Clear Sky Science · zh
基于空间-光谱超多路复用并行衍射的单次矩阵-矩阵光子处理器
为何更快、更节能的计算很重要
每当我们向数字助手提问或翻看社交媒体时,强大的人工智能模型就在幕后运行。这些模型变得如此庞大,以至于传统的电子芯片在不消耗巨量能量的情况下难以跟上。本文介绍了一种新型计算硬件,它用光而非电来完成关键的人工智能计算,目标是让未来的机器既更快又更节能。
把光变成计算器
现代人工智能依赖一种称为矩阵乘法的运算,在神经网络分析图像或文本时,这类运算会重复进行数十亿乃至数万亿次。电子芯片能可靠地完成这些工作,但在芯片内部频繁移动数据会浪费大量能量。本文的研究者基于另一个思路:让光本身来做运算。在光学神经网络中,信息被编码到激光束中,随着光束通过透镜和调制器而被操控,随后由光传感器读出。由于光子不像电子那样在导线上产生大量热量,这类系统理论上可以实现更高的速度和能效。
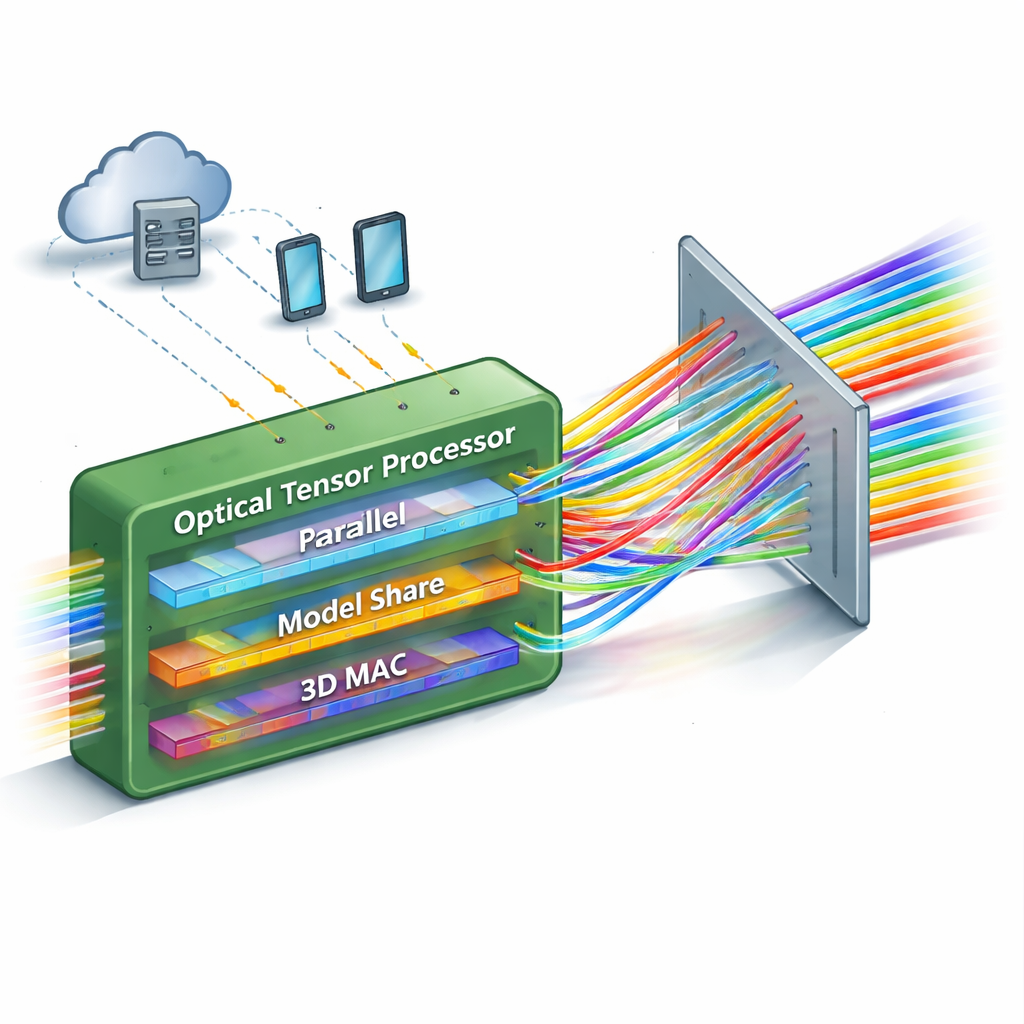
一次性完成大量计算
现有的大多数光学神经网络有一个限制:它们能并行处理的计算量有限,或者一旦扩展就变得过于复杂。该工作提出了一种“单次”矩阵-矩阵光子处理器,显著提高了可以同时完成的运算数量。其关键思想是同时在光的三个不同属性上承载信息——空间位置、颜色(波长)和时间。通过精心安排这些维度,器件可以在光通过系统的一次过程中完成完整的矩阵-矩阵乘法,涉及数千次乘加运算。
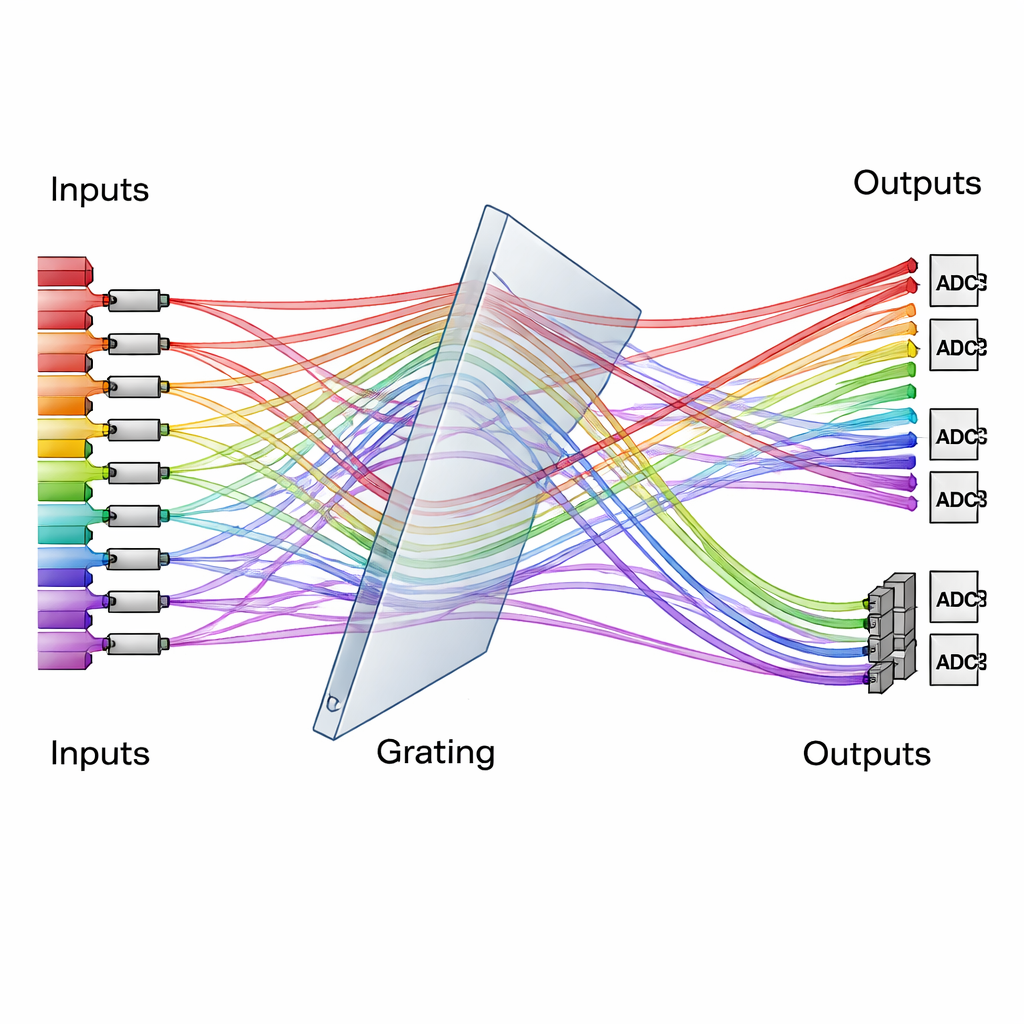
将衍射光栅作为光的交通指挥
设计的核心是一个看似简单但功能强大的光学元件:衍射光栅,它会根据光的颜色将光分成不同角度。团队使用一种特别排列的三维光栅系统,像交通指挥一样,将来自许多输入通道的多色光束路由到重新排列的输出通道。待处理的数据作为强度被编码在一组调制器上,而神经网络的“权重”则编码在另一组调制器上。当光束相遇并通过光栅时,它们的路径被重新排列,使得每个输出通道自然地对数据与权重的正确组合求和。时间积分探测器随后在几个短时间步长上累加贡献,有效地在不增加光学复杂度的情况下扩展了运算规模。
从实验室搭建到实际的人工智能任务
作者展示了一个16×16×16×16的光学张量处理器,这意味着它能在一次光学“快照”中把一个16×16矩阵与另一个16×16矩阵相乘,瞬时完成4096个基本运算。该系统以多吉赫兹的时钟速率运行,达到超过八位的有效计算精度,可与许多实用的人工智能加速器相媲美。为证明这不仅仅是物理学上的演示,他们用该处理器执行了一个小型图像识别流水线的部分任务:先用卷积神经网络从手写数字图像中提取特征,再用全连接神经网络对其分类。即便存在光学噪声和硬件瑕疵,该装置仍能以约96%的准确率正确识别手写数字,接近同一模型的全数字实现。
能耗、灵敏度及其可扩展性
由于该架构在许多并行通道间重复使用相同的光学组件并高效地累加信号,每个基本运算所需的光能极低——可低至每次乘法几十个阿托焦耳。作者估算整体能效已超过一些最先进的电子人工智能加速器,并认为通过适度改进调制器和数模转换器,这一数值可推进到每瓦数以百万亿计的运算次数。重要的是,该设计避开了困扰其他光学方案的一些扩展瓶颈,因此使用相似组件构建更大规模(例如30×30甚至60×60阵列)的可行性看起来很高。
这对日常技术意味着什么
简单来说,这项研究表明,一个相对简单的光学装置——一种通过衍射光栅智能路由彩色光束的方法——可以成为强大且低能耗的人工智能计算引擎。尽管这仍是实验室原型,但它指向未来的数据中心和边缘设备,在那里基于光的处理器处理最繁重的神经网络任务,降低能耗并支持更大更快的模型。如果这类光子张量处理器能够实现集成化和规模化制造,它们可能成为下一代高性能、能效型人工智能硬件的关键组成部分。
引用: Luan, C., Davis III, R., Chen, Z. et al. Single-shot matrix-matrix photonic processor based on spatial-spectral hypermultiplexed parallel diffraction. Nat Commun 17, 484 (2026). https://doi.org/10.1038/s41467-026-68452-x
关键词: 光学神经网络, 光子计算, 矩阵乘法, 节能型人工智能硬件, 衍射光栅