Clear Sky Science · zh
为超紧凑光学计算而逆向设计的纳米光子神经网络加速器
为什么微缩光学计算很重要
现代人工智能运行在庞大的电子硬件上,消耗大量能量并产生大量热量。该研究探索了一条截然不同的路径:在芯片上使用微小的光学结构,而非电子流,来执行神经网络的部分计算。作者表明,通过在纳米尺度上“雕刻”光,他们可以构建超紧凑的光学加速器,这些加速器能够识别手写数字和医学图像,其占用空间远小于当今电子设备,并且原则上能耗也要低得多。
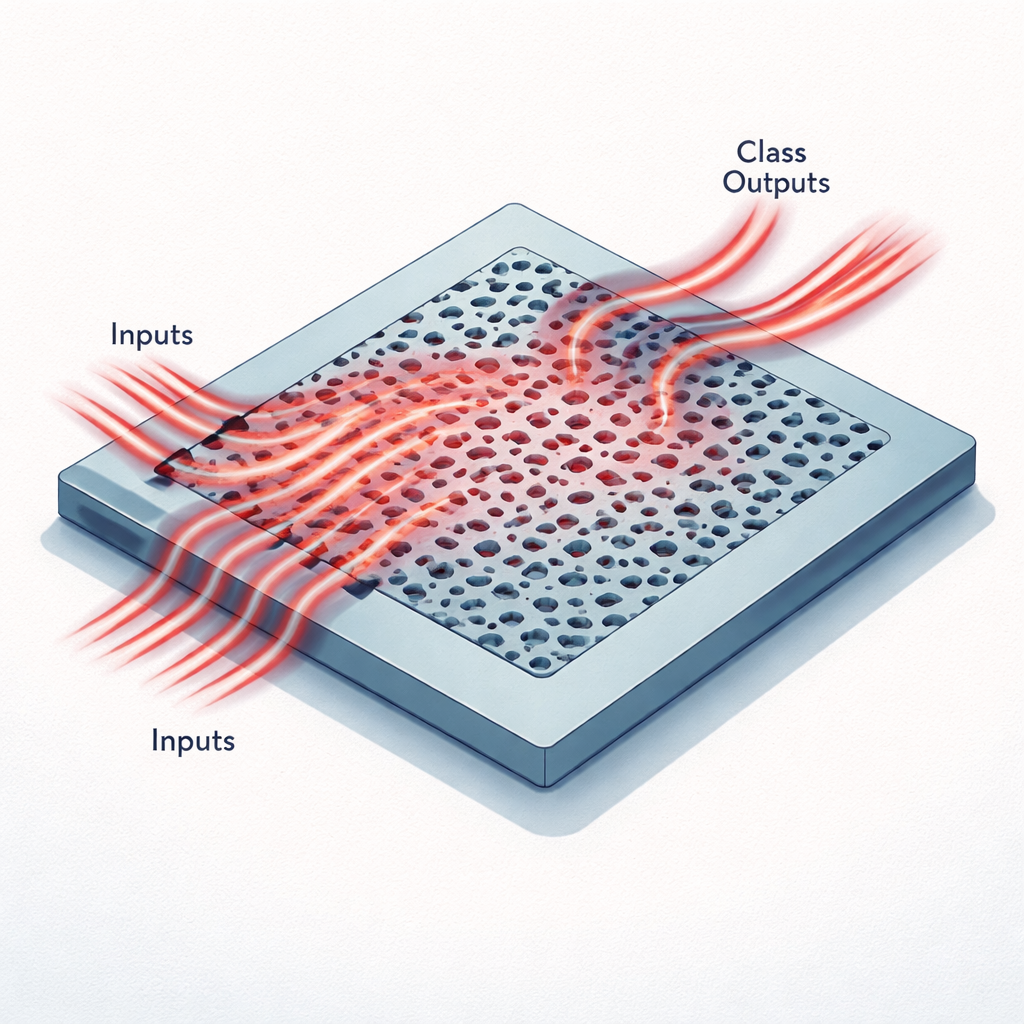
用光思考的微型芯片
这些加速器不是用导线和晶体管构成,而是用一块平坦的硅,上面刻有比红外光波长更小的孔洞和通道。图像数据首先被压缩为一小组数字,然后以单一电信波长将这些数字编码为进入若干窄波导的光强。随着光进入图案化区域,它被散射、自相干并被重新导向到少数输出波导。每个输出对应一个可能的类别,例如 MNIST 数据集中十个数字中的一个,或医学图像集合 MedNIST 中的六个类别之一。输出处的光功率分布起到与数字神经网络最后一层相同的作用。
让算法绘制光学蓝图
手工设计这样的结构几乎不可能,因为材料的每一个微小“体素”都会改变光的传播。研究人员采用了逆向设计方法:他们从随机的硅和玻璃图案开始,在三维中模拟光如何传播,然后调整图案以减小衡量分类错误的损失函数。他们利用麦克斯韦方程的线性特性——控制光的基本定律——来提高训练效率。与其为每张训练图像分别模拟,不如每个输入通道仅模拟一次,再将这些预计算场以线性组合的方式重构用于所有图像。一种称为伴随方法的数学技术随后提供精确的梯度,告诉算法如何微调每个体素以提升性能。

砂粒大小的紧凑图像分类器
采用该策略,团队在标准的绝缘体上硅(silicon‑on‑insulator)平台上设计了两种纳米光子神经网络加速器。其中一种面积仅 20×20 微米,用于对 MNIST 的手写数字进行分类;另一种为 30×20 微米,用于对 MedNIST 的医学图像进行分类。在仿真中,这些微型器件分别达到了 97.8% 和 99.1% 的准确率。按相同设计制作的实物芯片在真实激光器和探测器测试中对 MNIST 达到 89% 的准确率,对 MedNIST 达到 90%——考虑到芯片的微小尺寸,这些数字相当惊人。光学结构将大约 160,000 到 240,000 个可训练参数装入比尘粒更小的区域,相当于每平方毫米约 4 亿个参数。
为速度、效率与可扩展性而建
由于这些器件是被动的——在推理过程中没有可移动部件或可重编程元件——它们在制造完成后不需要持续调节。神经网络的“权重”被硬编码进纳米结构的几何形状中,因此计算以光速进行,基本实现了就地存储处理:光携带编码数据进入,出来时已混合成类别得分。该训练方法也被设计为可扩展的。每次优化步骤只需要固定数量的全物理仿真,这个数量由输入和输出通道的数量决定,而非数据集大小,而且这些仿真可以分布在多个图形处理单元上。作者还概述了如何将多个此类光学核心叠层,中间放置光电探测器,类似深度神经网络中的层,以及如何通过波长或时间复用来提高吞吐量。
对未来 AI 硬件的意义
简而言之,这项工作表明可以“生长”出定制的玻璃和硅结构,使其在微小面积内表现得像专用的神经网络层——足够小的面积上可以在单个芯片上容纳数百或数千个此类结构。尽管完整的光学计算机仍在未来,但这些逆向设计的纳米光子加速器可以将 AI 工作负载中最耗能的部分从电子处理器上卸载出去。如果与快速调制器、探测器和巧妙的系统设计结合,它们指向一种紧凑、低功耗的硬件前景,在这种前景下,光而非仅仅是电流,将承担机器学习中的大量繁重工作。
引用: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
关键词: 光子神经网络, 纳米光子学, 光学计算, 硬件加速器, 逆向设计