Clear Sky Science · zh
BiG-SCAPE 2.0 和 BiG-SLiCE 2.0:可扩展、准确且交互式的代谢基因簇序列聚类
微生物基因组中的隐秘化学宝藏
我们依赖的许多药物和作物保护剂来自微生物合成的小分子。这些生物将合成这些分子的“配方”藏在被称为基因簇的DNA片段中。随着DNA测序技术飞速发展,研究者面临的数据洪流让人应接不暇,但对微生物能产生的化合物我们仍只知少部分。本文介绍了 BiG-SCAPE 2.0 和 BiG-SLiCE 2.0 这两款升级软件,帮助科学家从庞大的基因组档案中筛选、比对和组织这些隐秘的“分子工厂”,将下一代抗生素和农业用化合物的发现推近一步。
基因簇为何对健康与农业至关重要
微生物通过特定的小分子进行竞争、通讯和环境适应。负责合成或降解这些分子的DNA蓝图常常聚集在代谢基因簇中。这包括构建复杂天然产物的生物合成基因簇,以及使微生物能够利用特定化合物或根系分泌物的分解代谢基因簇。由于簇内基因协同工作,在基因组中发现这样的区域就像发现一个独立的“生产线”,能提示该分子的结构和功能。现有的基因组挖掘工具已经可以在细菌和真菌中检测到这些生产线,但真正的挑战是比较成千上万个基因簇以了解它们之间的关系及其潜在的化学多样性。
用于整理分子工厂的两大引擎
BiG-SCAPE 与 BiG-SLiCE 最初被设计用来将具有相似核心特征的基因簇分组为“基因簇家族”。每个家族预计会产生相同或密切相关的分子。BiG-SCAPE 构建了细致的簇间相似性网络,而 BiG-SLiCE 则侧重速度,通过将基因簇转为简单的数值指纹然后对这些指纹进行聚类,从而能够处理数百万个簇。二者共同支撑着日益增长的基因组挖掘管线、数据库和交互式查看器,帮助研究者在行星级别上导航微生物化学世界。
BiG-SCAPE 2.0 的新进展
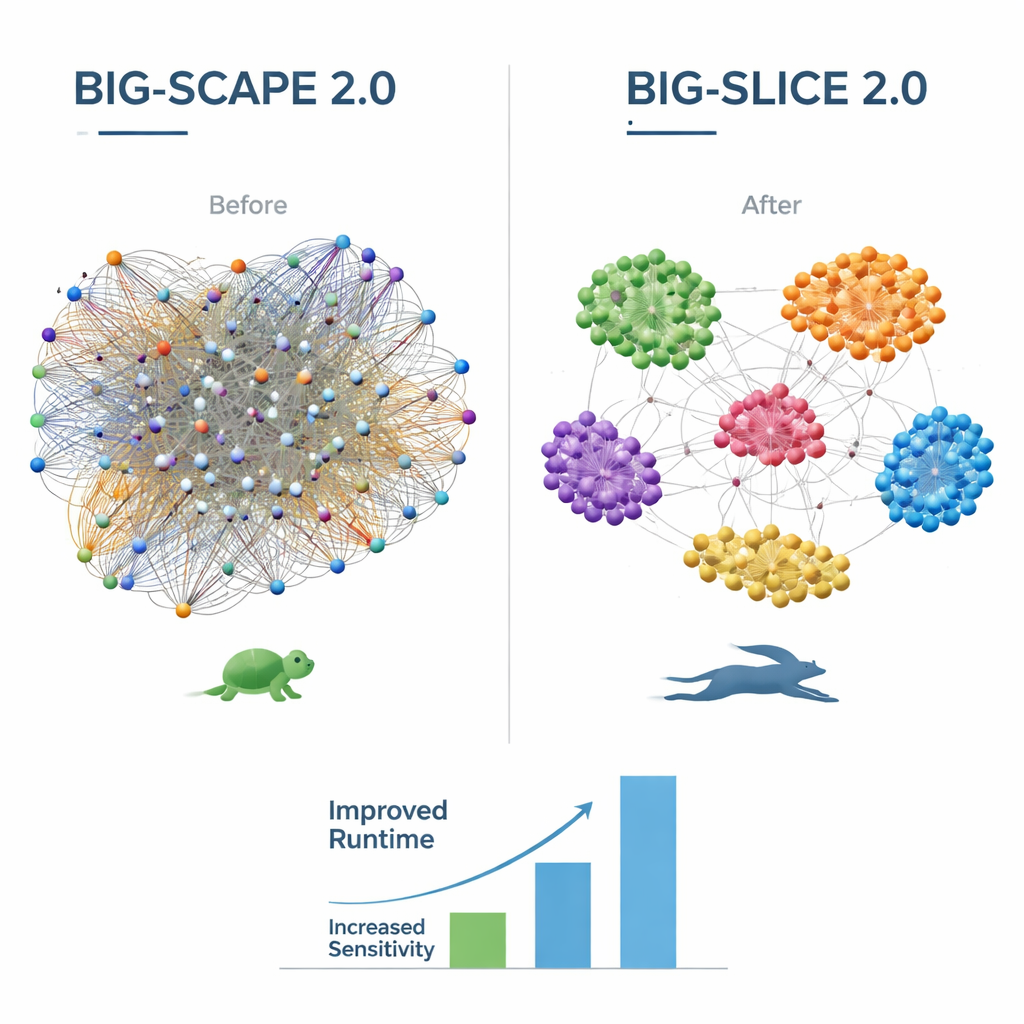
BiG-SCAPE 2.0 在生物学和计算层面引入了一系列升级。它现在支持广泛采用的 antiSMASH 工具中更细化的“region”概念,该概念将重叠或混合的基因簇拆分为更小且更有意义的构建单元(称为 protoclusters)。新的比对模式和策略使 BiG-SCAPE 2.0 能聚焦于每个簇中真正重要的核心基因,更好地应对基因重排和模糊的簇边界。底层代码已全面重写以提升速度和可维护性,采用共享的 SQLite 数据库和现代的轮廓搜索(profile-search)Python 库。因此,BiG-SCAPE 2.0 的运行速度可比前一版本快达八倍,内存占用约减半,并通过升级的交互式网页版界面提供多种现成工作流程,用于聚类、查询、去重和基准测试基因簇。
BiG-SLiCE 2.0 如何应对数据暴增
BiG-SLiCE 2.0 专注于在保持其标志性速度的同时提升超大规模分析的准确性。早期版本对所有基因簇类型一视同仁,这在无意中使某些家族获得了偏好。通过切换到类余弦的距离度量并将其生物合成蛋白特征库更新到最新标准,BiG-SLiCE 2.0 现在能更均衡地分组非常不同类型的簇。代码优化以及向与 BiG-SCAPE 相同的快速轮廓搜索库的迁移带来了额外的加速,新的选项可将所有结果导出为简单的文本表,便于将 BiG-SLiCE 嵌入其他分析管线。与九个手工策划的基因家族数据集的测试表明,BiG-SLiCE 2.0 的准确性已经接近 BiG-SCAPE,尤其是在较短且更难检测的基因簇上。
揭示广袤且未被开发的化学宇宙
作者使用这两款工具分析了来自公共微生物基因组数据库的 260,630 个生物合成 region。BiG-SCAPE 2.0 与 BiG-SLiCE 2.0 在该数据集中对不同基因簇家族数量的估计非常相似,支持了早期研究的结论:到目前为止,仅约 3% 的细菌基因组中编码的生物合成潜力被表征过。换言之,绝大多数微生物合成的化学物质仍然未知。通过使研究者能够在数十万乃至最终数百万基因组上准确聚类并可视化基因簇,BiG-SCAPE 2.0 与 BiG-SLiCE 2.0 为探索这一未知的化学宇宙提供了强有力的视角,为新药物、更安全的作物防护工具以及更深入理解微生物如何塑造生态系统与我们自身健康铺平了道路。
引用: Draisma, A., Loureiro, C., Louwen, N.L.L. et al. BiG-SCAPE 2.0 and BiG-SLiCE 2.0: scalable, accurate and interactive sequence clustering of metabolic gene clusters. Nat Commun 17, 2000 (2026). https://doi.org/10.1038/s41467-026-68733-5
关键词: 生物合成基因簇, 天然产物发现, 基因组挖掘, 微生物代谢物, 计算聚类