Clear Sky Science · zh
用于非负矩阵分解的片内模拟计算
为何将大数据拆分成部分很重要
日常服务比如电影推荐、照片应用和基因分析,都依赖于在巨大的数字表格中发现隐藏的模式。一个常用的方法称为非负矩阵分解(NMF),它把大数据表拆成更简单、易于解释的构建块。但是随着数据集扩展到数百万的用户、条目或像素,现有的数字芯片在实时处理方面会吃力。本文展示了一种基于模拟片内计算的方法,能够以更快的速度和更低的能耗完成这些繁重的数学运算,为更灵敏、更高效的 AI 驱动服务打开了大门。
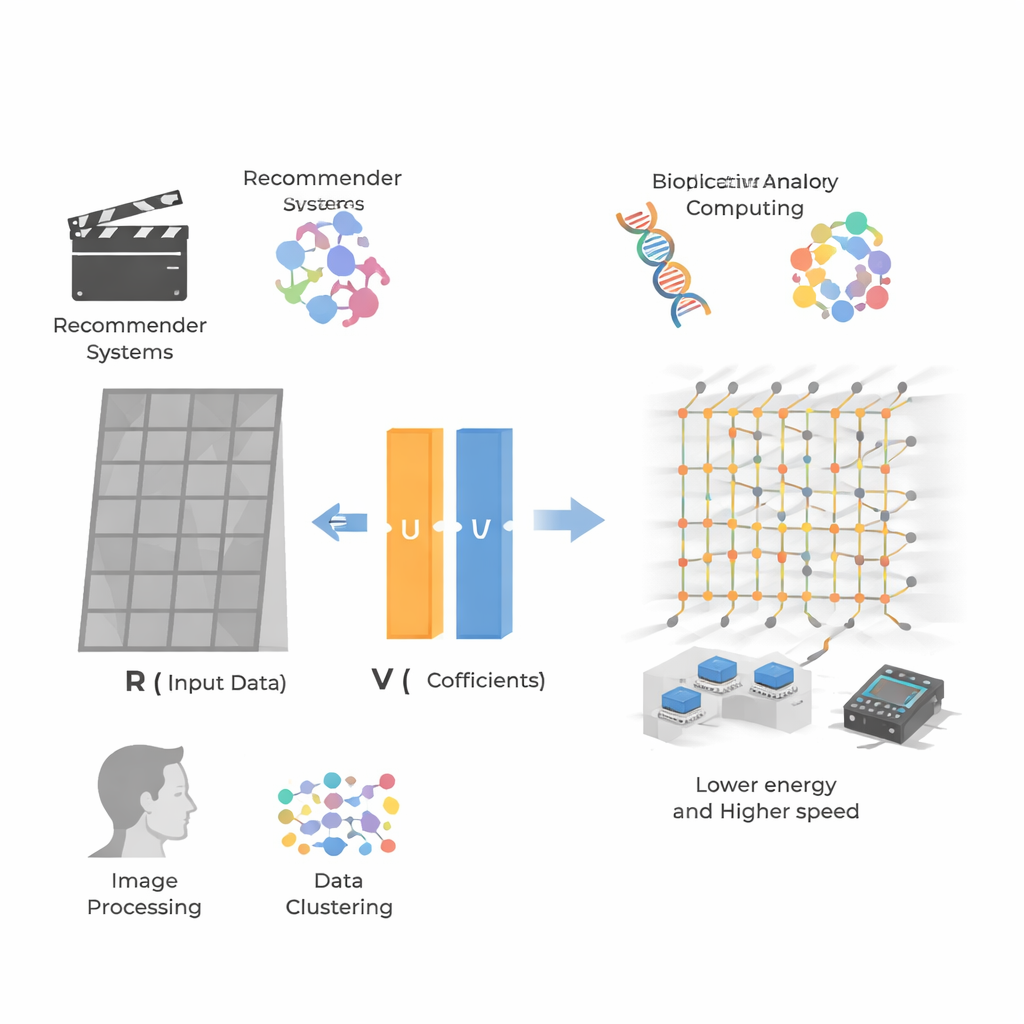
从巨型表中提取模式
这项工作的核心是非负矩阵分解(NMF),该方法将一个大的非负数网格——例如用户对电影的评分或图像的像素值——重新表示为两个较小网格的乘积。一个网格表示隐藏的“特征”(例如用户偏好动作片还是爱情片),另一个表示每个条目或像素在这些特征上的强度。由于所有数值都保持非负,这些特征往往呈现直观的“部件”形式:图像中的面部组件,或推荐数据中的偏好谱。这使得 NMF 在推荐系统、生物信息学、图像处理和聚类中很受欢迎,但对于非常大且稀疏的数据集来说,它也带来了很高的计算需求。
为何数字芯片会遇到瓶颈
传统处理器——CPU、GPU 甚至 FPGA——将矩阵运算视为一系列基本步骤,频繁在存储器和计算单元之间移动数据。对于中等规模的问题这能良好运行,但对于具有数百万行和列的现代数据集,时间和能耗成本会变得极其庞大。摩尔定律的放缓以及所谓的冯·诺伊曼瓶颈——内存访问主导功耗和延时——使得在实时应用中扩展 NMF 变得越来越困难,例如在线推荐或快速图像分析。即使是巧妙的数字算法,只要矩阵需要反复更新,依然面临多项式时间复杂度和大量内存流量的问题。
用模拟信号在存储中计算
作者采用不同路径,使用基于阻变存储器(忆阻器)的模拟矩阵计算。这些器件可以排列成高密度的交叉阵列,每个结点存储一个电导值。当在阵列一侧施加电压时,从另一侧流出的电流天然地并行执行大量的乘加运算。通过将这些阵列与少量运算放大器连成闭环,团队构建了一个紧凑的广义逆(GINV)电路,能够在本质上一个模拟步骤中解决整个回归问题,而不是经过许多数值迭代。他们通过电导补偿方案改进设计,使电路保持稳定的同时大幅减少运算放大器数量,从而节省芯片面积和功耗。
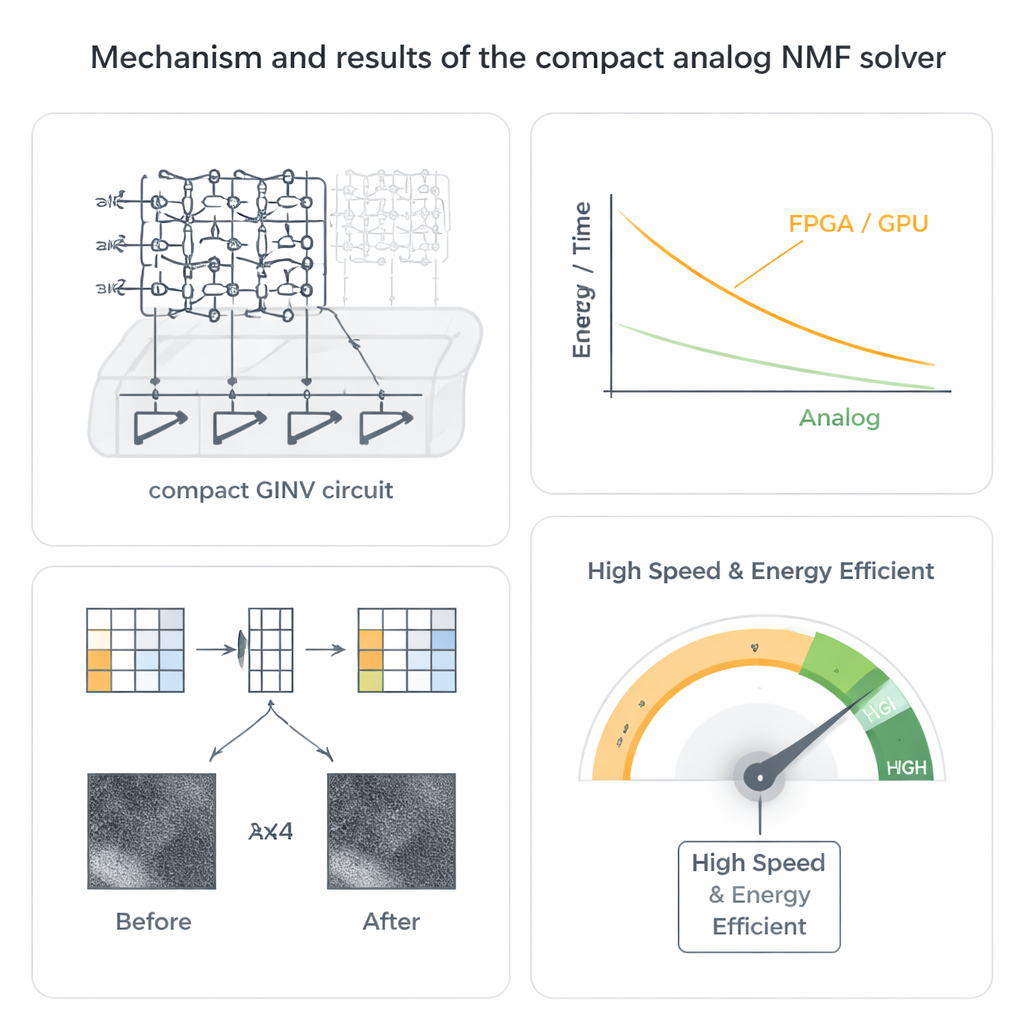
从数学技巧到可工作的硬件
为了使其在 NMF 中实用,研究者将紧凑的 GINV 电路与一种知名策略配对,称为交替非负最小二乘法。该方法不是试图同时求解两个因子矩阵——那是一个困难的非凸问题——而是交替固定一个矩阵来改进另一个,将任务分解为一系列更简单的非负回归问题,正好是模拟电路可以解决的。他们制造了氧化铪忆阻器阵列并搭建了印刷电路板平台,然后展示了两个关键应用。在图像压缩方面,一幅星云照片被分成小块并进行分解,存储量减半,同时仅以极小的视觉质量损失重建图像。在推荐系统方面,他们对诸如 MovieLens 100k 的用户—物品评分数据进行分解,能够准确预测缺失评分,即使矩阵极为稀疏。
现实世界中的速度、效率与鲁棒性
除了基本的正确性之外,模拟求解器展现出显著的速度和能量优势。由于交叉阵列中的电流代表着同时完成的许多运算,解决一个回归问题的时间几乎与矩阵规模无关,这与数字方法形成了鲜明对比。系统级估算表明,与先进的 FPGA 和 GPU 实现相比,速度可提升数百到数千倍,同时能效提高数个数量级。或许令人惊讶的是,硬件的模拟特性并非弱点而是优势:NMF 算法天然地容忍器件噪声和编程误差,在仿真中即使忆阻器值相当不精确或随温度漂移,最终的图像和推荐质量仍保持较高水平。
对日常技术意味着什么
简而言之,这项研究表明一种新型“内存中的计算器”可以比现有数字芯片更快、更高效地处理现代数据科学的常用工具之一。通过将矩阵分解直接嵌入紧凑的模拟电路,流媒体推荐、个性化内容排序和设备端图像处理等服务最终有可能实现实时运行并显著降低功耗。该工作既提供了电路蓝图,又给出了实验验证,表明这种片内模拟计算可以以接近全精度软件的准确性处理现实数据集,指向未来能够像光穿过玻璃般轻松筛选海量数据流的硬件。
引用: Wang, S., Luo, Y., Zuo, P. et al. In-memory analog computing for non-negative matrix factorization. Nat Commun 17, 1881 (2026). https://doi.org/10.1038/s41467-026-68609-8
关键词: 片内模拟计算, 非负矩阵分解, 忆阻交叉阵列, 图像压缩, 推荐系统