Clear Sky Science · tr
Derin modeller için önkoşullandırılmış yaklaşık stokastik ADMM
Daha Akıllı Yapay Zeka İçin Daha Akıllı Eğitim
Sohbet botlarından görüntü üreticilere kadar modern yapay zeka sistemleri, eğitimi genellikle zor ve maliyetli olan devasa sinir ağlarıyla çalışır. Şirketler ve araştırmacılar veriyi birçok cihaz ve sunucuya yaydıkça, günün standart eğitim yöntemleri yavaşlayabiliyor, kararsızlaşıyor ya da gerçek dünya verisinin düzensizliğiyle başa çıkamıyor. Bu makale, PISA adını taşıyan bir yöntemin merkezinde yer alan yeni bir eğitim algoritmaları ailesini tanıtarak, daha az matematiksel varsayım gerektiren şekilde çok çeşitli derin modeller için daha hızlı ve daha güvenilir öğrenme vaat ediyor.
Mevcut Eğitim Yöntemlerinin Neden Zorlandığı
Çoğu derin öğrenme modeli, hatayı azaltan yönde model parametrelerini tekrar tekrar iten stokastik gradyan inişi türevleriyle eğitilir. Yıllar içinde Adam, RMSProp gibi birçok iyileştirme, adım büyüklüklerini uyarlayarak veya momentuma ekleme yaparak bu itmeleri daha akıllı hale getirmeyi amaçladı. Ancak bu yöntemler genellikle eğitim verisinin düzgünce karıştırıldığına, makineler arasında istatistiksel olarak benzer olduğuna ve belli matematiksel büyüklüklerin sınırlı kaldığına dair varsayımlar yapar. Pratikte, özellikle telefonlar veya uç cihazlar çok farklı veriler tuttuğunda görülen federe öğrenme gibi ortamlarda, bu varsayımlar sıkça ihlal edilir ve bu da yavaş yakınsama veya düşük performansla sonuçlanır.
Birçok Öğrenen Arasında Yeni Bir Koordinasyon Yolu
Yazarlar, büyük bir problemi paralel olarak çözülebilecek daha küçük parçalara bölme konusunda iyi olan alternatif bir optimizasyon çerçevesi olan çoğaltmalı değişkenlerin dönüşümlü yönelim yöntemi (ADMM) üzerine inşa ediyor. Ana katkıları olan PISA (önkoşullandırılmış yaklaşık stokastik ADMM), ADMM’nin güçlü yönlerini korurken tüm veriler üzerinde tam gradyan hesaplama veya pahalı matris ters çevirimleri gerektirme gibi tipik dezavantajlarından kaçınıyor. Bunun yerine PISA, her istemci veya çalışan düğümün yalnızca bir mini-batch veri kullanarak kendi model kopyasını güncellemesine izin veriyor ve ardından bu güncellemeleri merkezi bir değişken aracılığıyla koordine ediyor. Özenle tasarlanmış "önkoşullandırma" matrisleri, güncelleme yönlerini yeniden şekillendirerek öğrenmenin daha düzgün ve verimli ilerlemesini sağlıyor. 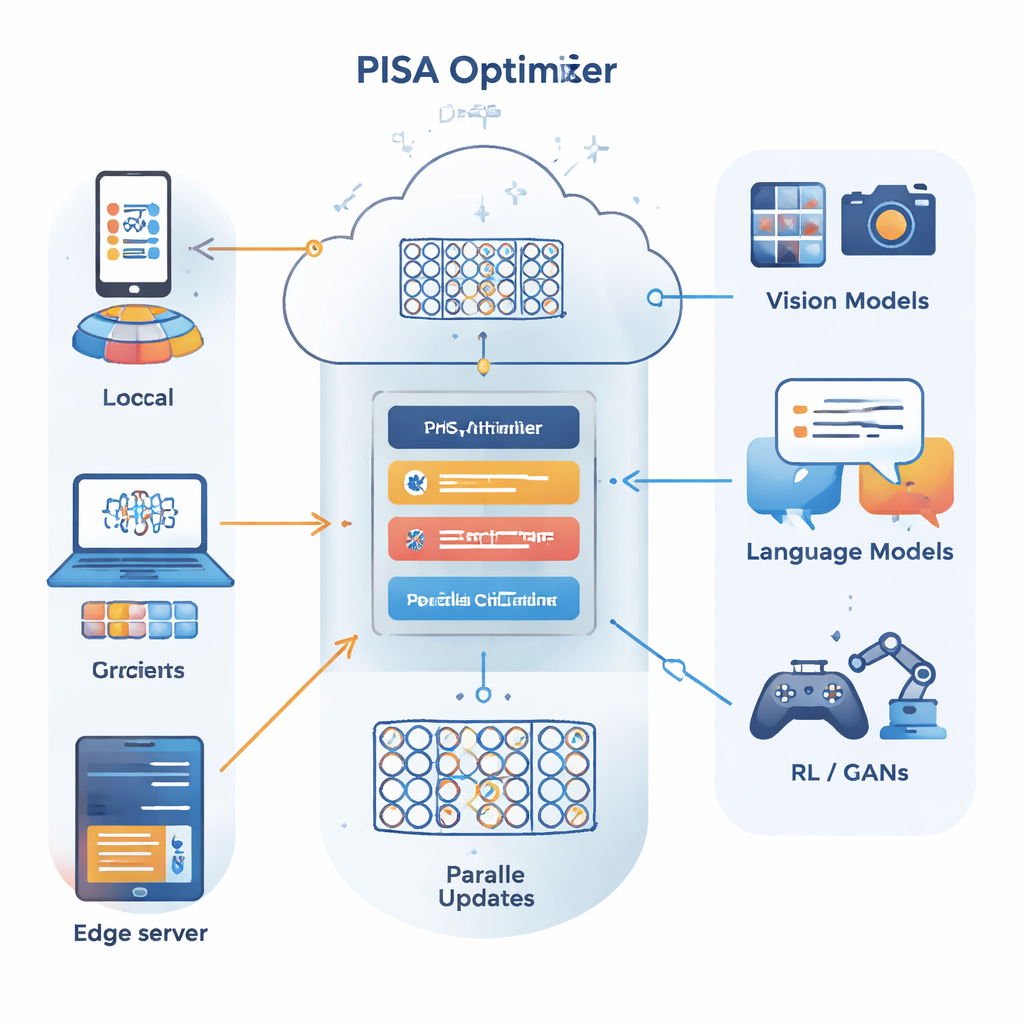
Daha Hafif Varsayımlarla Güçlü Garantiler
PISA’nın ayırt edici özelliklerinden biri de teorik dayanağıdır. Yazarlar, algoritmalarının tek ve nispeten hafif bir varsayım altında yakınsadığını kanıtlıyorlar: kayıp fonksiyonunun gradyanının sınırlı bir bölgede Lipschitz sürekliliği göstermesi—bu, birçok standart sinir ağı kaybı tarafından sağlanan bir koşuldur. Çoğu stokastik yöntemden farklı olarak PISA, gradyanların yanlısız olmasını, sınırlı varyansa sahip olmasını veya mükemmel karışmış verilerden çekilmesini gerektirmiyor. Bu gevşek düzenlemeye rağmen, yöntem fonksiyon değerleri ve parametre güncellemelerinin ne kadar hızlı stabil hale geldiği açısından doğrusal bir yakınsama hızı elde ediyor ve verilen karşılaştırma tablosunda en iyi performans gösteren algoritmalar arasında yer alıyor. Bu da PISA’yı, gerçek dünya dağıtımlarında yaygın olan heterojen ve düzensiz veri dağılımları için özellikle çekici kılıyor.
Gerçek Derin Ağlar İçin Pratik Varyantlar
Çerçeveyi büyük sinir ağları için pratik kılmak üzere yazarlar iki verimli varyant, SISA ve NSISA, öneriyor. SISA, temelde geçmiş güncellemelerin her parametre yönündeki büyüklüğünü izleyen ikinci moment bilgisini kullanarak basit diagonal önkoşullandırıcılar oluşturuyor; bu fikirler Adam ve RMSProp’un arkasındaki yaklaşımlara benziyor, ancak ADMM yapısı içine gömülü. NSISA ise Muon optimizatöründen esinlenen Newton–Schulz ortogonalizasyonu olarak bilinen bir tekniği dahil ederek momentumu parametre uzayındaki faydalı yönlerle daha iyi hizalıyor. Her iki varyant da PISA’nın yakınsama garantilerini korurken hesaplamayı modern GPU’lar ve büyük modeller için hafif tutuyor.
Görsel, Dil ve Üretici Modellerde Performans
Yazarlar SISA ve NSISA’yı geniş bir derin öğrenme görev yelpazesinde test ediyor. Etiket dağılımlarının kasıtlı olarak çarpıtıldığı federe öğrenme deneylerinde—her istemcinin yalnızca bazı sınıfları gördüğü zor bir ortam—SISA, FedAvg, FedProx, FedNova ve Scaffold gibi popüler yöntemleri çarpıcı şekilde geride bırakarak MNIST ve CIFAR-10 gibi ölçütlerde çok daha yüksek test doğruluğu elde ediyor. ResNet ve DenseNet gibi modellerle CIFAR-10 ve ImageNet üzerinde yapılan standart görüntü sınıflandırmasında SISA, momentumlu SGD, AdaBelief ve AdamW dahil güçlü optimizatörlerle eşleşiyor veya onları aşıyor. Artan boyuttaki GPT2 dil modellerini ince ayarlarken NSISA, Shampoo, SOAP, Adam-mini ve Muon gibi özel optimizatörlere kıyasla daha kısa duvar saati süresinde daha düşük doğrulama kaybı sağlıyor; en büyük modelde bu avantaj daha belirgin hale geliyor. Ayrıca üretici karşıt ağların eğitimini stabilize ederek, üretilen görüntülerin görsel kalitesini ve çeşitliliğini ölçen daha düşük Fréchet girişim uzaklığı skorları elde ediyor. 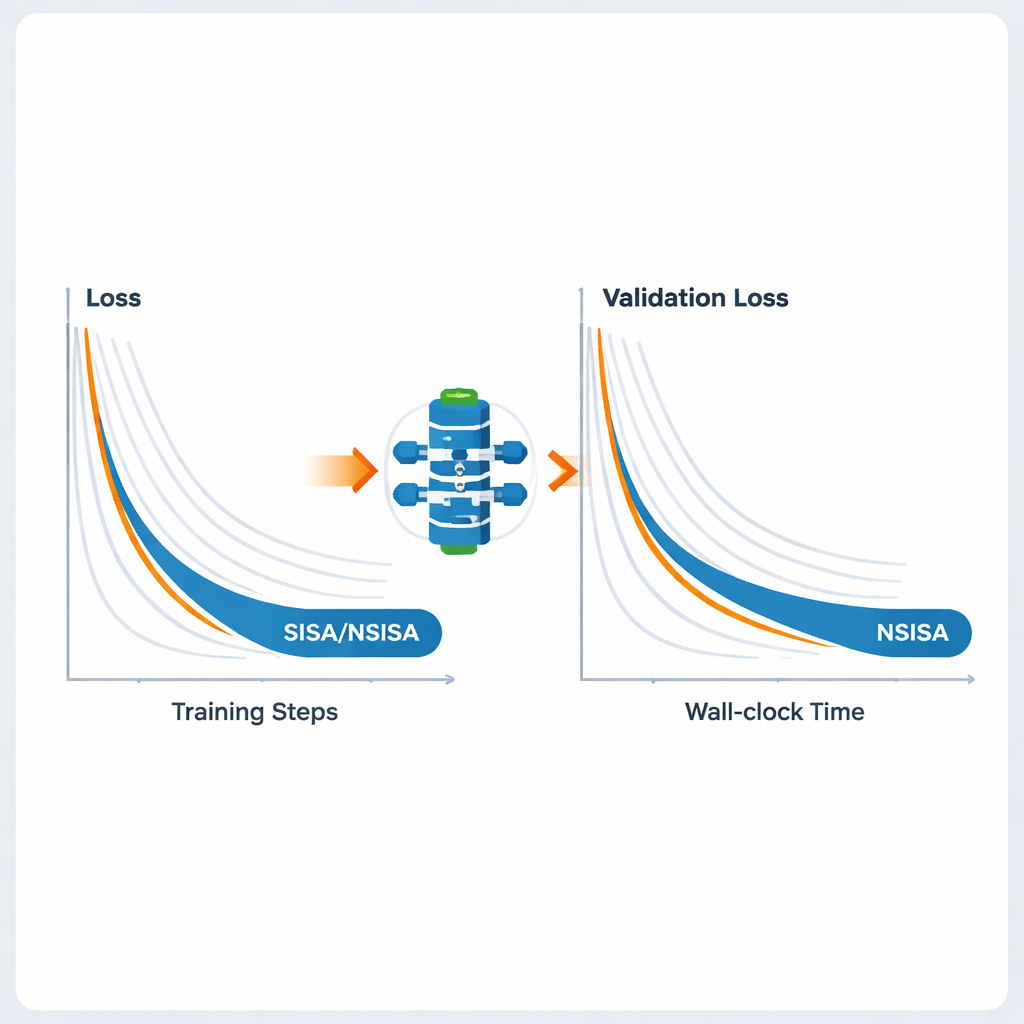
Günlük Yapay Zeka İçin Ne Anlama Geliyor
Basitçe söylemek gerekirse, bu çalışma güçlü yapay zeka modellerinin veriler dağınık, dengesiz veya dağınık olduğunda bile daha hızlı ve güvenilir şekilde eğitilebileceğini gösteriyor. Sadece öğrenme oranlarını ayarlamak yerine temel optimizasyon sürecini yeniden tasarlayarak, PISA ve varyantları görme, dil, pekiştirmeli öğrenme ve üretici görevler için iyi çalışan birleşik bir araç sunuyor. Son kullanıcılar için bunun getirisi, telefonlarda daha akıllı kişiselleştirme, daha yetenekli dil ve görüntü modelleri ve büyük veri merkezlerinde hesaplama kaynaklarının daha verimli kullanımı olabilir—bütün bunlar modern yapay zeka sistemlerinin gerçekleriyle daha iyi örtüşen bir eğitim algoritması sayesinde mümkün oluyor.
Atıf: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Anahtar kelimeler: derin öğrenme optimizasyonu, federe öğrenme, stokastik ADMM, büyük dil modelleri, heterojen veri