Clear Sky Science · tr
3D Sihirli Ayna: nedensel bakış açısıyla tek bir görüntüden kıyafet yeniden yapılandırma
Deneme kabini olmadan kıyafet denemek
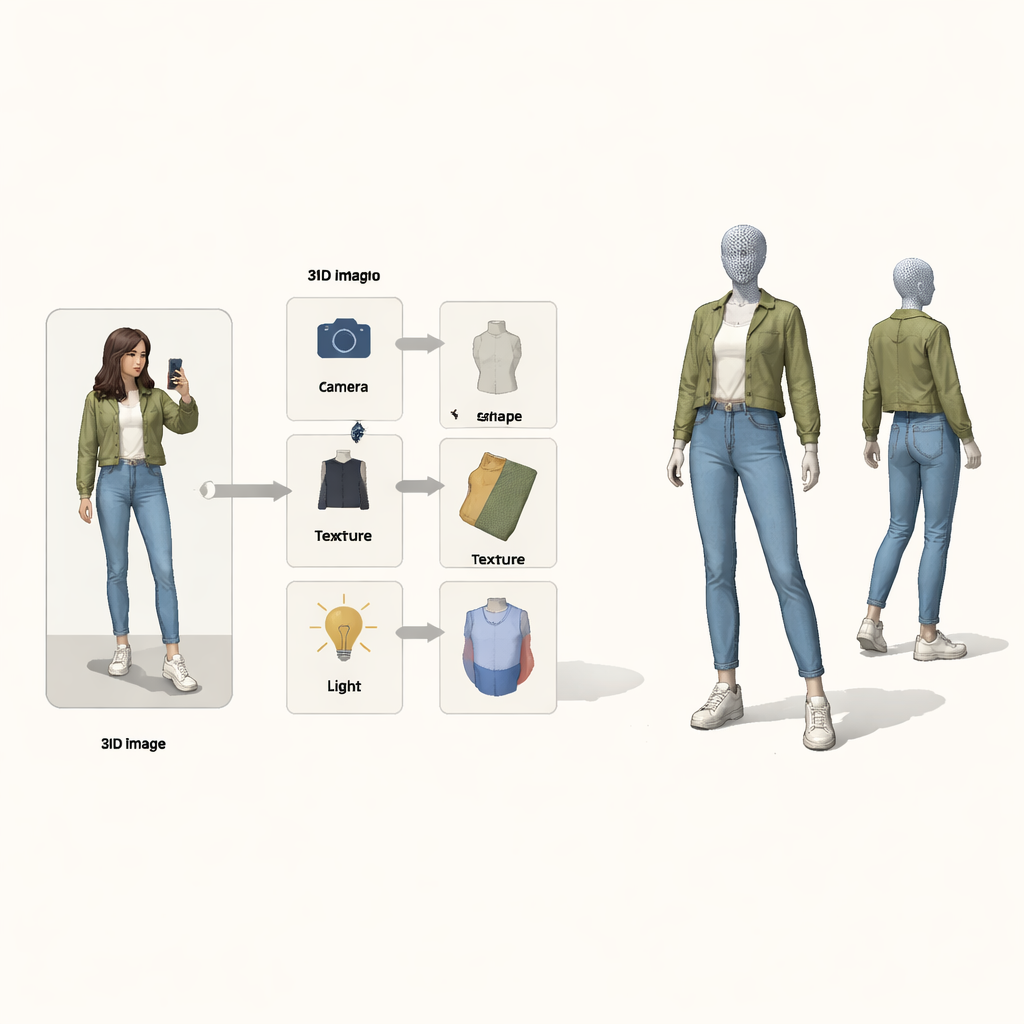
Telefonunuzla tek bir tam vücut fotoğrafı çekip anında kendinizi 3B olarak görmek, görüntüyü döndürebilmek, bakış açılarını değiştirebilmek veya hatta bir arkadaşla kıyafetleri değiştirebilmek hayal edin. Bu makale o “3D Sihirli Ayna”nın ardındaki temel teknik problemi ele alıyor: tek bir sıradan 2B giyimli insan fotoğrafını, pahalı 3B taramalar veya kontrollü stüdyo fotoğrafları gerektirmeden kıyafetin ayrıntılı bir 3B modeline dönüştürmek.
2B fotoğrafları 3B’ye çevirmek neden bu kadar zor
Düz bir görüntüyü 3B bir nesneye dönüştürmek klasik bir bilmece. Mevcut sistemler genellikle sabit bir dijital vücut şablonuyla başlar ve fotoğrafa uyması için onu bükmeye çalışır. Bu, kollar ve bacaklar gibi sert parçalar için oldukça iyi işler, fakat akışkan elbiseler, dökümlü paltolar, saç veya çantalar gibi basit, standart bir şekli izlemeyen öğelerde başarısız olur. Bir diğer engel veri: internette milyonlarca moda fotoğrafı var ama üzerinde eğitim yapılacak hassas ölçülmüş büyük 3B giysi koleksiyonları neredeyse hiç yok. Son olarak, tek bir fotoğraf önemli bilgileri saklar. Kameraya yakın küçük bir palto, uzaktaki daha büyük bir paltoyla aynı görünebilir; aydınlatma ve kumaş desenleri de öğrenme algoritmasını yanıltabilir. Bu belirsizlikler, bir sinir ağının doğru 3B yapıyı “tahmin etmesini” zorlaştırır.
Yapay zekâyı nedeni etkiden ayırmayı öğretmek
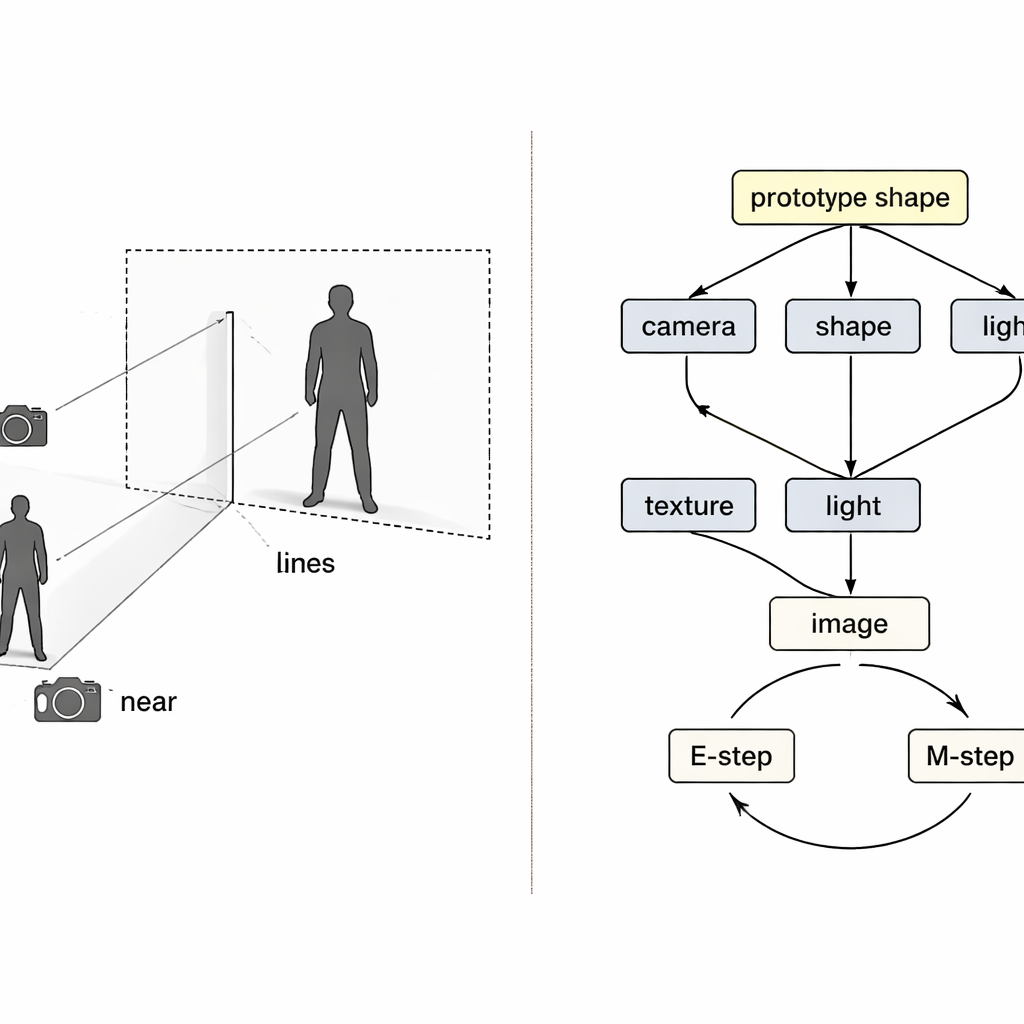
Sorunu piksellerden 3B’ye kara kutu eşlemesi olarak ele almak yerine yazarlar nedensel akıl yürütmeden—sebep ve sonuç matematiğinden—fikir ödünç alıyor. Nihai görüntüyü dört gizli sebebin sonucu olarak görüyorlar: kameranın konumu, kıyafetin şekli, dokusu (renkleri ve desenleri) ve aydınlatma. Özel bir “yapısal nedensel harita” bu faktörlerin gözlenen görüntüyü nasıl beraber oluşturduğunu ortaya koyuyor. Bu harita rehberliğinde sistem, her biri bir faktörden sorumlu dört ayrı sinir kodlayıcı kullanıyor. Fizikten ilham alan 3B bir render ile birlikte bunlar bir döngü oluşturuyor: görüntü ve ön plan maskesi giriyor, renkli bir 3B ağ çıkıyor ve sonra orijinalle karşılaştırılabilen bir görüntüye projekte ediliyor.
Her seferinde bir şeyi düzelten öğrenme döngüsü
Ayrı kodlayıcılar olsa bile eğitim yanlış gidebilir. Yeniden yapılandırma kusurluysa hangi kodlayıcının suçlu olduğu belirsizdir ve sıradan öğrenme eğilimi hepsini birden ayarlamaktır. Yazarlar bunu nedenlerin birbirini yanlış şekilde dengeleyebildiği klasik bir “çarpıştırıcı” (collider) problemi olarak ele alıyor. Çözüm, eğitime iki beklenti–maksimizasyon döngüsü dokumak oluyor. İlk döngüde üç kodlayıcı geçici olarak donduruluyor ve yalnızca dördüncü güncelleniyor; böylece hatalar açıkça atfediliyor ve o bileşen daha temiz bir rol öğreniyor. İkinci döngüde, başlangıçta basit bir küre olan paylaşılan bir “prototip” 3B şekil yavaşça verideki ortalama insan veya kuş şekline güncelleniyor. Bireysel örnekler bu prototipten yalnızca küçük sapmaları öğrenirken, kamera modülü nesnenin ne kadar büyük veya yakın göründüğünden tamamen sorumlu oluyor ve böylece boyut–mesafe karışıklığına doğrudan saldırıyor.
Moda fotoğraflarından kuşlara ve ötesine
Yaklaşımlarını test etmek için araştırmacılar sıradan sokak fotoğrafları içeren iki büyük moda veri kümesi ve standart bir kuş görüntü koleksiyonunda eğitiyorlar. Önemli olarak, yalnızca 2B ön plan maskeleri kullanıyorlar, 3B yer-gerçeği ağlar (ground-truth meshes) değil. İnsan kıyafetlerinde sistemleri, giysilerin gerçek dış hatlarını eşlemede popüler vücut-şablon yöntemlerinden daha iyi performans gösteriyor ve saç ve çantalar gibi esnek öğeleri daha sadık şekilde ele alıyor. Kuşlarda, önde gelen tek-görsel 3B yeniden yapılandırma yöntemlerinin kalitesine ulaşıyor veya onları aşıyor ve daha gerçekçi yeni bakış açıları üretiyor. 3B modeller, insanların kıyafet dokularını birbirleriyle değiştirmek veya gözetim araştırmalarında kullanılan kişi yeniden tanıma sistemlerini güçlendirmek için sentetik eğitim verisi üretmek gibi eğlenceli uygulamaları destekleyecek kadar esnek.
Günlük dijital dünyalar için bunun anlamı
Uzman olmayanlar için temel mesaj şudur: inandırıcı 3B avatarlar ve sanal provadan geçirme araçları artık maliyetli 3B tarayıcılar veya sert şablonlar gerektirmiyor. Kamera, şekil, doku ve ışığı açıkça modelleyip bunları paylaşılan bir prototipe sabitleyerek yazarlar, bir sistemin tek bir fotoğrafı nasıl bir 3B sahne olarak “açıklayabileceğini” gösteriyor. Yöntem hâlâ daha önce hiç görmediği bakışlarla, örneğin yalnızca önünden fotoğraflanmış bir kişinin sırtı gibi durumlarla zorlanıyor, ancak gerçekte çektiğimiz dağınık, vahşi ortamdaki görüntüler üzerinde çalışan pratik 3D Sihirli Aynalara doğru önemli bir adım işaret ediyor.
Atıf: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Anahtar kelimeler: sanal provadan geçirme, 3B yeniden yapılandırma, nedensel öğrenme, bilgisayarlı görme, moda yapay zekâsı