Clear Sky Science · tr
Büyük dil modelleri için yapılandırılmış dinamik istemleme ve getiri arttırılmış üretim ile az örnekli adlandırılmış varlık tanımayı iyileştirme
Tıbbi metinleri daha akıllıca okumanın önemi
Modern tıp, yoğun bakım notlarından ilaç kullanımıyla ilgili çevrimiçi konuşmalara kadar okyanuslarca metin üretiyor. Bu kelimelerin içinde hastalıklar, tedaviler ve yan etkilere dair hayati ipuçları saklıdır. Bu bilgi parçacıklarını otomatik olarak bulup etiketleme—"adlandırılmış varlık tanıma" olarak adlandırılan görev—araştırmacıların salgınları takip etmesine, ilaç problemlerini daha erken fark etmesine ve doktorlara gerçek zamanlı destek sağlamasına yardımcı olabilir. Ancak geleneksel sistemler büyük el ile etiketlenmiş veri kümelerine ihtiyaç duyar; bunlar oluşturması maliyetli ve nadir ya da yeni sağlık sorunları için genellikle eksiktir. Bu çalışma, bugün chatbotların arkasındaki büyük dil modellerinin dikkatle tasarlanmış istemler ve örneklerin akıllı getirimi ile yönlendirildiğinde, yalnızca birkaç açıklamalı örnek olduğunda bile bu etiketleme görevini nasıl iyi yapabileceğini araştırıyor.
Makinelere önemli kelimeleri tespit etmeyi öğretmek
Yazarlar, metinde hastalık, ilaç, semptom ve sosyal etkiler gibi biyomedikal varlıkların anılarını bulmaya odaklanıyor. Bu zor bir iş çünkü tıbbi dil son derece uzmanlaşmıştır, hastane veya alt alanlara göre değişir ve genellikle herhangi bir veri kümesinde yalnızca birkaç kez görünen nadir durumları içerir. Mevcut makine öğrenimi modelleri insan benzeri performans gösterebilir ancak tipik olarak oluşturulması ve paylaşılması özellikle sıkı gizlilik kuralları altında pahalı olan büyük, iyi etiketlenmiş korpuslara ihtiyaç duyar. Az-örnekli öğrenme—modellerin yalnızca birkaç etiketli örnekten öğrenmesi—bu darboğazın etrafından dolaşmanın bir yolunu sunar. Büyük dil modelleri burada özellikle umut vericidir çünkü iç ağırlıklarını yeniden eğitmeden istemde verilen talimatlar ve örneklerden doğrudan desenleri öğrenebilirler.
Dil modelleri için daha iyi talimatlar oluşturmak
Çalışmanın ilk kısmı, modele her etiketlemesi gereken cümle için tekrar kullanılabilir bir talimat ve örnek blok olarak sunulan son derece yapılandırılmış bir "statik" istem tasarlar. Modele sadece varlıkları etiketlemesini söylemek yerine, istem altı öğeye ayrılır: açık bir görev açıklaması ve varlık türlerinin tanımları; veri kümesinin kaynağı ve teması hakkında kısa bir açıklama; her varlığa tipik yüksek frekanslı örnek kelimeler; isteğe bağlı arka plan tıbbi bilgi; önceki model hatalarından özetlenmiş geri bildirim; ve birkaç tamamen açıklamalı örnek cümle. Ekip bu çerçeveyi GPT-3.5, GPT-4 ve LLaMA 3-70B olmak üzere üç büyük dil modeliyle, klinik kayıtlar, bilimsel özetler ve opioid kullanımı hakkında Reddit gönderilerini kapsayan beş biyomedikal veri kümesinde test etti. Bu bileşenleri dikkatle katmanlamak, temel bir isteme kıyasla F1 skorlarını (kesinlik ve çağırmanın dengesi) yaklaşık 11–12 puan artırdı ve genel olarak en iyi performansı GPT-4 sergiledi.
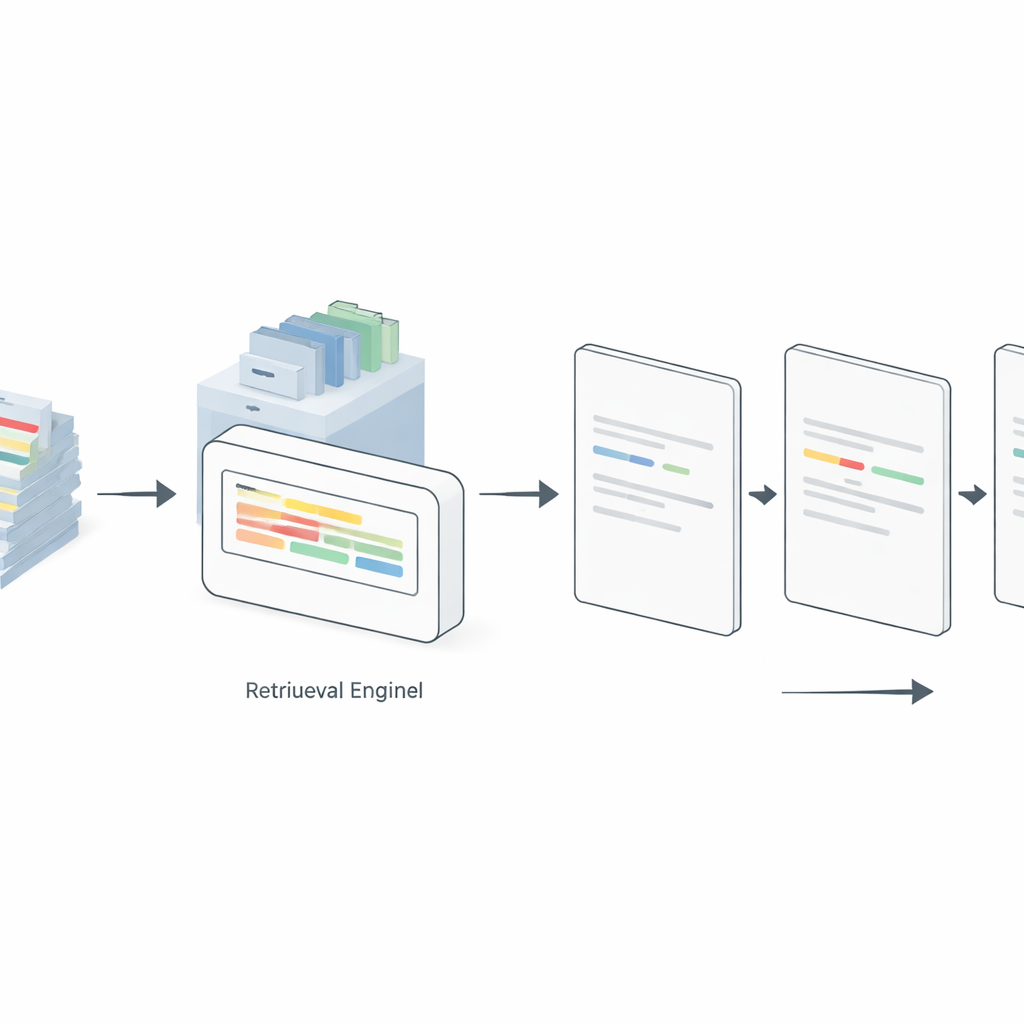
Modelin daha iyi örneklere anında bakmasına izin vermek
Ancak statik istemler her zaman aynı örnekleri gösterir; bunlar yeni etiketlenecek cümleyle kötü eşleştiğinde sorun olur. Buna çözüm olarak yazarlar, getiri-arttırılmış üretimle desteklenen bir "dinamik" istem stratejisi sunuyor. Burada ayrı bir getiri motoru mevcut tüm açıklamalı örnekleri dizinler. Her yeni giriş cümlesi için sistem bu havuzu arayarak en benzer etiketli cümleleri bulur ve yalnızca bunları isteme ekler. Çalışma, basit bir terim-frekansı şeması (TF–IDF) ile Sentence-BERT (SBERT), ColBERT ve Dense Passage Retrieval gibi sinirsel gömme modelleri arasında birkaç getiri yöntemini karşılaştırıyor. GPT-4, LLaMA 3 ve GPT-OSS-120B adlı açık ağırlıklı bir model genelinde, ilgili örnekleri dinamik olarak seçmek 5-, 10- ve 20-örnekli ayarlarda statik istemleme yönteminden tutarlı şekilde daha iyi performans gösterdi. Şaşırtıcı şekilde, basit TF–IDF yöntemi özellikle daha temiz, daha standart veri kümelerinde sık sık daha karmaşık yaklaşımlarla eşleşti veya onları geride bıraktı; SBERT ise daha gürültülü sosyal medya metinlerinde parladı.
Daha az etiketli örnekle daha fazlasını elde etmek
Tıbbi metinleri etiketlemek maliyetli olduğundan, yazarlar ayrıca getiri motorunun işe yarar hale gelmesi için kaç etiketli örneği dizinlemesi gerektiğini inceledi. LLaMA 3-70B kullanarak getirilen havuzu 50 örnekten tüm eğitim setine kadar değiştirdiler. Genel olarak performans havuz büyüdükçe iyileşti, ancak kazançlar çabuk yassılaştı: yaklaşık 100–200 örneklik havuzlar, genellikle tüm mevcut verileri dizinlemenin neredeyse aynı doğruluğunu sağladı ve sıklıkla istatistiksel hata payı içindeydi. Bazı durumlarda çok büyük havuzlar performansı hafifçe düşürdü; muhtemelen daha alakasız veya kafa karıştırıcı örnekler eklemeleri ve istemi uzatmaları yüzündendi. Bu bulgular, güçlü bir dil modeli ve iyi tasarlanmış istemler ile eşleştirildiğinde, mütevazı bir etiketleme çabasının bile sağlam biyomedikal varlık tanıması üretebileceğini ve yöntemi nadir hastalıklar, yeni klinik kavramlar veya kısıtlı kaynaklara sahip kurumlar için uygulanabilir kıldığını öne sürüyor.
Gerçek dünya tıbbı için bunun anlamı
Genel olarak çalışma, büyük dil modellerinin yapılandırılmış istemler ve en alakalı önceki vakaları yüzeye çıkaran bir getiri sistemi sağlandığında, yalnızca birkaç açıklamalı örnek kullanarak metinden önemli tıbbi kavramları güvenilir şekilde seçebileceğini gösteriyor. GPT-4 en güçlü genel performansı sunarken, açık ve daha küçük modeller de aynı istem ve getiri reçetesinden önemli ölçüde fayda sağlıyor. Uygulayıcılar için bu, yeni bir varlık türü veya sağlık sorunu ortaya çıktığında her seferinde devasa veri kümeleri oluşturmaları gerekmediği anlamına geliyor; kompakt, özenle küratörlüğü yapılmış bir örnek seti ile akıllı istemleme genellikle yeterli olabilir. Sağlık sistemleri notları dijitalleştirmeye devam ettikçe ve hastalar deneyimlerini çevrimiçi paylaştıkça, bu tür verimli ve uyarlanabilir araçlar tıbbi metnin geniş, dağınık dünyasından klinik açıdan kullanışlı bilgileri ortaya çıkarmayı çok daha kolay hale getirebilir.
Atıf: Ge, Y., Guo, Y., Das, S. et al. Improving few-shot named entity recognition for large language models using structured dynamic prompting with retrieval augmented generation. npj Artif. Intell. 2, 39 (2026). https://doi.org/10.1038/s44387-025-00062-2
Anahtar kelimeler: biyomedikal adlandırılmış varlık tanıma, az-örnekli öğrenme, büyük dil modelleri, getiri-arttırılmış üretim, klinik metin madenciliği