Clear Sky Science · zh
基于量子与经典多模态融合网络的文化遗产多模态图像识别
为什么让计算机了解古代珍宝很重要
博物馆与档案馆中的文化珍品越来越多地被拍照并上线,但大多数图像的标签很差或根本没有标签。这使得参观者、教师和研究人员难以找到所需内容,也限制了公众深入探索人类共同遗产的能力。本文探讨了一种新的自动识别和分类此类图像的方法,结合了两类很少交汇的思想:博物馆藏品与量子计算。
从尘封库房走向数字馆藏
如今博物馆馆藏数以百万计,涵盖青铜器、漆器到刺绣袍服等诸多类别。许多机构正竞相对这些藏品进行数字化,使任何有网络的人都能浏览。然而,一旦图像上线,若不将其归入正确类别——如珐琅、玉石、丝绸或锦缎——就难以真正发挥价值。传统的人工智能工具通常只查看图像像素,忽视了策展人和历史学家为藏品附上的详尽文字描述,而这些说明常常提及肉眼不易察觉的材质、颜色与纹饰。随着馆藏规模不断扩大,经典算法在速度、能耗与复杂性方面也面临挑战。
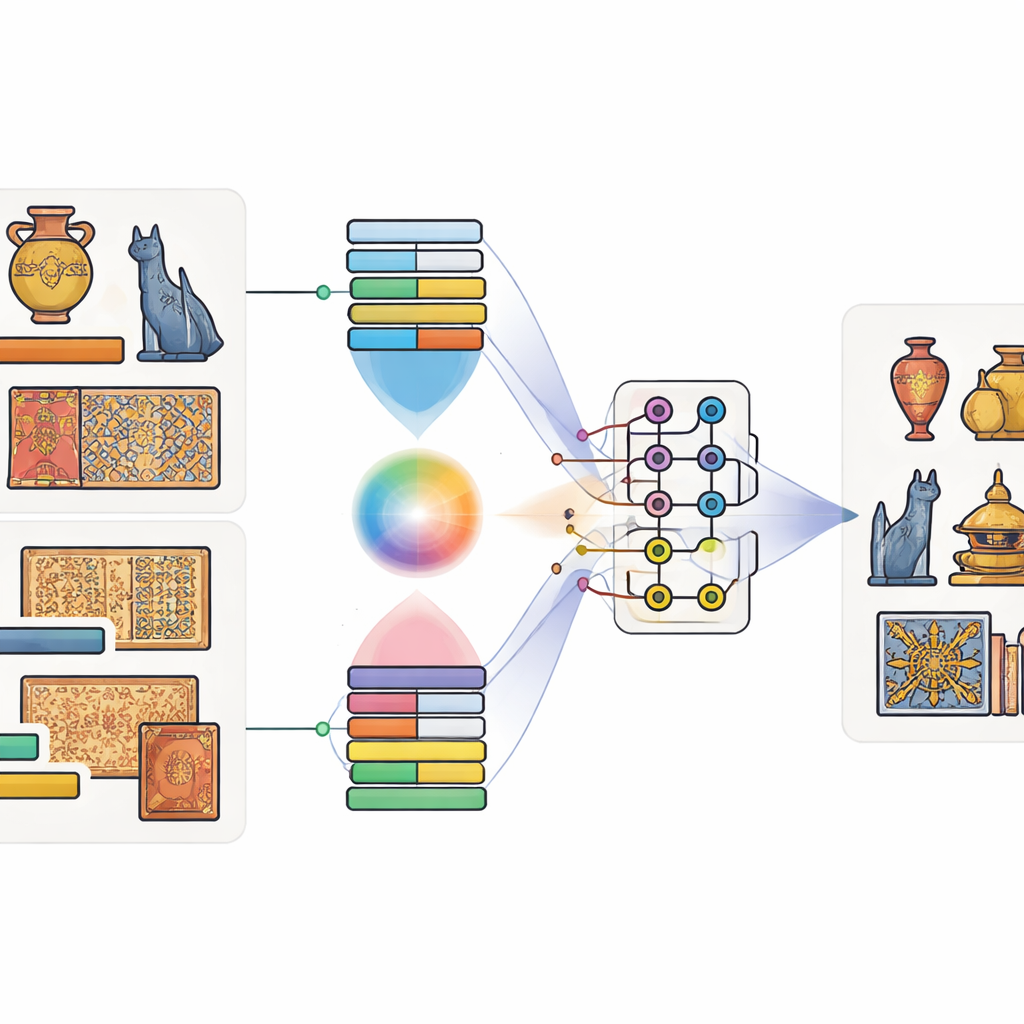
将图像与文字配对,把比特与量子比特结合
作者提出了名为量子-经典多模态融合模型的方案。“多模态”简单来说就是同时关注多种信息——在这里指的是文物图像与其说明文字。首先使用已在大规模数据上训练的成熟工具:深度图像网络用于捕捉形状与纹理,语言模型用于抓取说明文字的含义。随后,一个特殊的注意力机制学习图像的哪些区域通常与哪些词关联。例如,当说明中提到“金龙”时,模型会学会关注那些呈金色且形似龙的区域。由此产生一种融合视觉与语言的联合表征。
让量子电路混合这些信号
在提取出图像与文本特征后,模型将它们输入到一个小型的量子电路模拟器中。由于现有量子硬件的量子比特数量有限,作者采用一种压缩方案,将多个经典数值编码到少量量子比特的振幅中。在量子部分,他们设计了一个两阶段电路,反复对单个量子比特施加旋转,然后对其纠缠——使它们的状态相互依赖。该结构旨在挖掘视觉模式与说明提示之间可能被忽略的微妙关系。经过量子处理后,量子比特的状态被测量并转换回普通数值,随后传入最终分类器以预测对象类别。
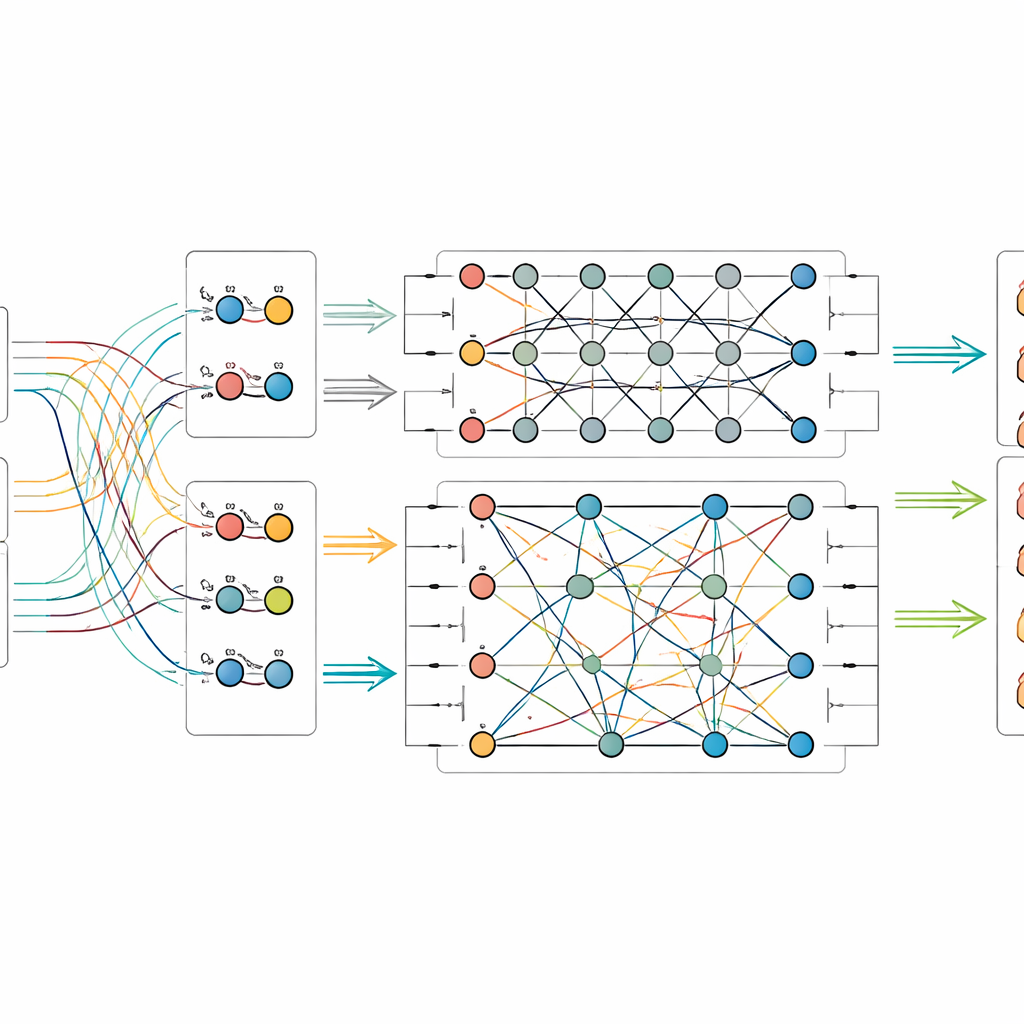
将新方法付诸检验
为了评估方法的实际效果,研究人员从故宫博物院组装了两个新数据集:一个包含珐琅、金银器、漆器、青铜与玉器等实物文物,另一个侧重于丝绸、绸缎、锦缎以及称为缂丝的复杂织造样式。每张图像都有官方说明与博物馆记录中的可信标签。他们将量子—经典融合模型与一系列强力对照方法比较,包括纯图像系统、纯文本系统以及其他图文结合的技术。在两个数据集上,该新模型在准确率及相关指标上均取得最高得分,甚至略胜过一些先进的多模态与量子启发基线。进一步实验展示了性能如何随量子比特数和电路深度变化,并表明即使在模拟中引入常见类型的量子噪声,该方法仍然保持可靠。
这对未来博物馆参观者意味着什么
对非专业人士而言,核心信息是:将图像、文字与量子启发的处理结合起来,可以提高计算机区分不同类型文化对象的能力。虽然当前的量子部分主要在模拟器上运行而非大型量子硬件上,但该研究为随着硬件成熟而出现更高效、更具表达力的工具指明了方向。在实际应用层面,此类系统可以帮助博物馆与档案馆自动整理新上传内容、清理旧记录,并让人们更容易搜索到“玉礼器”或“刺绣龙袍”等关键字并真正找到相关藏品。该工作暗示,量子计算可能成为理解与保护数字时代文化遗产的一条有用新途径。
引用: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
关键词: 文化遗产图像, 量子机器学习, 多模态融合, 博物馆数字化, 图像识别