Clear Sky Science · zh
在不存在与利用权衡的情况下对人类探索的相互竞争的认知压力
即使没有利害关系,我们为何仍会探索
想象一下浏览餐厅评论或在一个城市里漫步:你在探索,但你的点击或步伐并不会立即让你获得或失去什么。本研究探讨在这种低风险情境下我们的好奇心表现如何,以及它是否不同于在每次选择都带来收益或代价时的探索方式。通过在精心控制的实验中剥离即时奖励,作者揭示了决策过程中两类信息寻求之间隐藏的拉扯。
把奖励变成颜色
大多数实验室关于探索的研究使用类似赌博的游戏,每个选择都会产生成绩或金钱。这使得难以判断人们是真正出于好奇,还是仅仅在追逐回报。在这里,研究人员设计了一项新任务,将“奖励”仅设为颜色深浅,而不是点数。在每次试验中,志愿者在两个抽象形状之间做出选择,每个形状对应一个袋子,产出大多偏蓝或大多偏橙的结果。重要的是,看到一种颜色并不会立即给或扣钱;它只是揭示该选项背后的统计模式,就像了解一台老虎机的行为倾向一样。 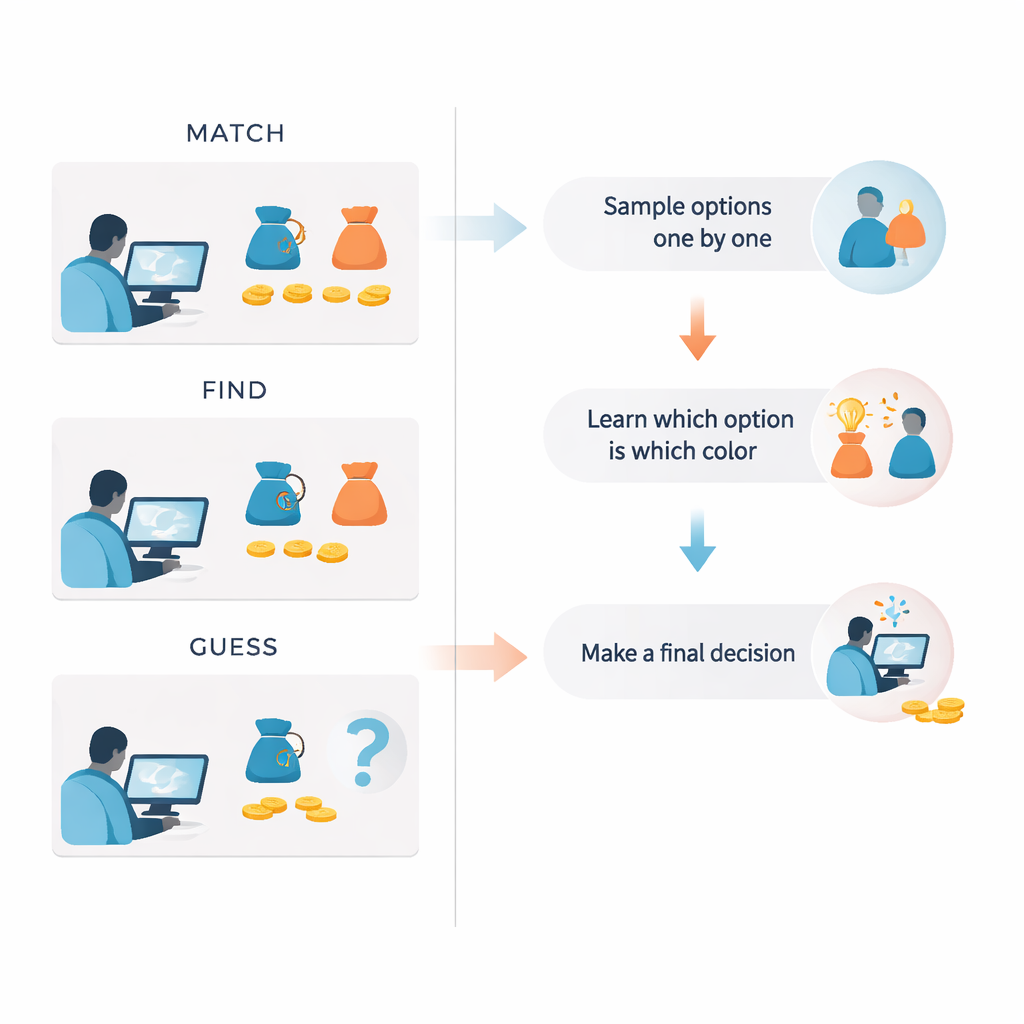
用三种方式问同一个问题
巧妙之处在于保持抽样体验不变,仅更改说明和奖励出现的时机。在 MATCH 条件下,告诉参与者去收集目标颜色,每出现更接近目标色的结果就立即获得积分,模仿经典的“探索—利用”困境。在 GUESS 条件下,抽样期间没有目标;只有在序列末尾才要求参与者判断哪个选项大多为蓝色或橙色,且只根据最后的回答付费。FIND 条件介于两者之间:从一开始就知道目标颜色,但奖励仍仅取决于单次最终选择。跨越若干独立组别,团队发现所有条件下的表现均显著高于随机水平,确认参与者学会了颜色与选项的配对关系。
分块与追逐不确定性
当探索不与即时奖励竞争时,人们的行为呈现出令人惊讶的有结构性。在 GUESS 条件下,他们在每个新序列开始时会连续多次抽样同一选项,仿佛想先对该选项形成稳固的第一印象。只有在这个反复选择的“分块”之后,他们才会切换,并在序列后期开始偏好当前更不确定的选项。作者将第一种倾向称为局部不确定性最小化:减少对当前正在接触选项的疑虑。后者称为全局不确定性最小化:有意抽样你总体上最不了解的选项。相比之下,在 MATCH 条件下,每个结果都有明确价值,人们很快倾向于与目标颜色最匹配的选项,并表现出很少的初始分块模式。 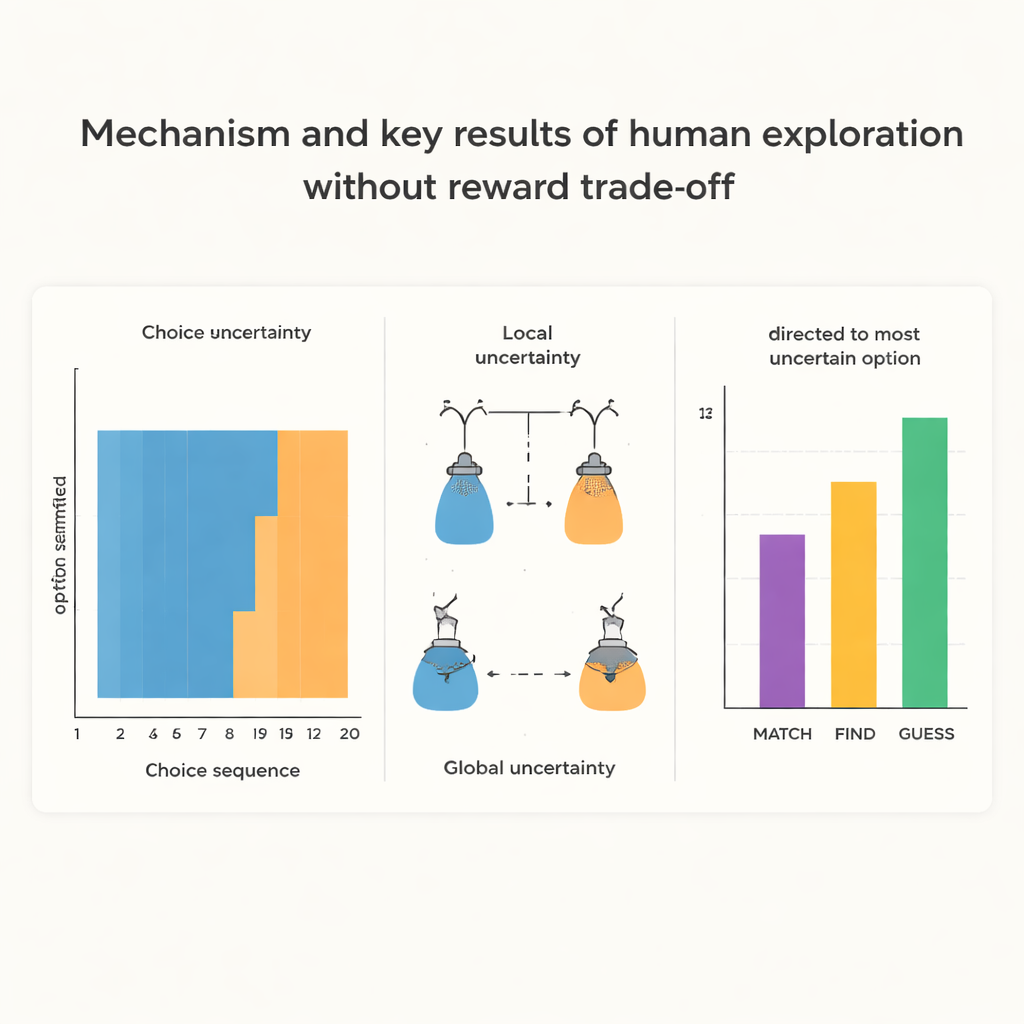
用计算模型剖析机制
为了更深入理解这些模式,研究人员构建了从观察到的颜色历史预测选择的数学模型。一个不考虑认知成本的“最优”抽样者会始终选择最不确定的选项,以尽可能高效地获取信息。人类参与者并未像这个理想主体那样行事。模型拟合显示,除在奖励延迟时有适度追逐不确定性的倾向外,人们存在显著的重复先前选择的偏好,并且在许多情况下会持续重复,直到对该选项达到个人的信心阈值。有趣的是,早期分块更强的个体往往在后期也表现出更多有针对性的探索并总体表现更好,这表明这种看似次优的策略在考虑人类认知限制时可能实际上是一种有用的折衷。
这对日常好奇心意味着什么
这些发现表明,当我们在不担心即时回报的情况下探索时,两种力量塑造着我们的好奇心。一种促使我们停留在当前正在检视的事物上,以确保真正理解它;另一种则推动我们去了解总体上最不清楚的内容。在现实生活中,浏览评论、熟悉一座新城市或试用新工具,很可能反映了局部与全局信息寻求之间的同样平衡。该研究表明,如果我们只在重奖励的任务中研究探索,就有可能误解人们出于知识本身而自然寻求信息的方式。
引用: Alméras, C., Chambon, V. & Wyart, V. Competing cognitive pressures on human exploration in the absence of trade-off with exploitation. Nat Commun 17, 883 (2026). https://doi.org/10.1038/s41467-026-68639-2
关键词: 人类探索, 决策, 不确定性, 信息寻求, 认知建模