Clear Sky Science · zh
高时钟率自由空间光学内存计算
这对日常智能设备为何重要
从自动驾驶汽车和配送无人机到高频交易与远程手术,越来越多的决策必须在几分之一秒内完成,而且经常发生在远离大型数据中心的地点。现有电子设备在不超热或过度耗电的情况下难以跟上这种需求。本文提出了一种新型的基于光的计算引擎,能够以极高速度和低能耗执行关键的人工智能任务,可能会改变网络“边缘”设备的工作方式。
把光变成计算器
现代人工智能大量依赖一种基本操作:对大规模数值网格进行乘加运算,类似于在一张图像上反复滑动一个小模板并统计其覆盖内容。用电子在芯片上执行这类操作虽然强大,但资源浪费严重,因为数据必须在存储和处理单元之间频繁传输。研究人员则构建了名为 FAST‑ONN 的系统,让光在空中完成大部分计算。他们使用整齐排列的微型半导体激光器将图像像素编码为光强,然后让这些光束通过光学元件,在空间中直接施加神经网络的“权重”,最后落在将结果转换回电信号的光探测器上。
光学引擎如何构造
系统的核心是一组致密的微型激光器阵列,称为垂直腔面发射激光器(VCSEL)。5×5 网格中的每个器件代表小图像块的一个像素,并且可以以吉赫兹级速度开关——每秒数十亿次。一个图案化的玻璃元件将这组光束分裂成多个副本,因此同一图像块可以被若干不同滤波器并行处理。一个可编程的空间光调制器,类似于高分辨率显示屏的原理,充当滤波器权重的“内存”:其数百万个微小像素分别调节或透过光以表示神经网络权重。光束随后汇聚到与光纤耦合的探测器,这些探测器对每个滤波器的光强进行求和,从而在一次光学步骤内有效地完成一批卷积运算。 
处理正负“权重”
AI 模型不仅要增强某些模式,也必须抑制其他模式,这就需要正负权重。由于光强本质上不能为负,这一直是纯光学计算面临的挑战。作者通过将光分成携带加权光束的信号路径和保持未加权的参考路径来解决这一问题。两者都输入到成对的特殊探测器中,相互做差,从而使较少的光可以表示负贡献。这种巧妙的差分读出使光学硬件能够模拟标准神经网络的全部行为,同时对噪声和器件的微小缺陷保持鲁棒。
将系统付诸测试
为了证明 FAST‑ONN 不仅是物理学演示,团队把它应用到真实的识别任务中。他们将光学引擎连接到在 COCO 图像数据集上训练的标准视觉网络,该数据集被广泛用于目标检测测试。在一项模拟自动驾驶场景的实验中,对交通场景的裁剪区域进行分析,以判断每个区域是否包含车辆。最为耗费资源的卷积层被卸载到光学硬件,而其余步骤在数字系统中运行。光学版本与纯电子版本的模型表现非常接近,在区分车辆与背景杂乱方面几乎达到相同的性能。他们还演示了手写数字和服装分类,甚至进行了训练实验:在训练过程中光学系统负责前向计算,而计算机更新权重,然后将其重新载入光学调制器。 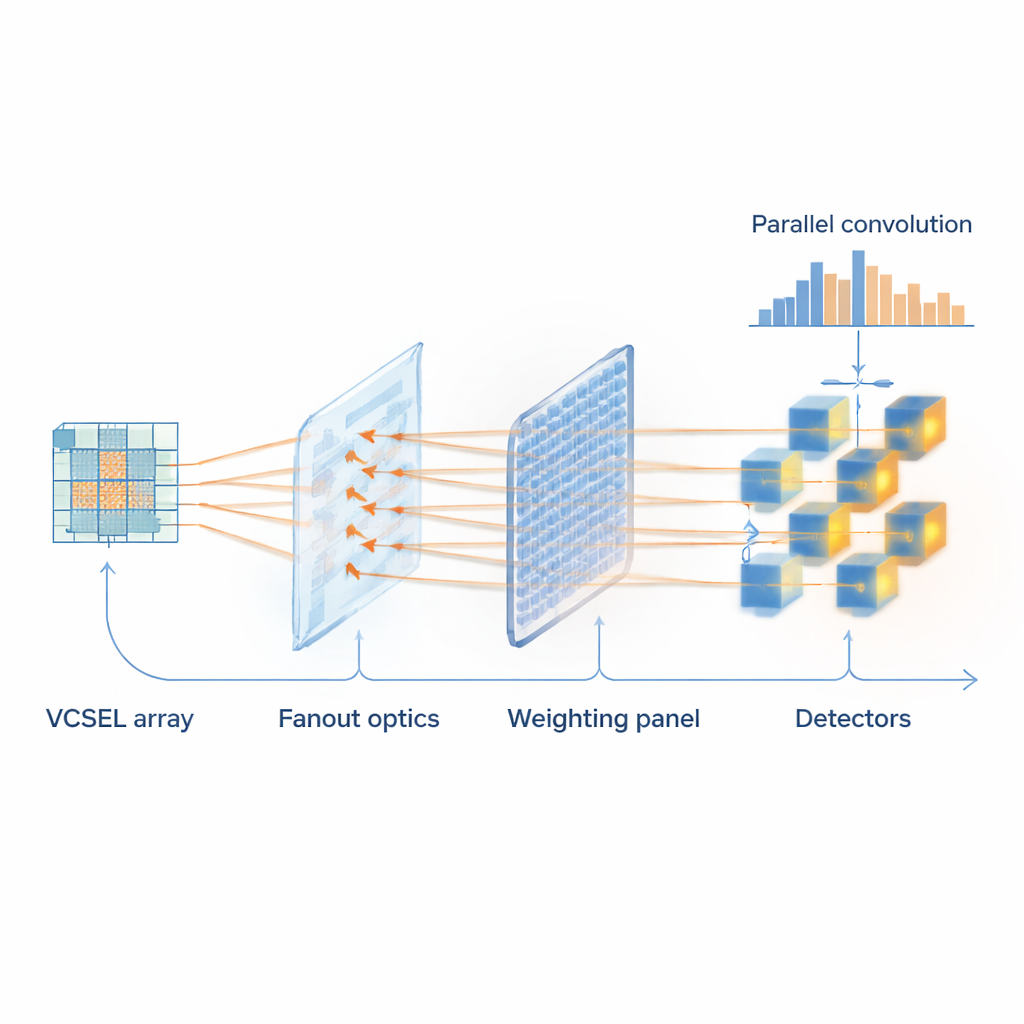
速度、效率及后续发展
在目前的原型中,使用 5×5 激光器和同时九个滤波器,该系统每秒可处理 1 亿个小图像块,已经达到近十亿次卷积运算每秒,决策时间为微秒级。详尽分析表明,采用更大阵列和更快的商用激光器,这一方法可扩展到每秒执行数万万亿次运算,同时耗能远低于领先的电子加速器。由于关键部件紧凑且适合规模化生产,FAST‑ONN 最终可能使摄像头、无人机和其他边缘设备内置小型低功耗的光学协处理器成为可能,让它们“用光思考”,并几乎以与世界变化同样快的速度做出响应。
引用: Liang, Y., Wang, J., Xue, K. et al. High-clockrate free-space optical in-memory computing. Light Sci Appl 15, 115 (2026). https://doi.org/10.1038/s41377-026-02206-8
关键词: 光学神经网络, 边缘 AI 硬件, VCSEL 阵列, 内存计算, 高速卷积