Clear Sky Science · zh
使用锐度感知训练的物理神经网络
这对未来人工智能硬件为何重要
随着人工智能变得更加强大,其瓶颈越来越多来自运行它们的芯片,而不是巧妙的算法。一条有前景的出路是将神经网络直接构建在物理硬件中,使用光、模拟电子学或其他基于波的系统。本文介绍了一种新的训练方法,使这类“物理神经网络”在现实世界不完美的情况下仍保持高精度——例如器件微小制造误差、温漂或元件轻微错位时。
从数字大脑到物理机器
现代人工智能通常运行在诸如图形处理器等数字硬件上,训练依赖反向传播算法来调整数以百万计的数值权重。物理神经网络试图将这些计算卸载到真实材料和器件中——比如光子芯片、干涉仪网格或衍射光学装置——其行为天然地模拟神经网络的数学运算。因为这些系统在数据存储处就处理信息,它们相比传统芯片可以更快并且更节能。但训练它们很困难:要么在数字模型上训练然后希望能匹配硬件,要么直接在设备上训练。两条路径都会在真实设备偏离理想模型或随时间漂移时遇到麻烦。
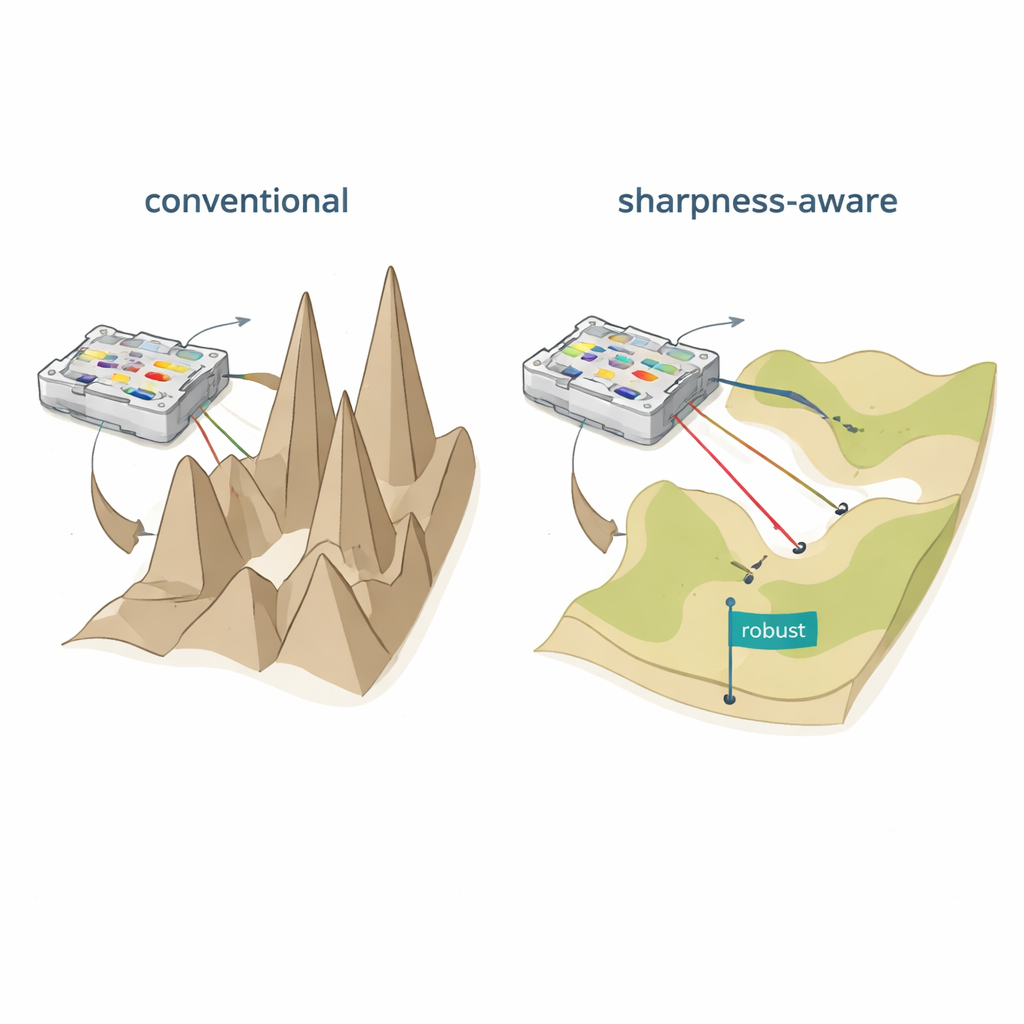
两种有缺陷的物理网络训练方式
第一种方法称为在硅上(in silico)训练,在计算机模型上学习所有参数然后复制到硬件上。只有当数学模型几乎与制造出的器件相匹配时,这种方法才有效,但一旦考虑制造差异、电噪声和热效应,这种情况很少成立。第二种方法称为在位(in situ)训练,将物理器件直接纳入学习过程,反复测量输出并调整参数。虽然这可以绕过建模误差,但会带来其他问题:梯度信息难以且代价高昂地获取,训练变得设备特定,得到的参数通常无法迁移到另一块名义上相同的芯片。无论哪种情况,部署后的小变动——例如微小的温度变化或错位——都可能大幅降低精度并迫使进行昂贵的再训练。
压平学习地形
作者提出了锐度感知训练(SAT),受机器学习中称为锐度感知最小化的思想启发。SAT不仅寻找在训练数据上误差低的设置,还寻求当底层物理参数被微调时误差变化缓慢的区域。用几何学的说法,传统训练常常找到“损失地形”中又深又窄的山谷,在那里即使是极小的电流、相位或位置变化也会导致性能崩溃。SAT有意搜索宽广、平坦的山谷,在扰动下性能仍然保持良好。从数学上讲,它在训练目标中加入一项,惩罚参数空间中尖锐、高曲率的区域,并通过两个精心选择的梯度步骤来高效近似这一惩罚,而非代价高昂的二阶导数计算。
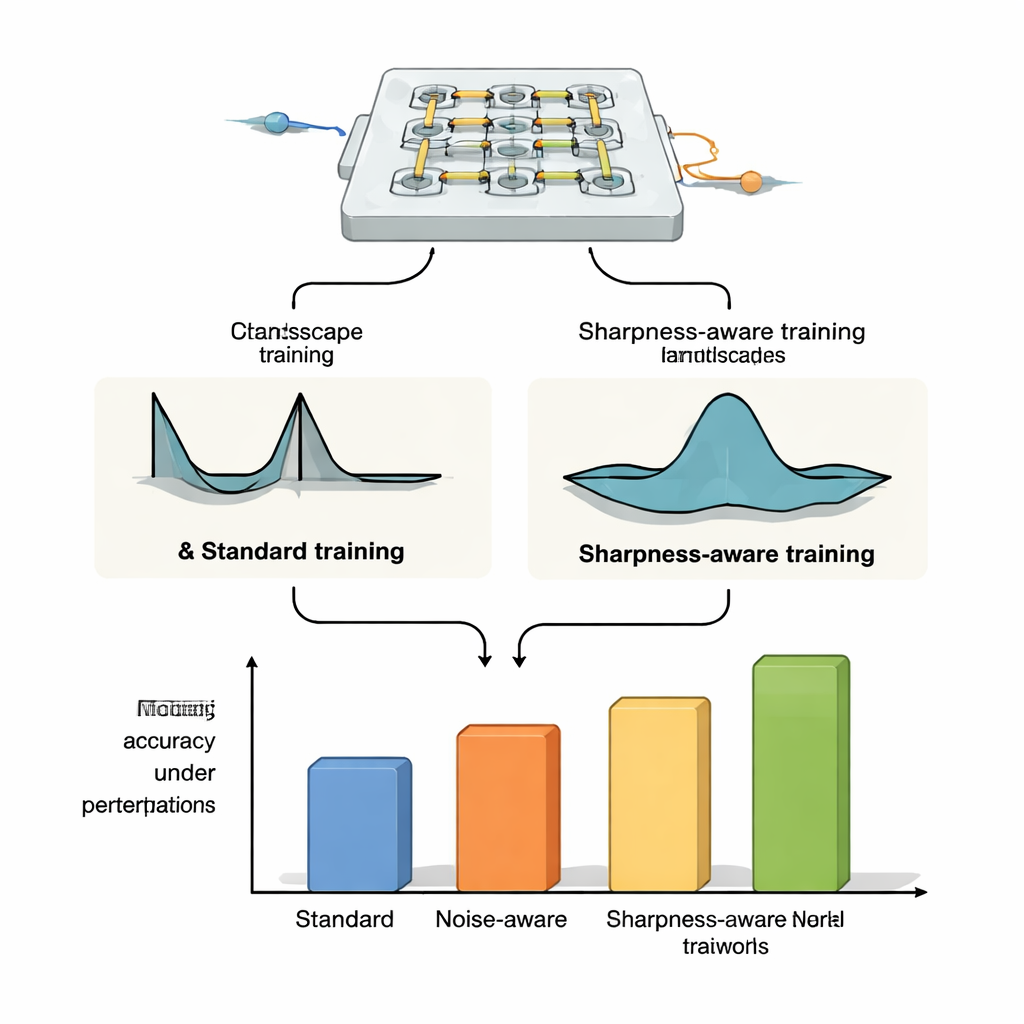
在不同光学平台上证明鲁棒性
为了证明SAT并不依赖于某一特定器件,作者将其应用到三种不同的光学神经网络平台。在微环谐振器权重库——用于按不同波长引导光的微小硅环——上,他们证明了SAT训练的系统即使在温度漂移几摄氏度时也能保持高分类精度,而标准训练和噪声注入方法则会严重失败。他们将方法推广到更有挑战性的任务,如CIFAR-10上的图像分类、图像压缩与重建以及图像生成,SAT在适度热漂移下也能维持稳定性能,而传统方法则会失效。在Mach–Zehnder干涉网格的仿真中,SAT训练的模型对现实制造误差更加宽容,且关键是,在一块器件上训练得到的参数可以迁移到具有不同缺陷的其他芯片而不丧失精度。最后,在使用OLED显示器、镜头和空间光调制器的自由空间衍射光学装置中,SAT提高了对物理错位(如旋转、像素偏移和缩放)的容忍度,尽管这些错位与网络参数之间的确切关系并未被显式建模。
通往可靠物理人工智能的实用路径
通俗地说,这项工作展示了如何以一种“宽容”真实器件不可避免怪癖的方式训练硬件神经网络。通过将学习引导向误差地形中平坦、稳定的区域,锐度感知训练使物理神经网络在精度和对制造差异、温度变化与机械错位的鲁棒性上都有所提升。因为它既可以在有详细物理模型时使用,也可以在无模型时使用,并且适用于多种类型的光学硬件,SAT为将快速、能效高的物理人工智能系统从实验室示范扩展到现实应用提供了一个可行的方案。
引用: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
关键词: 物理神经网络, 光子计算, 稳健训练, 锐度感知优化, 类脑计算硬件