Clear Sky Science · zh
基于微梳的并行自校准光学卷积流处理器
为什么更快的“思考”机器很重要
从流媒体视频到训练大规模人工智能模型,现代数据中心正淹没在海量信息中。用现有电子芯片移动和处理所有这些数据会消耗大量电力并触及速度极限。本文介绍了一种新型基于光的计算芯片,它可以作为人工智能系统的快速、低能耗“前端”,在数据到达传统处理器之前处理其中一部分最繁重的计算。
让光来承担繁重工作
大多数人工智能系统依赖卷积,这是一种滑动的数学窗口,用于扫描图像、声音或其他信号以提取边缘或纹理等特征。电子设备逐步执行这些操作,不断在内存中搬运数值。文中描述的芯片用一种物理过程取代了这一点:光束被分裂、延迟、加权然后重新合并。由于计算随光传播同时发生,它避免了导致电子硬件变慢和发热的大量数据移动,并且每个数据流可以以数百亿次每秒的速度运行运算。
多色光,多任务并行
一个关键部件是称为微梳的器件:一种微小的环形激光源,能同时产生数十个均匀间隔的颜色或波长的光。每种颜色就像高速光学通道中的独立车道。团队的光学卷积流处理器让所有这些颜色通过同一芯片,但安排路径使它们经历相同的“卷积核”——用于分析数据的一组权重。路径之间的时间延迟与不同波长结合,形成时间、空间和波长三维的并行形式。在实验中,系统以每种颜色50吉波特的速率处理数据,并在五个波长上实现了约4万亿次每秒的总计算速度。
教会光芯片保持精确
利用光波干涉进行计算很强大,但也很脆弱:纳米级的路径长度变化就足以破坏精心调校的权重。为保持芯片精确,研究人员内置了一个特殊的参考路径和自校准程序。通过在频率上扫描激光并仅测量输出功率,他们重建了器件内每条路径的强度和相位。反馈回路随后调整芯片上的微小加热器,直到测得的卷积权重与期望值一致。该自动调谐不仅能校正制造缺陷和温度漂移,还能让同一块芯片为不同任务重新编程,例如图像的模糊或边缘检测。
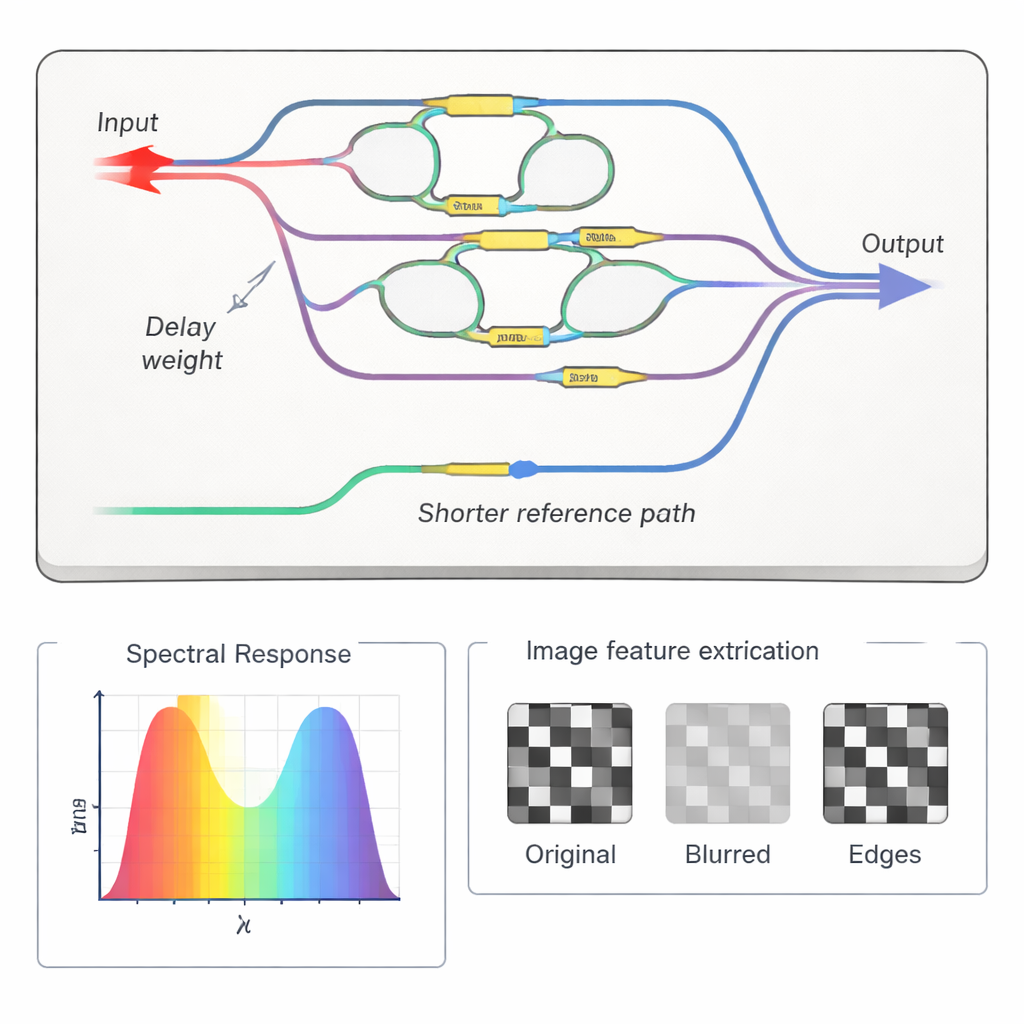
从图像滤波到真实的人工智能工作负载
为了证明该处理器在简单演示之外的实用性,作者将其与标准电子神经网络层结合成混合系统。光学芯片处理第一卷积层,从在多波长通道上传输的彩色图像中提取基本特征。得到的特征流被转换回电子信号并输入到更深的数字网络。在包含飞机、猫和卡车等类别的CIFAR‑10图像数据集上的测试表明,该光电混合系统在将大量繁重计算任务卸载到光子域的同时,达到了接近纯数字模型的准确率。
这对未来数据中心可能意味着什么
通俗地说,这项工作表明可用光进行计算的小型芯片可以直接插入现有数据中心的光纤链路,作为人工智能工作负载的共享加速器。通过结合多色光、多条延迟路径和内置自校准方法,所示处理器在不牺牲能效的情况下实现了非常高的速度和良好准确性。如果放大规模,类似设备可以部署在存储和计算机架之间,随着数据流动执行快速滤波和特征提取,帮助未来的“思考”机器运行得更快、更环保。
引用: Wang, J., Xu, X., Zhu, X. et al. Microcomb-enabled parallel self- calibration optical convolution streaming processor. Light Sci Appl 15, 149 (2026). https://doi.org/10.1038/s41377-025-02093-5
关键词: 光学计算, 光子人工智能硬件, 微梳, 数据中心加速, 卷积神经网络