Clear Sky Science · zh
在脉冲神经网络中进行与模型无关的线性内存在线学习
为什么训练类大脑计算机如此困难
脉冲神经网络是一类使用短暂电脉冲进行通信的人工网络,类似于真实的脑细胞。它们有望实现超高效的仿脑计算并能更逼真地模拟神经回路。但要教会这些网络执行复杂任务,尤其是在长时间尺度上,通常需要大量计算机内存和大量手工编写的代码。本文介绍了 BrainTrace,一种旨在使脉冲网络训练既实用又广泛可用的系统。
教会实时学习的网络
用于类大脑网络的最强大训练方法通常通过重放整段活动序列,并将误差信号在每个时间步向后传播。这种方法称为通过时间的反向传播,虽然非常准确,但当序列很长或网络规模很大时会很快遇到问题:每个中间状态都必须被存储,导致内存随着时间和网络规模同时增长。替代的“在线”方法在数据流入时逐步更新连接,从而大幅减少存储需求。然而,现有的在线规则要么只适用于非常简化的神经元模型,要么仍然需要随着网络规模二次增长的内存,使其难以应用于现实的脑规模系统。
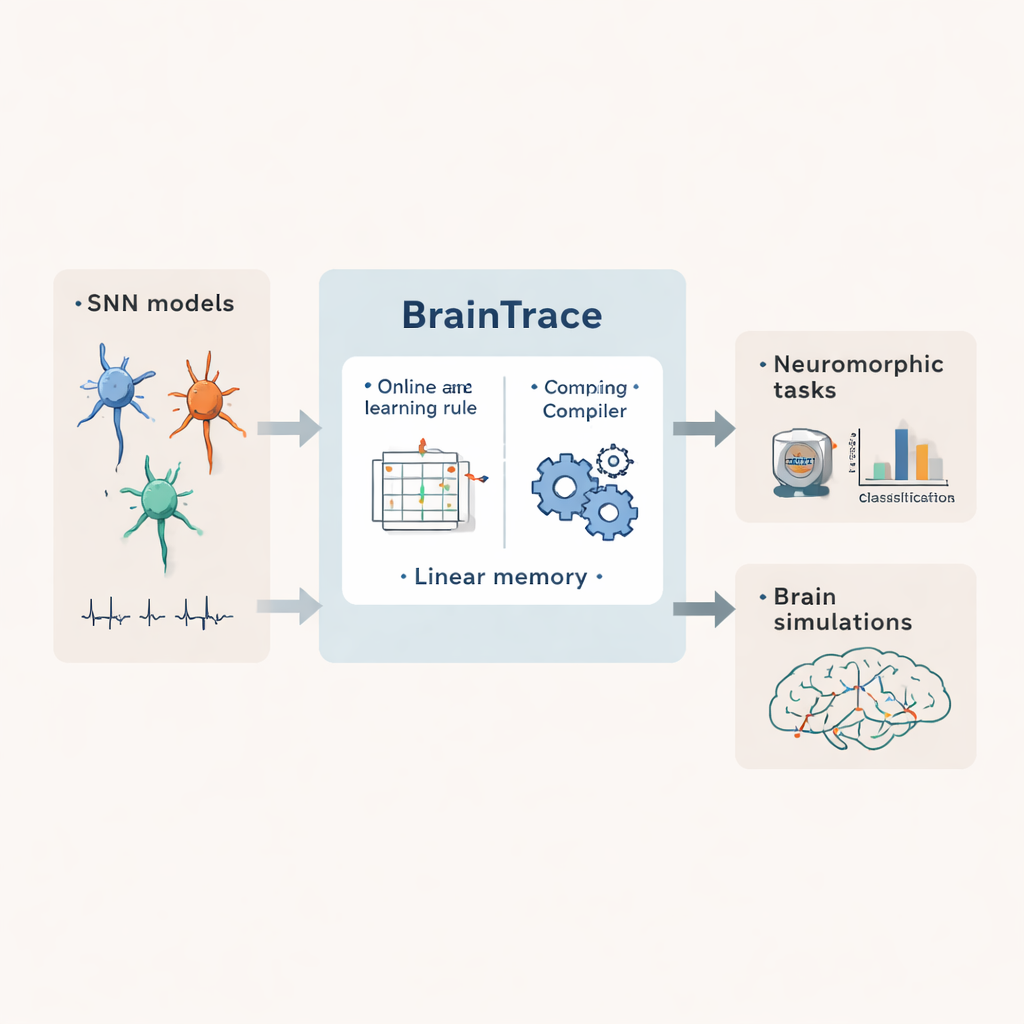
适用于多种脉冲网络的通用方案
BrainTrace 通过先以统一方式描述脉冲网络来应对这一挑战。作者展示了许多神经元和突触类型可以表示为两个相互作用的部分:描述每个神经元状态如何随时间变化的内部动力学,以及将输入脉冲转化为细胞间流动电流的交互动力学。他们进一步引入了两种建模视角,称为 AlignPre 和 AlignPost,分别将突触组织在发送神经元或接收神经元周围。这种抽象使得从简单的泄漏神经元到具有自适应阈值和复杂突触的更丰富细胞等各种生物与工程模型都能用相同的数学工具处理。
一种节省内存的因果追踪方法
在线学习的核心挑战是跟踪每个连接的微小变化最终如何影响网络行为,这一量由所谓的“资格迹线”捕捉。理论上,保留完整资格信息需要跟踪随神经元数量三次方增长的庞大矩阵。BrainTrace 利用脉冲网络的三个关键特性:大多数神经元在大部分时间保持沉默;每个神经元自身的泄漏与复位主导其状态变化;以及脉冲和突触电导始终为正。基于这些事实,作者证明那些巨大的资格矩阵可以近似为每个突触仅两个紧凑迹线的乘积——一条总结突触前活动,一条总结突触后活动。这个称为 pre‑post 传播(pp‑prop)的规则只需随网络规模线性增长的内存,同时仍能产生与完整反向传播高度对齐的梯度。
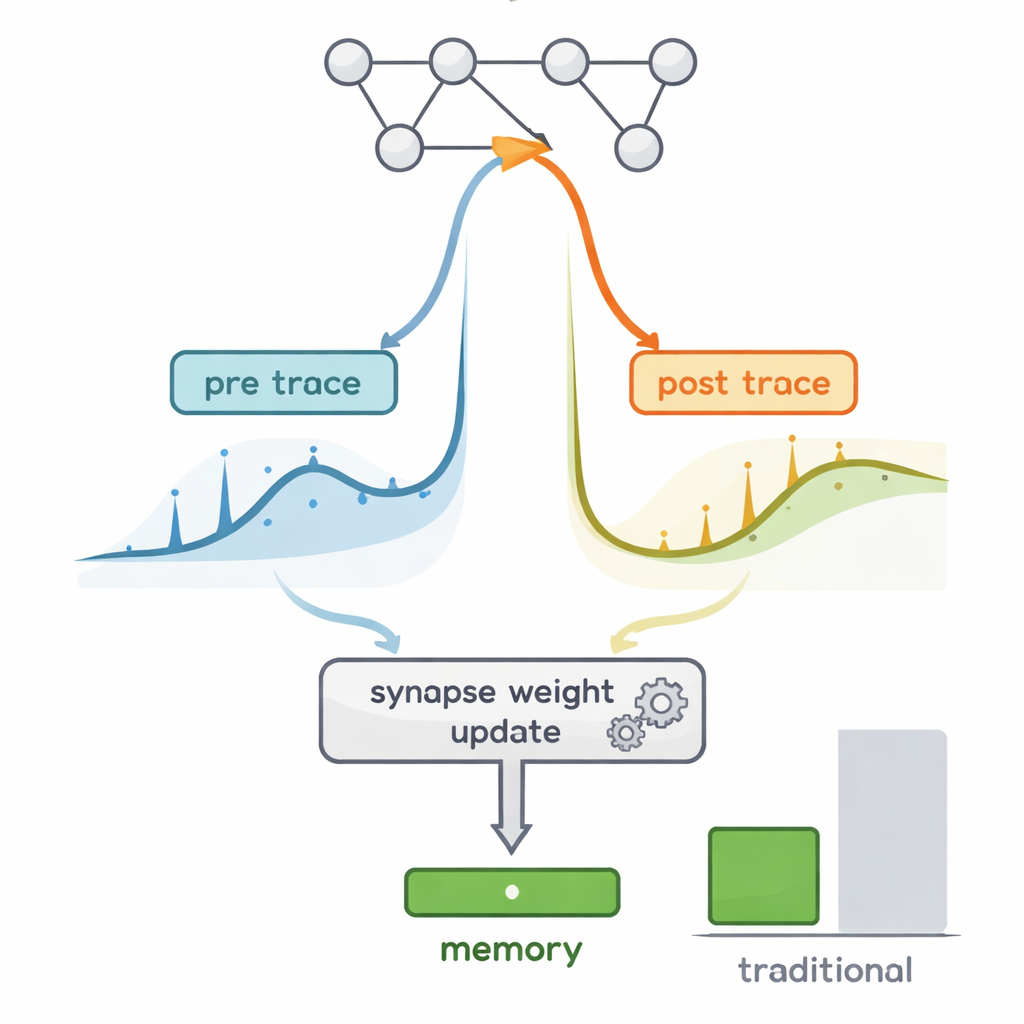
隐藏数学细节的自动化工具
除了学习规则本身,BrainTrace 提供了一个类似于深度学习中自动微分库的编译器。用户用高级语言写下其脉冲模型的动力学。BrainTrace 编译器随后分析状态与参数的连接方式,构建必要的资格迹线,并输出针对 CPU、GPU 或专用加速器高效运行 pp‑prop 或相关算法的优化代码。这意味着模型构建者可以专注于科学问题,而无需手工编写易碎的梯度代码,同时仍能受益于在线、内存高效的学习。
从微小传感器到整个果蝇大脑
作者在标准的类神经形态基准上测试了 BrainTrace,其中脉冲网络对事件驱动版本的图像、声音和手势进行分类。在多个数据集和架构上,pp‑prop 在准确率上与完整反向传播相当,同时使用的内存低几个数量级,并且比其他在线方法运行更快。关键是,该系统还能扩展到苛刻的神经科学问题。在一个示例中,一个具有分离兴奋和抑制群体的生物学细节丰富的脉冲网络学会了证据累积的决策任务,并产生了类似于鼠类皮层记录到的活动模式。在另一个示例中,一个按照果蝇连结组接线、超过 125,000 个神经元的脉冲模型被训练以再现全脑记录到的静息态活动——这一成就超出了在单张显卡上用传统训练方法的内存容量。
这对未来类大脑计算意味着什么
对非专家而言,主要信息是 BrainTrace 将曾经不切实际的梦想——实时训练丰富的、脑规模的脉冲网络——变为切实可行。通过找到一种巧妙的方法,仅用少量内存就能跟踪因果关系,并将其封装在自动化工具中,这项工作使类脑计算在人工智能和基础神经科学的日常应用中更近了一步。它为构建能够以真实神经系统那样的效率与时间精度学习和适应的机器指明了方向,而无需依赖超级计算机级别的资源。
引用: Wang, C., Dong, X., Ji, Z. et al. Model-agnostic linear-memory online learning in spiking neural networks. Nat Commun 17, 1745 (2026). https://doi.org/10.1038/s41467-026-68453-w
关键词: 脉冲神经网络, 在线学习, 类神经形态计算, 大脑模拟, 基于梯度的训练