Clear Sky Science · zh
利用机器学习与基因组学改良边缘作物的应用
潜力巨大的隐秘作物
在非洲、亚洲和拉丁美洲,数以百万计的人口依赖所谓的“边缘作物”,例如高粱、特夫、木薯和花生。这些植物鲜少登上头条,但往往比小麦或水稻等全球主食更能耐高温、干旱、病虫害和贫瘠土壤。本文综述探讨了两种强有力的工具——基因组学与机器学习——如何释放这些被忽视作物的潜力,提升当地粮食安全,同时为强化全球主要作物提供有价值的基因资源。
为何被忽视的作物重要
边缘作物有时被称为“被忽视”或“未充分利用”,因为它们在科学研究和商业投入方面远不如那些出口大宗作物受到关注。然而,它们是许多社区的营养主食,并且常在其他作物难以生长的恶劣边缘环境中种植。与小麦或水稻不同,大多数边缘作物未能从绿色革命的育种进展以及标记辅助育种和基因组编辑等现代工具中获益。像非洲边缘作物联盟这样的基因组项目开始对它们的DNA进行测序和编目,但如何将原始遗传数据转化为实用改良仍是重大挑战。
教计算机“读懂”植物
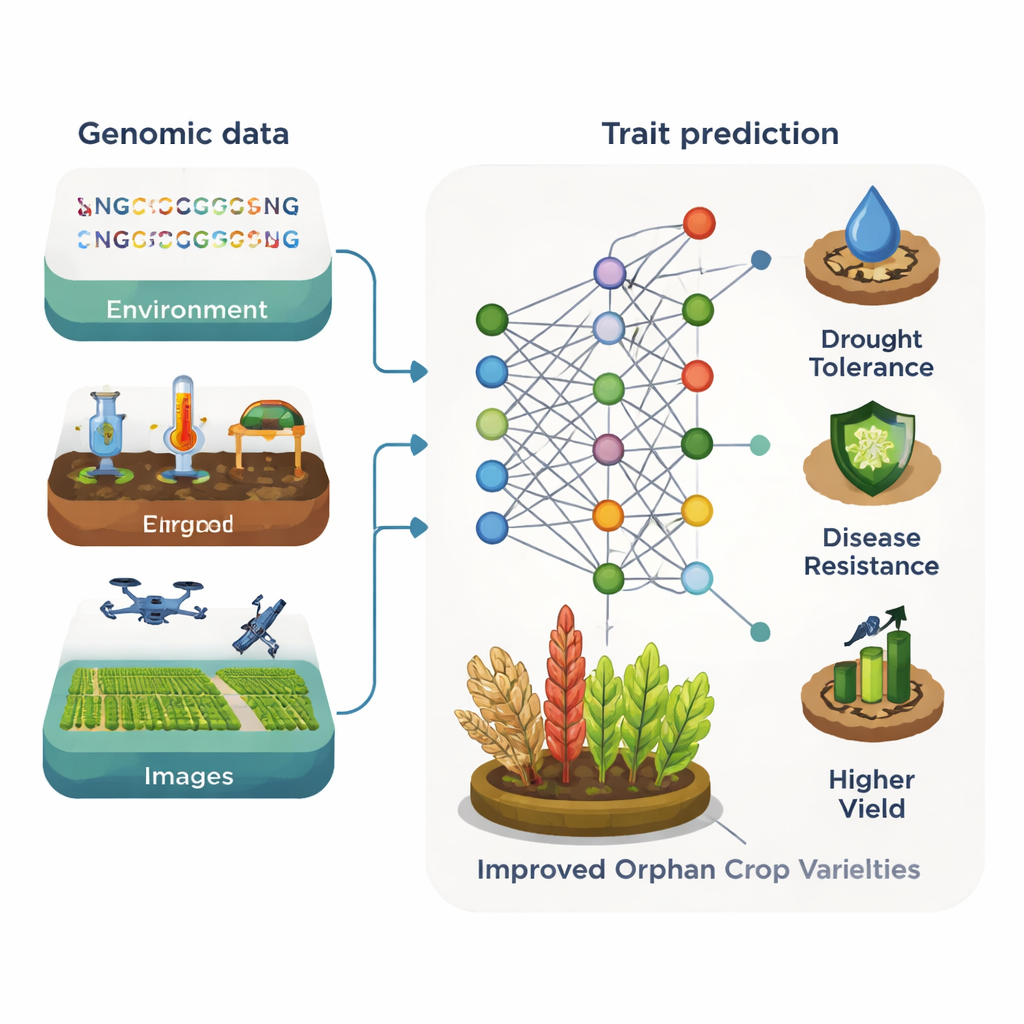
机器学习——从大规模数据集中学习模式的计算方法——已在主要作物的育种中带来变革。通过结合基因组序列、天气与土壤记录、传感器读数以及无人机或智能手机拍摄的图像,算法可以预测产量、抗病性或籽粒质量等复杂性状。不同模型类型——从决策树到深度神经网络——在不同场景中各有所长。有时传统统计工具仍能与深度学习匹敌或胜出,但总体而言,融合多源数据与多种模型往往比任何单一方法为育种者提供更准确、更稳定的预测。
在稀缺数据中做到最好
对于边缘作物而言,关键障碍不是计算能力而是数据匮乏。公开的基因组与图像集合屈指可数,且少有规模足以支撑传统机器学习流程。尽管如此,初步示范已展现出希望。例如在高粱中,深度学习模型使用简单的籽粒照片就能高精度预测蛋白质和抗氧化物含量,提供了实验室检测的廉价替代方案。在另一个案例中,使用近红外光谱测量结合深度学习估算了香科植物紫苏的营养性状。文章认为,建立边缘作物的共享基因组、图像和化学谱数据库将会迅速放大此类工具的影响。
向大型作物借用知识
文章的核心理念之一是物种间的“知识迁移”。许多边缘作物与主要作物是近缘种,分享大段DNA和相似基因。机器学习模型可以利用这种相关性。先在拟南芥或玉米等研究充分的植物上训练的工具,可以帮助在不太知名的近缘作物中定位与株高、种子质量或抗逆性等性状相关的基因。最初为人类或植物基因组开发的大型语言模型也可以将DNA视为一种文本,学习标记调控区域或关键基因的模式。一旦在丰富数据集上训练完毕,这些模型可以在有限的边缘作物数据上进行微调,以预测基因功能、指出基因编辑的目标并指导更高效的育种。
从算法走向田间与农户
作者强调,仅有技术不足以改变边缘作物的命运。进展依赖于对本地科学家的投资、与小农户的合作以及确保社区从新品种中受益的政策。公民科学方法,即让农户在自家土地上直接测试品种,可为机器学习生成有价值的数据,同时使研究贴合本地需求和口味。由于资金有限,文章建议采取平衡策略:将低成本的传统育种与农艺措施与有针对性的基因组学和机器学习项目相结合,并在国家之间、边缘作物与主要作物之间共享工具与数据。
这对我们粮食未来的意义
简言之,文章得出结论:更聪明的计算方法加上更好的遗传信息,可以帮助把今天被“遗忘”的作物转变为面向气候的主粮。通过向大作物学习并将这些经验应用到小作物上——然后再把发现反馈回去——机器学习和基因组学可以加速寻找耐逆、营养丰富品种的进程。如果有周到的政策支持并与种植社区真诚合作,这一方法能改善饮食、增强对气候变化的韧性,并将世界农业工具箱拓展到超越少数主食作物的更广阔选择。
引用: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
关键词: 边缘作物, 机器学习, 基因组学, 作物育种, 粮食安全