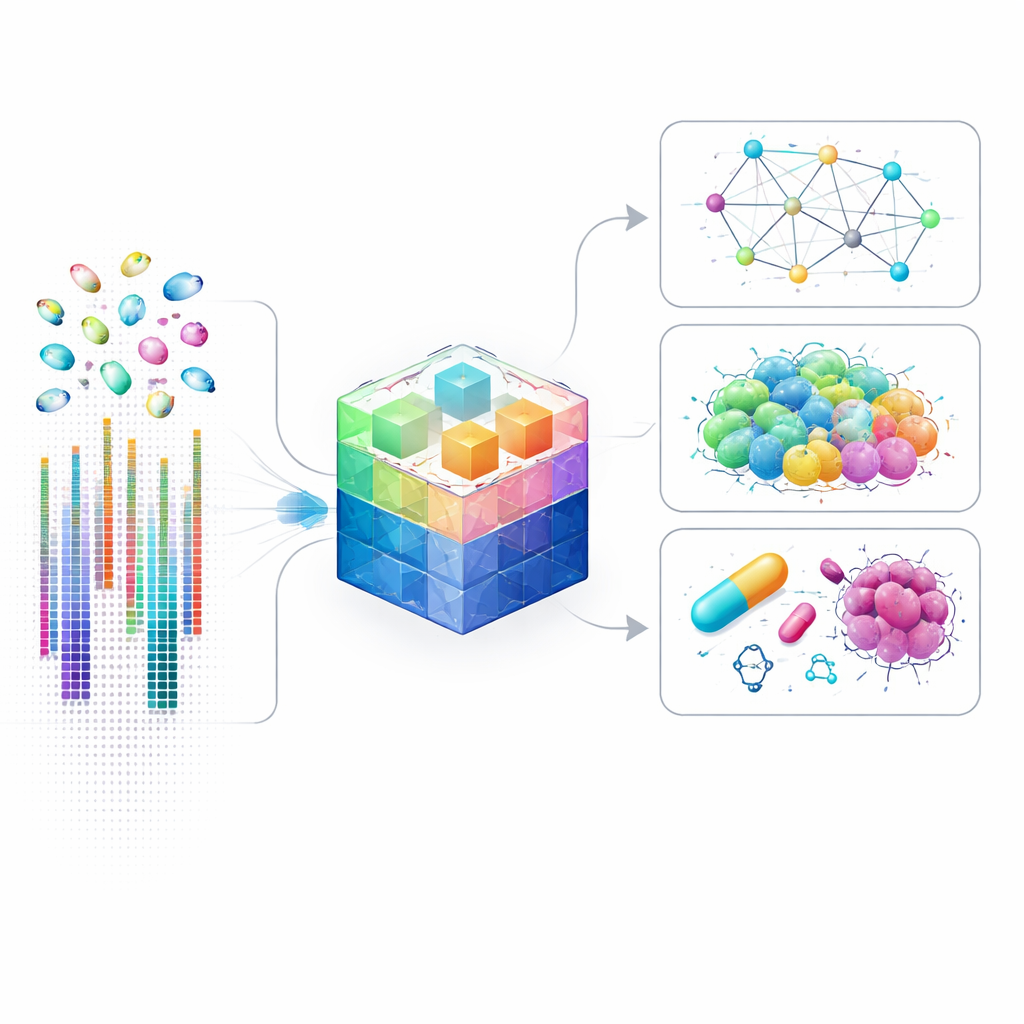
为何细胞级别的基因图谱至关重要
传统的基因研究常常将数百万细胞混合在一起,从而把罕见或异常细胞的信号平均掉。单细胞技术通过分别测量每个细胞的基因活性改变了这一点,揭示了隐藏的细胞类型、细胞间微妙的通信以及决定细胞命运的详细调控回路。然而,分析这类数据极具挑战:每个细胞可能对数万个基因测得活性水平,其中许多基因的表达几乎难以检测。现有的人工智能模型通过只关注最“响亮”的基因来简化问题,这固然加快了计算,但也错过了在疾病、发育或药物反应中可能至关重要的许多微妙信号。
一种倾听每个基因的新模型
scLong 通过扩大规模而不是删减输入来应对这一挑战。它是一个十亿参数级别的基础模型,在约 4800 万个人类细胞的基因活动谱上训练,覆盖 50 多种组织。与早期仅关注几千个高表达基因的方法不同,scLong 同时考虑大约 2.8 万个基因,包括那些罕见或低表达的基因。它为每个基因结合了两类信息:该基因在特定细胞中的活性程度,以及来自基因本体(Gene Ontology)——一个经过专家整理的大规模基因功能与关系目录——的已有功能知识。一个在基因连接图上运行的专门网络将这些先验知识提炼成紧凑表示,以便模型与原始表达值一起使用。
模型如何在能力与效率之间取得平衡
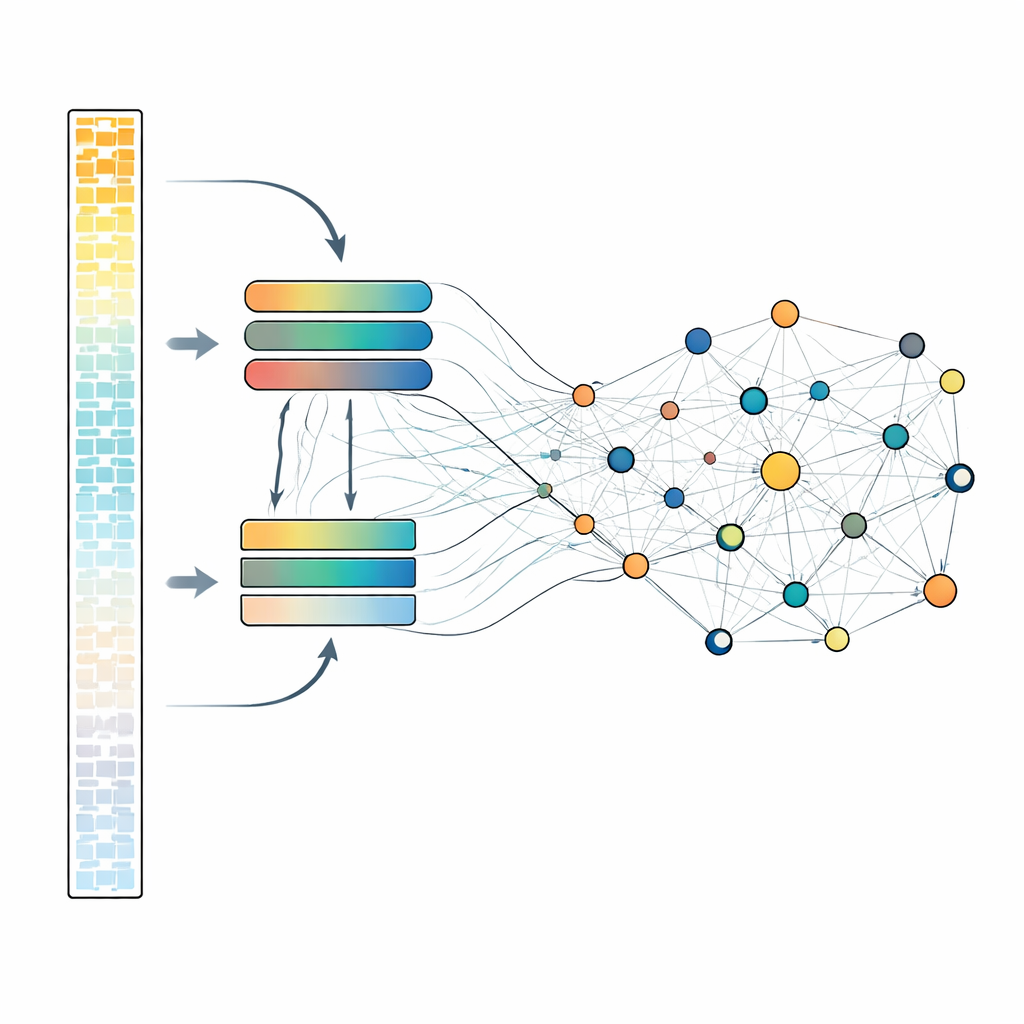
细致地查看每个基因计算代价很高,因此 scLong 采用了巧妙的双路径设计。在每个细胞内部,基因会根据表达强度排序。那些最活跃的基因——通常携带主要生物学信号——由一个更大、更强的注意力模块处理。较为安静的基因,包括低值甚至零值测量,则由一个更小、更轻量的模块处理。随后,所有基因被重新汇合并通过另一个注意力层,使每个基因都能影响其他基因。该设计允许模型为微弱信号保留较为廉价但仍有意义的表示,同时将更多容量分配给最强的信号。在预训练阶段,系统反复屏蔽一部分基因活性值并学习从周围上下文中重构这些值,迫使模型发现连接基因之间的模式。
将模型应用于实际问题
训练完成后,scLong 可用于广泛的生物学问题。作者展示了它可以预测在特定基因被关闭或改变时基因活性如何变化,包括可能协同作用的两基因组合。它还能够预测细胞在暴露于不同化合物时的反应,这对药物发现和安全性测试非常重要。在癌症研究中,scLong 有助于预判肿瘤细胞系对单一药物以及可能更有效的药物组合的反应,常常优于专门化模型和其他大型基础模型。除了预测,scLong 还能推断基因间的调控关系网络,并帮助纠正不同实验室或不同设备采集数据时产生的技术性偏差。
这对未来医学与研究的意义
简而言之,scLong 为科学家提供了一个高分辨率、具有上下文意识的单细胞基因活动图谱,不舍弃那些安静或罕见的基因。通过从数百万细胞中学习并整合现有生物学知识,它能更准确地推测在基因受干扰、新药引入或疾病进展时细胞将如何反应。这可能加速新疗法的发现、指导更个性化的治疗选择,并深化我们对复杂基因网络如何控制健康与疾病的理解。尽管该模型体量大且计算要求高,但它指向了一个未来:强大且通用的人工智能系统将成为探索细胞隐秘机理的多面向助手。
引用: Bai, D., Mo, S., Zhang, R. et al. scLong: a billion-parameter foundation model for capturing long-range gene context in single-cell transcriptomics. Nat Commun 17, 2380 (2026). https://doi.org/10.1038/s41467-026-69102-y
关键词: 单细胞转录组学, 基础模型, 基因调控, 药物反应预测, 基因表达