Clear Sky Science · zh
DNA 钻石提出一种可解构的复合字母星座模型用于 DNA 数据存储
为什么未来的数据可能存放在 DNA 中
我们的手机、公司和科学仪器产生数据的速度远远超过硬盘和磁带的增长速度。DNA——同样是承载生物遗传信息的分子——也可以用来以极其紧凑、持久的形式存储数字文件。本文提出了一种在合成 DNA 链中装入更多信息的新方法,同时保持读取的实用性和可靠性,可能使 DNA 存储更便宜、更易扩展。
从四个 DNA 字母到更丰富的混合体
传统 DNA 存储使用四种天然碱基——A、T、G、C——来表示数字比特,类似于磁盘上的零和一。在这种方案中,DNA 链的每一位最多只能承载两位二进制信息,因为它限于四种选择之一。作者基于一个新兴思想:不是在每个位点放置单一碱基,而是创造受控的碱基混合体,称为复合字母。例如,一个位点可能是 A 和 T 的 50:50 混合,或四种碱基各 25:25:25:25 的混合。当每条链被合成出许多拷贝时,对这些混合物进行测序可以揭示碱基比例,进而对应一个可以表示超过两比特的数字符号。
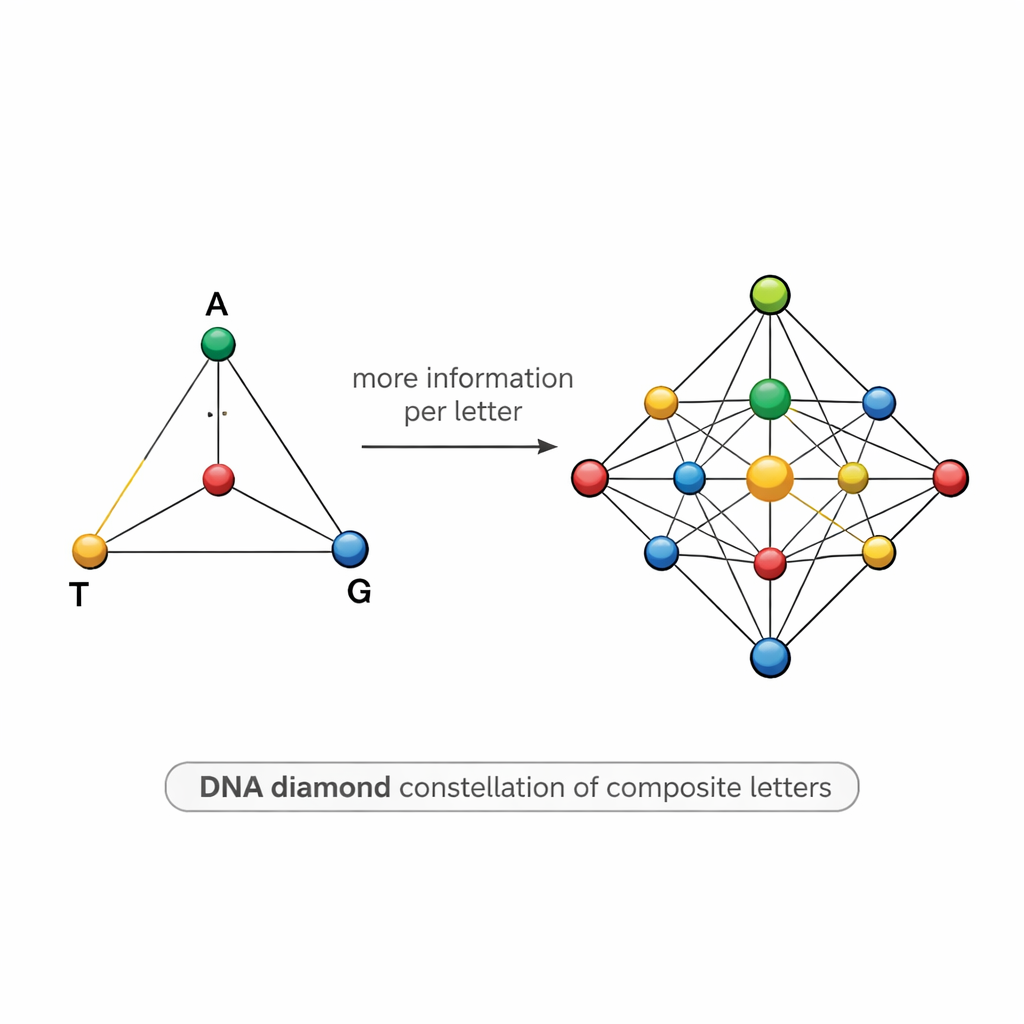
一个菱形映射的 DNA 符号表
设计这样的混合体并不容易。如果两个符号过于相似——比如一个是 50% A 和 50% T,另一个是 55% A 和 45% T——测序噪声可能会将它们模糊,导致错误,并迫使研究者比预期测序更多拷贝。为了解决这个问题,团队提出了一个结构化的“DNA 钻石”模型:一组 15 个复合字母排列成一个四面体的点阵,其顶点为 A、T、G、C。该集合包括位于顶点的纯碱基、位于边上的两种碱基等比混合、位于面的三种碱基混合,以及位于中心的四碱基均匀混合。这个精心选择的星座将理论上的每位信息量提高到约 3.9 比特,同时保持符号之间足够的可区分性以便在实际中识别。
使用熵和索引的更聪明解码
从 DNA 中读取数据意味着要从受噪声影响的碱基频率测量中推断出每个位点意图的复合字母。作者借鉴了电信领域的一种策略,称为集合划分。首先,他们根据一个称为熵的量度来判断一个位点看起来有多“混合”——纯碱基的熵低,复杂混合的熵高。该方法快速将每个位点分配到四类之一:纯碱基、两碱基混合、三碱基混合或四碱基混合。然后,在所选类别内,使用更精确的似然计算来选择最可能的字母。这种两阶段方法减少了符号间的混淆,并在计算时间上比早期方法更省。为了进一步防止不同链之间相互混淆,每段 DNA 在两端携带受保护的索引序列,并在解码前过滤掉因插入或缺失错误导致的错误长度读数。
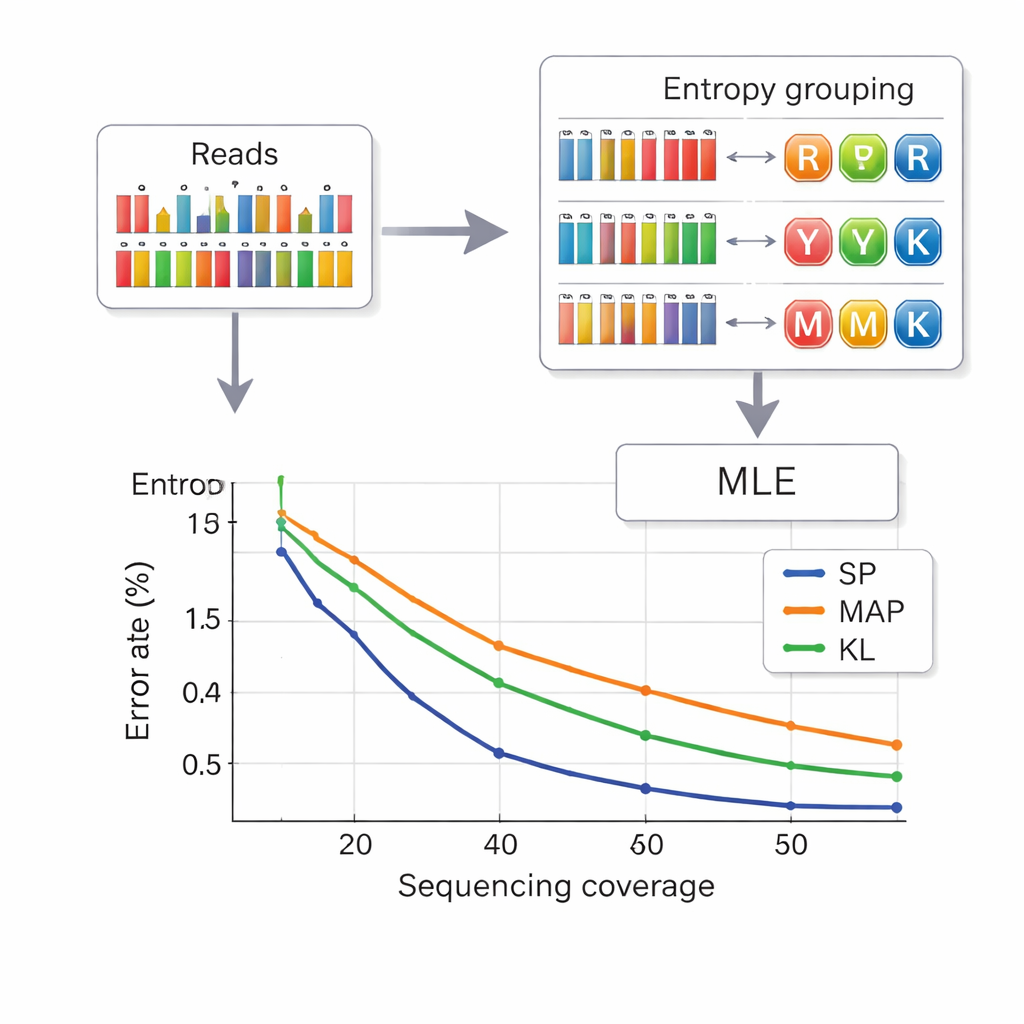
用更少的测序读取装更多数据
研究者在小型和大型 DNA 池中、使用商用合成平台测试了他们的系统。使用八字母复合字母表时,他们实现了每个位点 2.5 比特的有效负载密度,并且在平均每条链 14 次测序读取的覆盖下能够完美恢复文件——相比早期的六字母方案,信息密度更高且所需读取更少。使用完整的 15 字母 DNA 钻石字母表时,他们对主数据实现了每位 3.125 比特,并且在 33 倍覆盖下仍然无误差地恢复了所有内容。模拟与实验证明,他们基于熵的方法表现几乎可与最准确但更慢的解码方法相媲美,并且明显优于旧技术,尤其在较低测序深度下表现更佳。
这对未来存储意味着什么
对普通读者来说,核心信息是:作者找到了一种在不发明新化学方法的情况下,让 DNA“学会新把戏”的途径:通过巧妙地混合现有的四种碱基并更智能地解码,它们可以在每个分子上存储更多比特,同时控制成本。其菱形字母表结合稳健的索引与纠错表明,高容量的 DNA 数据存储在相对适度的测序努力下是可行的。随着 DNA 合成与测序持续降价,这类设计可能有助于将 DNA 从实验室的好奇心转变为归档世界数字记忆的现实介质。
引用: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
关键词: DNA 数据存储, 复合字母, 信息密度, 纠错, 数字存档