Clear Sky Science · zh
二十四史古今词性标注语料库的构建
在人工智能时代古代编年史为何重要
两千多年来,中国史家在被称为二十四史的浩瀚典籍中记录战争、朝廷、饥荒与日常生活。今天,这些经典不仅被学者重新审视,也正被计算机所重新发现。本研究介绍了研究者如何将这些古代编年史及其现代中文译文转化为经精心标注的语言数据库。该资源可以帮助人工智能更准确地阅读、翻译和分析历史文本——并让遥远的过去对公众更易接近。
从尘封卷帙到数字文本
项目从一项基础但艰巨的任务开始:将数百万印刷字符转为清洁、准确的数字文本。团队利用两类来源——权威的现代二十四史版本和大型在线文本集——喂入光学字符识别系统。随后他们细致地删除乱码段落、修正识别错误的字,并剔除页眉页脚等噪音。最终得到一组平行文件,一份为古文,一份为现代文,忠实对应原书且已准备好用于计算分析。 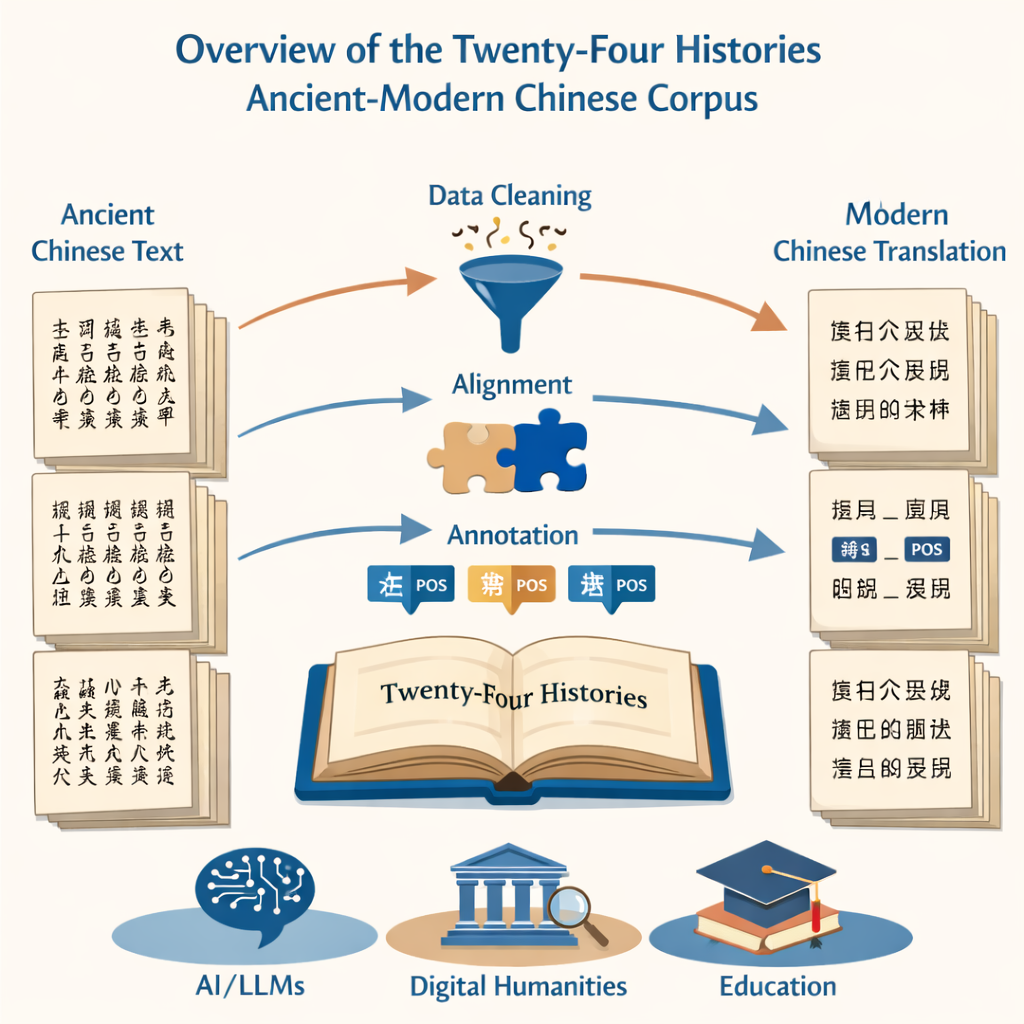
将古句与今句配对
因为目标是比较语言随时间的变化,逐句对应古今版本至关重要。研究者先用专门的对齐软件匹配段落,再将其拆分为对应的句子。自动化工具完成了大量工作,但每一对建议的句子都由人工专家复核——古汉语语法与现代汉语可能大相径庭。对于软件出错之处——把意念错误拆分或错认字形——注释员参照原始扫描页进行核对并修正数字文本,以确保每一句古文都能与其现代对应句整齐对齐。
教计算机识别语法
除了简单的转录,项目的核心是语法标注。古今两份文本中的每个词都被标注词性,表明它是名词、动词还是时词等。由于对古汉语尚无统一标准,团队以现代国家规范为基准并据此适配古用法。他们设计了一个含22个标签的方案,其中包括对诸如“使生”或“死国”之类古代特有动词用法的特殊标签。定制的神经网络——建立在古文语言模型与序列标注层之上——生成初始标签,随后由大量训练有素的研究生团队审校修正。注释员间的严格一致性测试显示高度一致,证明最终的标注语料既庞大又可靠。
这面新镜子揭示了什么
在标注语料就绪后,作者考察了其显现的一些模式。古汉语以单字词为主,反映出众所周知的高度简约书写风格,而现代汉语偏好双字词。古文中最常见的词多为小型虚词,如“之”“以”,而动词与普通名词在两个时期合计约占词汇总数的一半。数据还展示了哪些词倾向于共同出现——例如描述官员、军队或外交使团的结构。通过对比古今句对的词性标注,团队追踪到功能如何随时间发生转移:一些古代的介词和副词如今对应完整的现代动词,部分动词则固化为固定的头衔或法律术语。一个案例研究提取了所有地名并绘制各朝代的聚集图,揭示政治与经济中心如何从西北转向江南及更远地区。 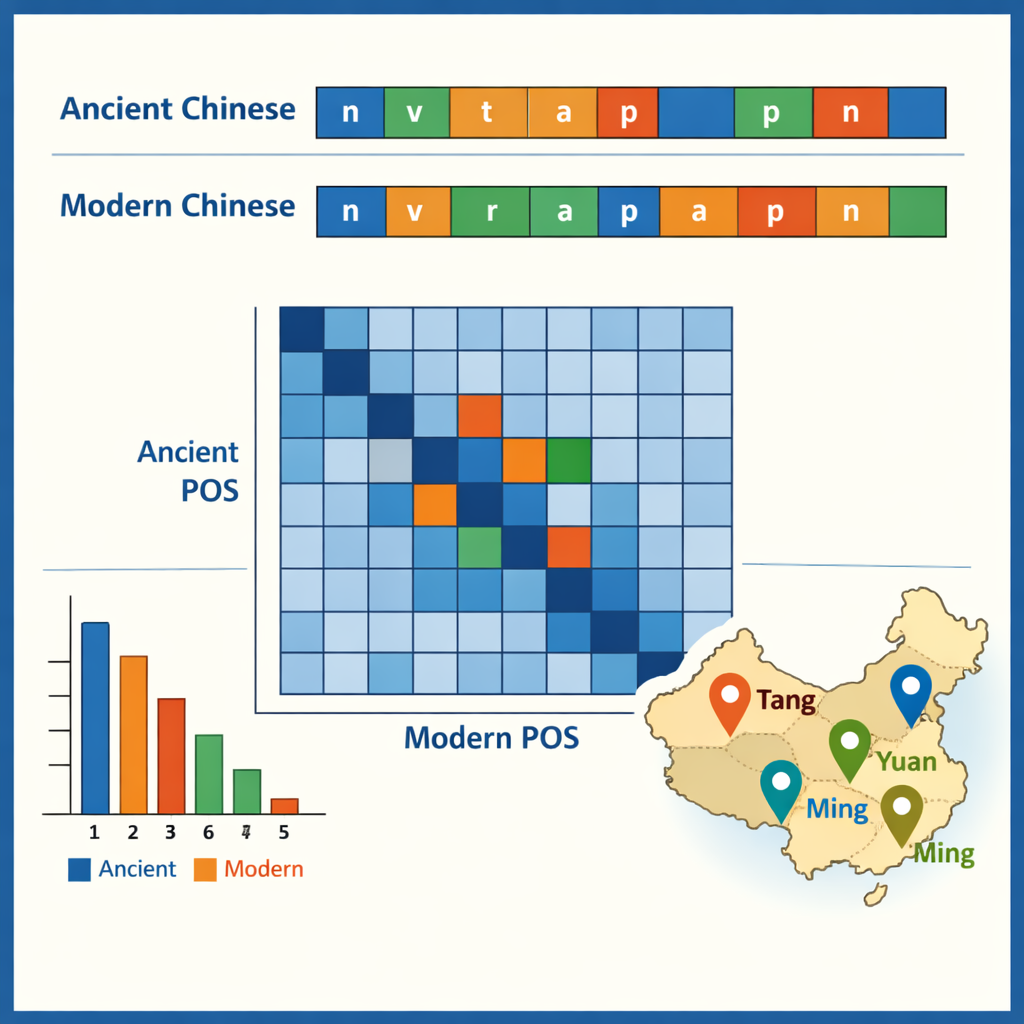
将过去带入数字未来
通俗地说,该项目把浩繁的古典散文转化为结构化数据,便于人类与机器导航。对于历史学家和语言学家,它提供了一个强有力的工具,以追踪词汇、语法乃至国界如何跨世纪演变。对于人工智能开发者,它提供了高质量的训练素材,使得语言模型能真正处理古典汉语,而不是将其视为字符的混杂。对于学生与普通读者,逐句配对的古今文本降低了阅读经典的门槛。通过对二十四史进行精确标注与对齐,作者搭建起一座从手写古卷到当代智能系统的桥梁。
引用: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
关键词: 古汉语语料库, 词性标注, 数字人文, 平行文本, 历史语言变化