Clear Sky Science · zh
用于脂质组学和代谢组学数据的统计处理与可视化的 R 和 Python 最佳实践与工具
为何将实验室数字转成清晰图像至关重要
现代仪器现在可以在一滴血或组织样本中测量数千种微小分子——脂质和其他代谢物。这些测量结果包含有关疾病风险、治疗反应以及身体如何对饮食或衰老做出反应的线索。但原始输出并不是现成的答案:它是一张巨大的数字表格,需要清洗、分析并转换成易于理解的图像。本文说明研究人员如何使用两种流行的编程语言 R 和 Python 来可靠、透明地进行这些工作,并生成符合发表要求的图形。
从化学测量到复杂的数据表
在脂质组学和代谢组学中,质谱和色谱会生成大型数据集,每一行代表一个样本,每一列代表一种分子。这些表格很少像教科书中的示例那样整洁。它们包含缺失值、离群值以及偏态分布,其中少数分子具有极高的含量。浓度可能横跨几个数量级,并可能受到年龄、性别、饮食、药物、日节律以及仪器漂移或批次效应等技术问题的影响。国际专家组织已发布指南以标准化样品的采集、处理和报告,但即便在良好的实验室规范下,仍然需要谨慎的统计处理,才能从嘈杂背景中提取出真实的生物学信号。
清理和准备数据
在任何关于健康组与疾病组比较有意义之前,必须先对数据进行准备。综述描述了缺失值如何产生——通过随机故障、仪器限制或信号干扰——并解释了何时可以安全地忽略它们、何时应重新测量,以及如何使用诸如 k 最近邻、随机森林或简单低值替代等方法对其进行合理估算(插补)。接着,作者概述了可减少不希望变异的归一化策略,例如使用质量控制样品校正批次效应或调整样品量差异。然后讨论了像对数这样的变换——可抑制数据的长右尾——以及将所有分子置于可比基础的缩放方法,以免高度可变的化合物在后续分析中占主导。 
统计检验与可视化叙事
一旦数据得到适当准备,各类统计工具便派上用场。针对单个分子,研究人员可以计算倍数变化并使用经典检验,如 t 检验或其非参数对应方法(例如 Mann–Whitney 检验),以判断不同组之间水平是否存在差异。针对涉及多个组的比较,引入了 ANOVA 或 Kruskal–Wallis 检验,并配以事后程序以确定哪些组之间存在差异。当这些检验结果以清晰的方式可视化时,其效力得以释放。文章强调了箱线图(包括针对偏态数据改进的版本)、小提琴图和同时展示效应大小与统计显著性的火山图。对于脂质,还描述了更专业的可视化,例如展示整个类别协调变化的脂质网络,以及揭示碳链长度和饱和度模式的脂肪酰基链图。
同时观察多变量中的模式
由于每个样本可能测得数百或数千种分子,多变量方法至关重要。综述解释了主成分分析(PCA)如何将这种复杂性压缩到少数几个新轴上,这些轴捕获主要变异方向,从而可以快速检查组间分离、批次效应或分析稳定性。更高级的非线性方法,包括 t-SNE 和 UMAP,可以在高维空间中揭示微妙的簇和结构。在目标是对样本进行分类的情况下——例如将患者与对照区分开——作者描述了基于偏最小二乘及其正交扩展的监督方法(PLS-DA 和 OPLS-DA)。这些方法将分子谱与样本标签关联,支持特征选择,常用得分图、载荷图和受试者工作特征曲线来总结结果。
R 与 Python 中的实用工具包
为帮助初学者从理论走向实践,文章考察了广泛的软件生态系统。在 R 中,tidyverse 和 tidymodels 等集合简化了数据整理与建模,而 ggplot2 及其扩展包如 ggpubr、ggstatsplot 和 tidyplots 则便于生成可供发表的图形。专门的库处理 PCA、聚类和基于 PLS 的模型,Bioconductor 包支持复杂热图和交互式图形。在 Python 中,pandas 提供表格处理,matplotlib、seaborn 和 plotly 负责可视化,scikit-learn 提供了广泛的多变量方法。贯穿全文,作者强调在随附的 GitBook 中提供逐步示例,使读者能够复制工作流程并将其适配到自己的数据中。 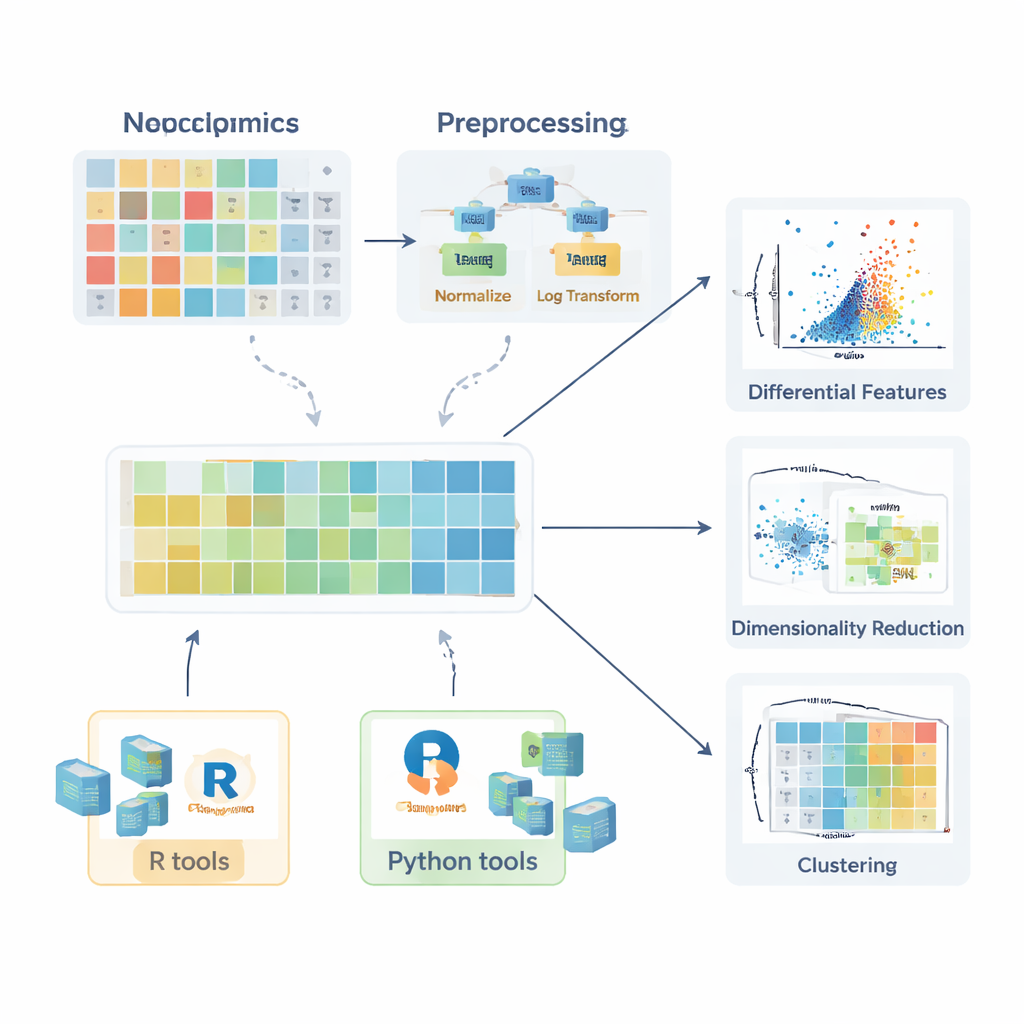
将复杂化学信息转化为可靠结论
文章总结道,脂质组学和代谢组学的真正前景不仅在于强大的仪器,而在于如何审慎地处理和可视化其输出。通过遵循良好的统计实践、使用开放且文档良好的 R 与 Python 工具,并依赖共享的代码示例,研究人员可以构建稳健且可重复的管道。这将提高在微量分子中发现的模式能转化为可信的生物标志物、对疾病机制的更好理解以及最终造福患者的更个性化医疗方法的可能性。
引用: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
关键词: 脂质组学, 代谢组学, 数据可视化, R 编程, Python