Clear Sky Science · zh
Geo-TCAM:一种将主题建模与几何引导空间注意力相结合的唐卡图像描述方法
古老艺术与智能技术的相遇
唐卡画——那些在许多藏传寺庙中可见的色彩鲜艳的卷轴——充满了微小细节和层层宗教含义。对于没有专业背景的博物馆参观者或线上观众来说,许多象征意义难以把握。本研究提出了Geo‑TCAM,一种人工智能(AI)系统,旨在自动生成对唐卡图像的丰富且准确的描述,帮助全球观众更好地理解并保护这一独特的文化遗产。
为什么唐卡图像对计算机很难处理
与日常照片不同,唐卡作品有意呈现出密集且高度象征性的内容。一幅画可能包含一位中心神祇、数十个小型人物、花纹边框,以及每种特定手势、器物、颜色和姿势所承载的宗教意义。标准的图像描述程序通常能较好处理诸如“海滩上的一只狗”之类的简单场景,但在此类作品上常常表现欠佳:它们可能能识别出主体佛像,却遗漏他是否持钵或持剑,误判其姿势,或将其与外观相似的另一位神祇混淆。这类错误并非小事——它们可能颠倒画作要传达的故事与教义,削弱其教育与文化价值。
描述神圣图像的新蓝图
Geo‑TCAM通过结合三种思路来应对这些问题:多层次视觉特征、关于唐卡艺术的主题知识,以及面向面部等关键区域的几何引导注意力。首先,它使用深度网络(ResNet50)同时在几个层次上观察图像:中间层捕捉边缘、纹理和简单形状,而更深层则概括整体构图。通过融合这些层次,模型既能注意到像装饰细节这样的微观信息,也能掌握背景与人物的宏观布局,从而比以单一层次为主的早期系统获得更丰富的视觉理解。 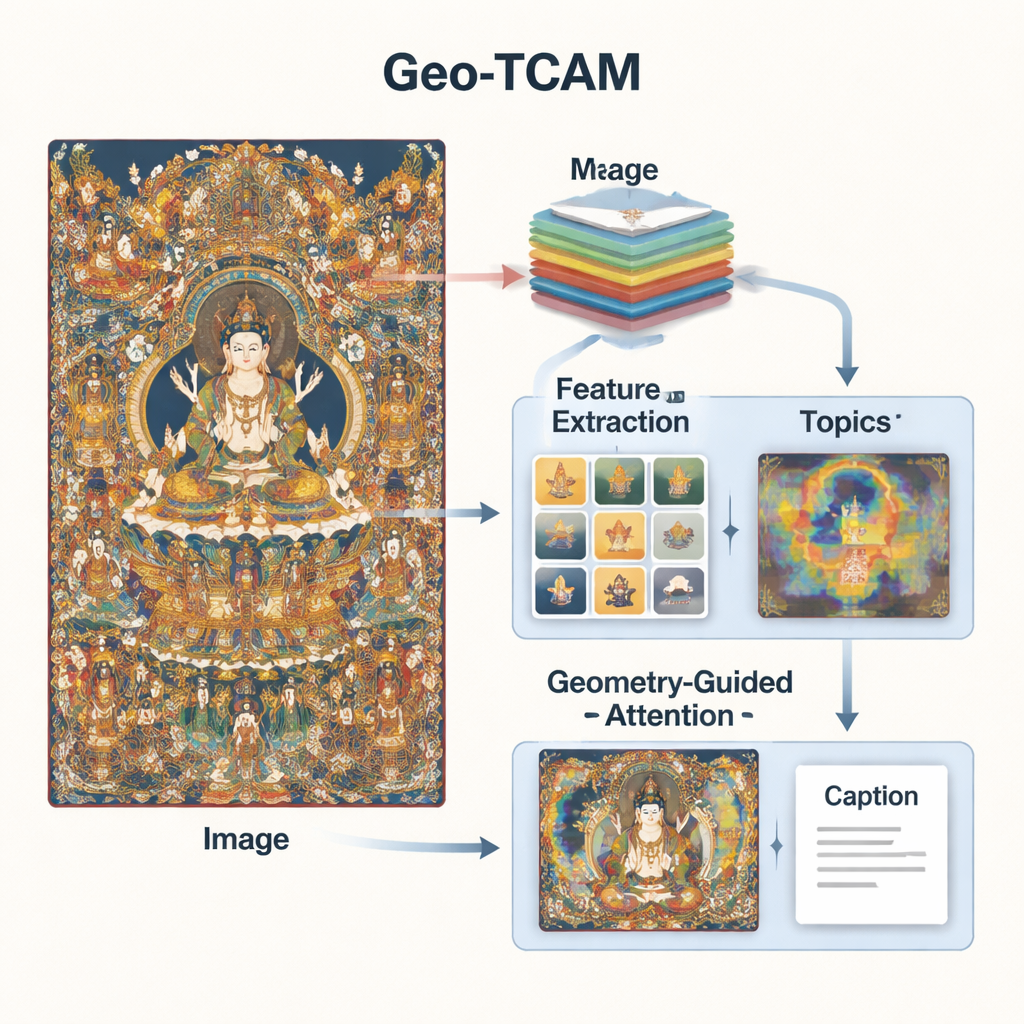
教模型学习唐卡“主题”
单靠视觉还不够;系统还需要对唐卡的语言与主题有所了解。为此,研究者在数千条专家撰写的唐卡描述上训练了主题模型。该模型将词汇归纳为少数常见主题——例如与佛、菩萨、莲座、法器或护法神相关的主题。对于每张新图像,Geo‑TCAM会估计哪些主题最相关,并将这些信息与视觉特征融合。随后,注意力机制突出那些与可能主题最匹配的图像区域。实质上,关于哪些对象与符号常见地出现在一起的先验知识,引导AI生成更有意义、更具文化意识的描述。
让AI“看向”最重要的地方
第三项创新是几何引导的面部空间注意力(GFSA)模块。唐卡的构图通常将主体面部置于画面中大致可预测的区域。Geo‑TCAM使用简单的边缘检测工具定位该区域及其周围的手势与姿态,然后应用专门的注意力机制,在生成描述时提升这些像素的影响力。这种“先定位,后引导”的策略有助于避免早期对中心神祇的误识,而那类误识会连锁引发有关手势、标志与身份的长串文本错误。可视化热图显示,加入GFSA后,模型更清晰地集中于主体面部和关键物件,同时仍关注重要的背景图案。 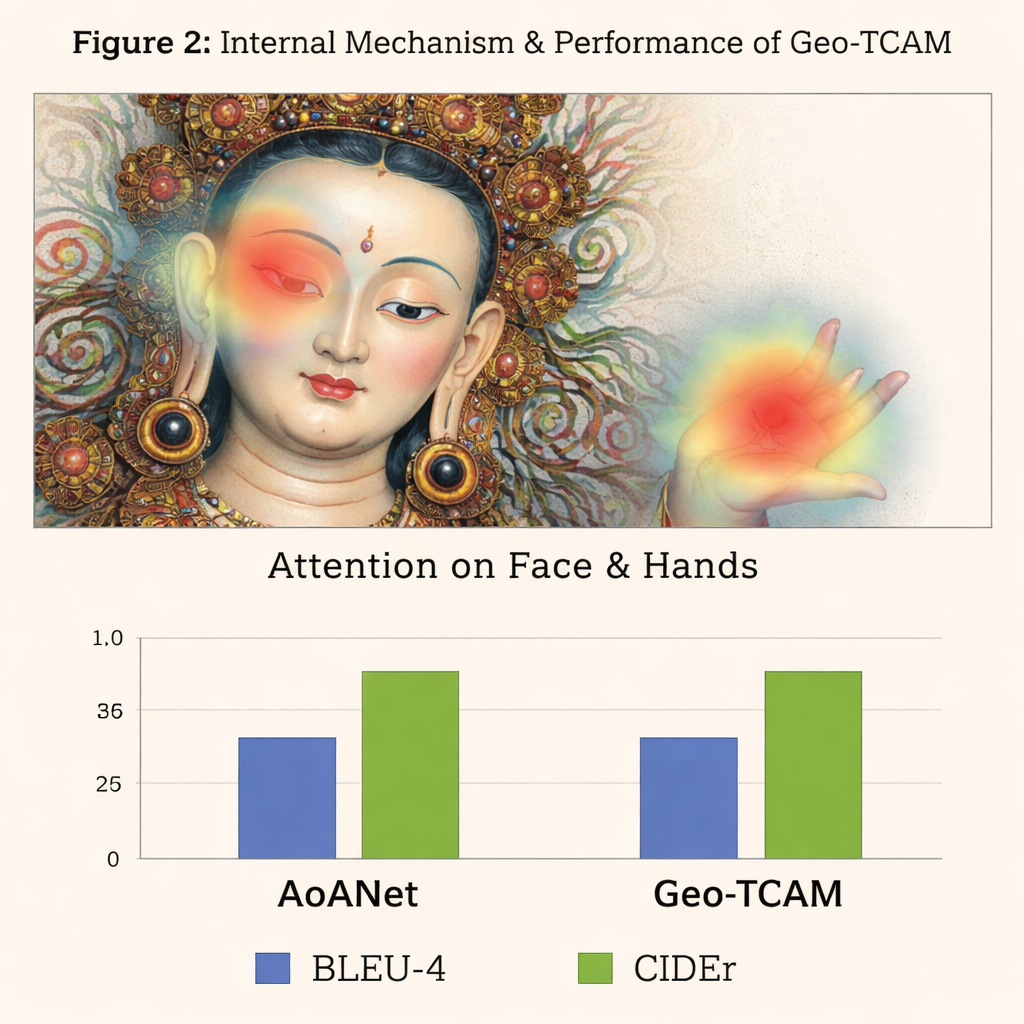
Geo‑TCAM的表现如何?
为了检验他们的方法,作者构建了一个专门的D‑Thangka数据集,包含近4000幅经精心标注的图像,每幅配有详细的专家描述。在该数据集上,Geo‑TCAM明显优于若干强大的图像描述系统,包括流行的AoANet和大型视觉—语言模型。根据不同评测指标,其分数较基线最高提升了约120%,人工评估者在准确性、流畅性和细节丰富度方面压倒性地更倾向其生成的描述。重要的是,当同一模型在常见的日常照片集合(COCO数据集)上评估时,它仍与领先方法具有竞争力,表明其设计既强大又具通用性。
这对遗产保护及更广领域的意义
对非专家而言,主要结论是Geo‑TCAM能够将视觉上复杂的唐卡画转化为清晰、信息量大的叙述,突出描绘对象是谁、他们在做什么以及这些细节为何重要。通过融合分层视觉分析、来自专家文本的主题学习以及对面部与手势的特殊关注,该系统的描述更贴近人类专家解读这些艺术品的方式。长期来看,此类工具可为数字档案、博物馆导览和教育平台提供支持,使深奥的宗教艺术更易接近,同时帮助文物修复者和学者记录并保护脆弱的文化珍品。
引用: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
关键词: 唐卡图像描述, 文化遗产人工智能, 视觉注意力, 主题建模, 艺术保护