Clear Sky Science · tr
Acil bakımda büyük dil modellerinin rolü: kapsamlı bir kıyaslama çalışması
Bu, acil servise gidebilecek herkes için neden önemli
Acil servisler her zamankinden daha yoğun; bekleme süreleri uzuyor ve kritik derecede hasta sayısı artarken bakım verecek personel azaldı. Bu çalışma hemen hemen herkesi ilgilendiren bir soruyu ele alıyor: modern yapay zeka sistemleri, yani büyük dil modelleri, acil serviste doktorlar ve hemşirelerin daha hızlı ve daha akıllıca çalışmasına güvenli biçimde yardımcı olabilir mi? Araştırmacılar, önde gelen birkaç yapay zekâyı çeşitli tıbbi testler ve simüle edilmiş acil vaka senaryolarından geçirerek bu araçların acil bakımda “eş-pilot” olarak güvenilir hale gelmeye ne kadar yaklaştığını inceliyor.
Acil servislerin yoğun baskı altında olması
Makalede öncelikle özellikle Amerika Birleşik Devletleri’nde acil bakımda artan bir krizin tablosu çiziliyor. Yaşlanan nüfus ve kronik hastalıkların artışı, yalnızca 2022’de yaklaşık 155 milyonu aşan rekor düzeyde acil servis başvurusuna yol açıyor. Aynı zamanda hastaneler hemşire ve hekim eksikliğiyle karşı karşıya ve kişi başına düşen yatak sayısı son yıllarda azaldı. Parçalanmış bir sağlık sistemi, bakım koordinasyonunu zorlaştırıyor ve gecikme ile hata riskini artırıyor. Bu zeminde yazarlar, klinisyenlere hastaları triyaj etme, hızlı karar alma ve belgelemeyi iş yüklerini artırmadan yapma konusunda yardımcı olacak yeni araçlara acil ihtiyaç olduğunu savunuyor.
Araştırmacılar tıbbi yapay zekâyı nasıl test etti
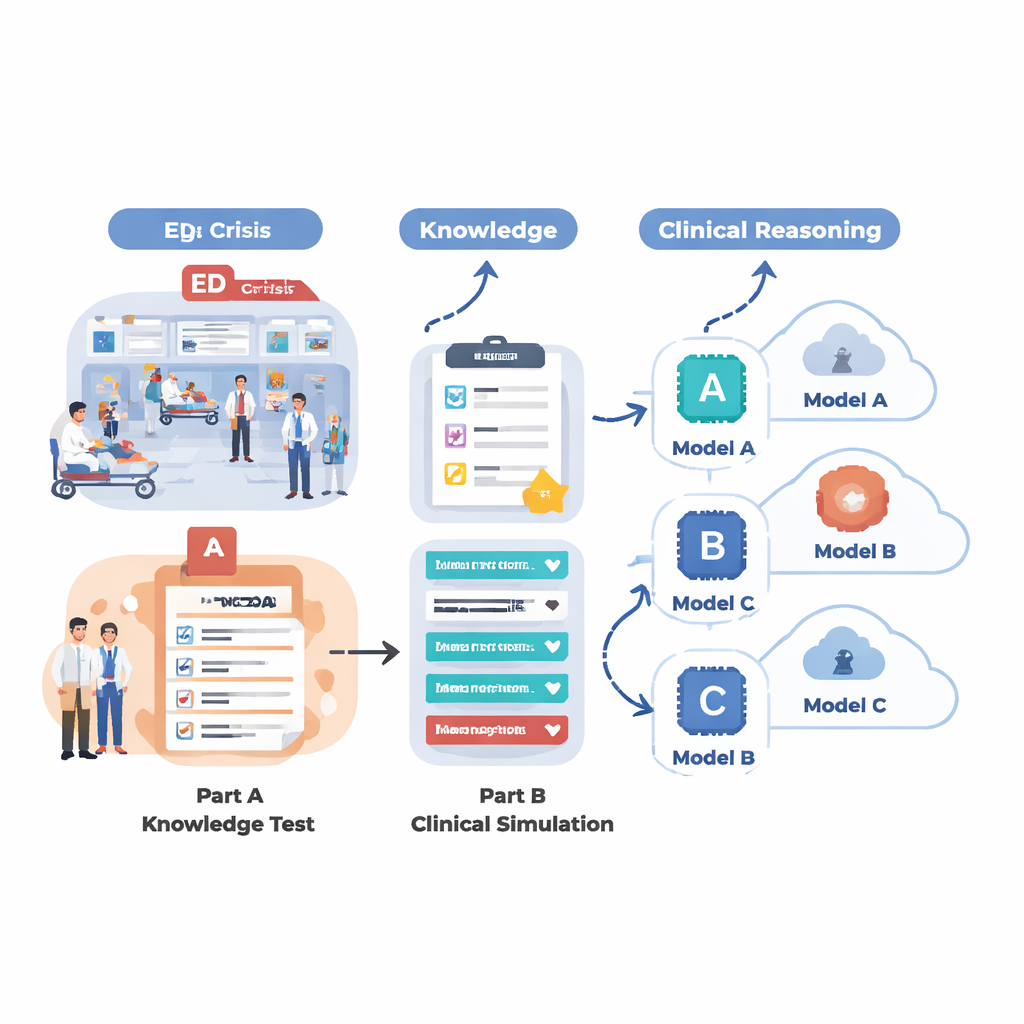
Günümüz yapay zekâ sistemlerinin acil servis benzeri bir ortamda gerçekten neler yapabildiğini görmek için ekip iki aşamalı bir değerlendirme tasarladı. İlk olarak, 18 farklı dil modelini MedMCQA’dan alınmış çoktan seçmeli sorulardan oluşan geniş bir set üzerinde test ettiler; bu veri seti göğüs ağrısı, nefes darlığı, baş ağrısı ve karın ağrısı gibi 12 yaygın acil şikâyeti kapsıyordu. Bu aşama temel tıbbi bilgiyi ölçtü: yapay zekâ binlerce soru arasında dört seçenekten doğru cevabı seçebiliyor muydu? İkinci olarak, o turdan en güçlü beş modeli alıp bir doktor gibi adım adım çalıştırdılar: 12 gerçekçi acil vaka üzerindeki performansları değerlendirildi. Her vaka için yapay zekâ hastayı özetlemeli, bir triyaj aciliyet skoru atamalı, önemli takip sorularını önermeli, yönetim adımlarını teklif etmeli ve yeni bilgiler (vital bulgular, öykü, muayene bulguları, laboratuvar ve görüntüleme sonuçları) kademeli olarak açığa çıktıkça olası tanıları sıralamalıydı.
Hangi yapay zekâlar bilgiyi biliyordu—hangileri akıl yürütebiliyordu
Saf bilgi hatırlama açısından birkaç model etkileyici performans gösterdi. LLaMA 4 Maverick adındaki uzmanlaşmış bir sistem tıbbi sorulardaki genel doğrulukta yaklaşık yüzde 91 puan aldı; bunu LLaMA 3.1, GPT-4.5, GPT-5 ve Claude 4 izledi. Bu üst düzey modeller farklı başa gelen şikâyetlerde tutarlı biçimde güçlüydü, bu da sınırdaki yapay zekâların ders kitabı tarzı tıbbi bilgide bir tavan noktasına yaklaşabileceğini düşündürüyor. Orta seviye sistemler oldukça geride kaldı; bazıları yaklaşık yüzde 60 civarında puan aldı ve yara bakımı ile solunum sorunları gibi kilit alanlarda zorlandı. Ancak görev, izole sorulara cevap vermekten zengin, gelişen hasta öykülerinde akıl yürütmeye kaydığında farklar daha belirgin hale geldi. Bu klinik simülasyonlarda GPT-5 açıkça öne çıktı: en doğru ve eksiksiz özetleri üretti, en yardımcı takip sorularını sordu, mantıklı ve güvenli sonraki adımları önerdi ve olası tanıların en ayrıntılı ve iyi sıralanmış listelerini sundu.
Güçlü yönler, zayıflıklar ve güvenlik endişeleri
Klinisyenler her bir yapay zekânın çıktısını doğruluk, alaka ve güvenlik açısından dikkatle puanladı. GPT-5 yalnızca en yüksek puanları almakla kalmadı; vakalar daha karmaşık hale geldikçe performansı sabit kalan veya iyileşen tek modeldi ve hezeyanlar ile ciddi hataları yaklaşık yüzde 2’nin altında tuttu. Diğer modellerde belirgin zayıflık örüntüleri görüldü. Bazıları ikincil tanıları kaçırma veya önemsiz sorunları tehlikeli olanların önüne koyma eğilimindeydi. Diğerleri aşırı temkinli veya belirsizleşiyor ya da tek bir tanıya çok çabuk odaklanıyordu. Genel olarak çoğu sistem triyaj seviyelerini atarken hastaların ne kadar hasta olduğunu olduğundan düşük tahmin etme eğilimindeydi; düzeltilmezse bu koruyucu yanlılık acil bakımın gecikmesine yol açabilir. Bulgular önemli bir noktayı vurguluyor: tıbbi gerçekleri bilmek, bu gerçekleri eksik, dağınık ve değişen bilgilerle güvenli, adım adım kararlara dönüştürmekle aynı şey değil.

Bu, gelecekteki acil servis ziyaretleri için ne anlama gelebilir
Yazarlar, birkaç modern yapay zekânın artık birbirleriyle tıbbi bilgi bakımından rekabet ettiğini, özellikle GPT-5’in ise acil servislerde karar desteği aracı olarak faydalı olabilecek yeni bir akıl yürütme düzeyini gösterdiğini sonuca bağlıyor. Bu sistemlerin klinisyenlerin yerini almak ya da kendi başlarına hareket etmek için hazır olmadığını vurguluyorlar. Bunun yerine en umut verici kısa vadeli rolün denetimli bir asistan olarak hizmet etmek olduğunu belirtiyorlar—triyaj hemşirelerinin aciliyeti tahmin etmesine yardımcı olmak, hasta özetleri hazırlamak, soru veya test önermek ve ciddi tanıların gözden kaçıp kaçmadığını kontrol etmek gibi. Çalışma ayrıca canlı klinik ortamlarda daha fazla araştırma yapılması, güçlü güvenlik kontrolleri ve kullanım için net kurallar gerektiğini vurguluyor. Hastalar için mesaj temkinli bir iyimserlik: Yapay zekâ tıbbi sorunları düşünmede daha iyi hale geliyor, ancak acilde güvenli kullanımı dikkatli tasarım, denetim ve doktorlar ile hemşirelerin insan yargısını desteklemeye—yerine geçmemeye—devam eden odaklanmaya bağlı olacaktır.
Atıf: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Anahtar kelimeler: acil tıp, büyük dil modelleri, klinik karar desteği, triyaj, tıbbi yapay zeka kıyaslaması