Clear Sky Science · tr
Büyük dil modelleri ne zaman empatik iletişimi değerlendirmede güvenilir olur
Makine Empatisi Neden Sizin İçin Önemli
İnsanlar giderek daha fazla stresli, yalnız ya da zor kararlarla karşı karşıya kaldıklarında sohbet botlarına ve dijital asistanlara başvuruyor. Bu sistemler ilgili ve anlayışlı gelebilir—ancak bir mesajın gerçekten destekleyici ve nazik olup olmadığını değerlendirebilirler mi? Bu makale, birçok sohbet botunun arkasındaki teknoloji olan büyük dil modellerinin (LLM’ler) yazılı bir yanıtın ne kadar empatik hissettirdiğini ne zaman güvenilir biçimde değerlendirebildiğini ve bunun sağlık uygulamaları, sanal terapistler ve müşteri hizmetleri botları gibi gündelik araçlar için ne anlama geldiğini inceliyor. 
Destekleyici Konuşmaları İncelemek
Araştırmacılar, bir kişinin iş stresi, aile çatışması, para kaygıları veya ruh sağlığı sorunları gibi kişisel bir problemi anlattığı ve başka bir kişinin destekleyici bir şekilde yanıt vermeye çalıştığı 200 gerçek metin tabanlı konuşmayı analiz etti. Bu konuşmalar, empatinin değerlendirilmesi için farklı soru setlerine bağlı dört mevcut veri kümesinden alındı. Bazıları yanıt verenin anlayış gösterip göstermediğine veya duygusal rahatlama sunup sunmadığına odaklanırken; diğerleri pratik tavsiye verip vermediğini, konuşmacıyı daha fazla konuşmaya teşvik edip etmediğini veya bunun yerine konuşmayı kendine mi çevirdiğini sorguluyordu. Birlikte, bu çerçeveler “empatik olmayı” müşteri memnuniyeti anketindeki gibi ölçeklerle puanlanabilecek 21 belirli davranışa ayırıyor.
Uzmanlar, Kalabalık ve Makineler
LLM’lerin empatiyi ne kadar iyi puanlayabildiğini görmek için ekip üç tür jüriyi karşılaştırdı: iletişim uzmanları, çevrimiçi kalabalık işçileri ve modern dil modelleri. Empatik iletişim alanında deneyimli üç akademisyen her konuşmayı bağımsız olarak tüm 21 davranış açısından değerlendirdi. Kalabalık işçiler—gündelik internet kullanıcıları—aynı mesajlar için önceki çalışmalarda zaten puanlar sağlamıştı. Son olarak, üç önde gelen dil modeli açık dil yönergeleri ve uzmanlardan alınan örnek puanlarla dikkatlice yönlendirildi ve ardından her konuşmayı aynı ölçeklerde puanlamaları istendi. Bu düzen, yazarların her grubun ne kadar yakın anlaştığını—sadece “doğru” bir cevapla değil, birbirleriyle ne kadar uyumlu olduklarını—ölçmesine olanak tanıdı. 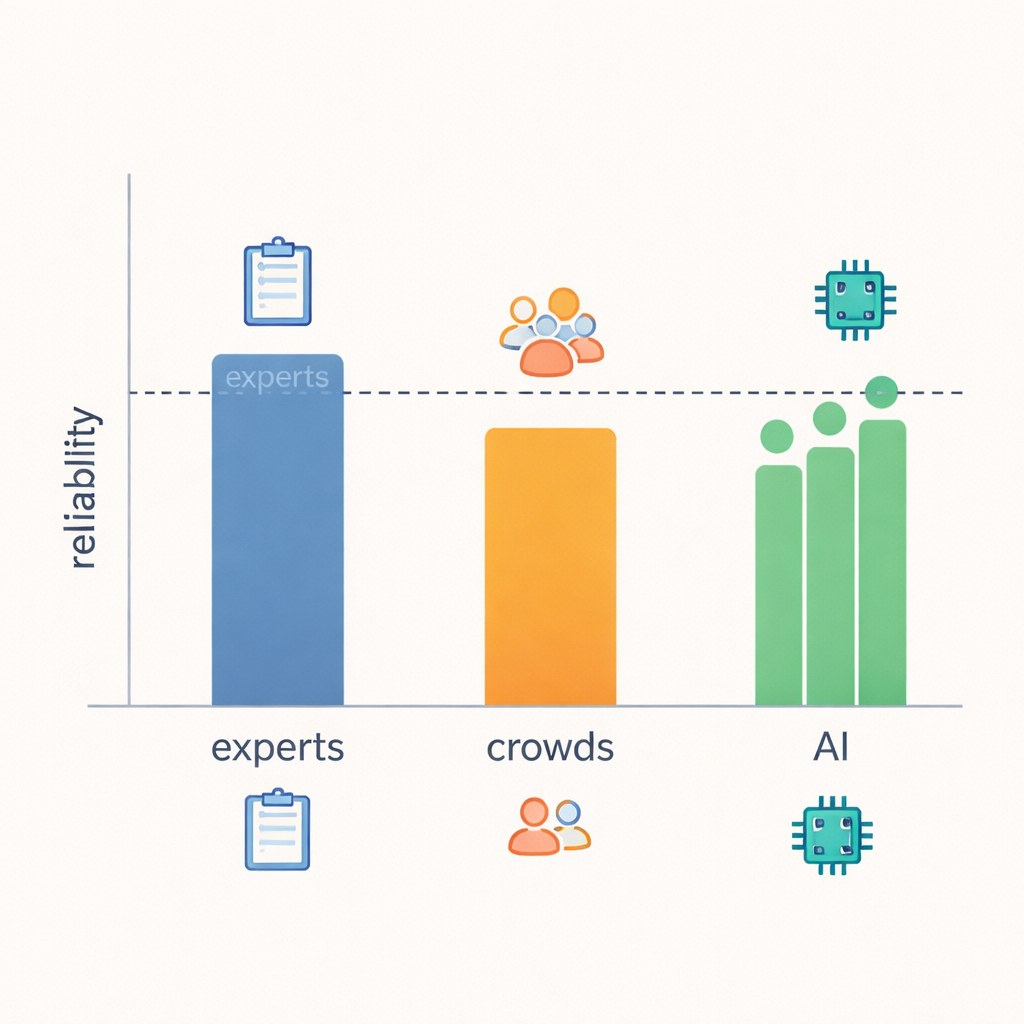
Ne Kadar Yakınlaşıyorlar?
Ana bulgu, LLM’lerin uzman düzeyinde güvenilirliğe şaşırtıcı derecede yakın çıktığı yönünde. Araştırmacılar puanların ne sıklıkla örtüştüğünü ve anlaşmazlıkların ne kadar büyük olduğunu ölçtüklerinde, modeller 21 davranışın çoğunda uzmanlarla eşleşti veya neredeyse eşleşti ve açık şekilde kalabalık işçilerden daha iyi performans gösterdi. Pratik tavsiye verilip verilmediği, takip soruları sorulup sorulmadığı veya dikkatin tekrar konuşmacıya çevrilip çevrilmediği gibi belirgin, gözlemlenebilir sinyallerin olduğu alanlarda uzmanlar, LLM’ler ve hatta kalabalıklar daha çok aynı fikirde olma eğilimindeydi. Ancak bir yanıtın gerçekten “anlayış gösterip göstermediği” ya da yanıt verenin niyetlerinin ne olduğu gibi daha bulanık fikirleri değerlendirirken, uzmanlar bile daha sık anlaşmazlığa düştü ve LLM güvenilirliği onların düşüşüyle birlikte azaldı. Bu, empatinin bazı yönlerinin sadece metinden tek başına saptanmasının daha zor olduğunu, kimin değerlendirdiğine bakılmaksızın gösteriyor.
Basit Puanlar Neden Yanıltıcı Olabilir
Birçok yapay zeka çalışması, her uzman puanını sorgulanamaz gerçek olarak ele alıp bir modelin ne sıklıkla buna uyduğunu ölçerek tanıdık sınıflandırma puanlarıyla başarı bildirir. Yazarlar, ince insan yargılarıyla uğraşırken bu yaklaşımın çarpık bir tablo çizebileceğini gösteriyor. Örneğin, bir sistem dengesiz bir ölçekte çoğunluk puanını çoğunlukla tahmin ederek iyi puan alabilir; oysa nadir ama önemli durumlarda zorlanıyor olabilir. Benzer şekilde, çoğunlukla “neredeyse doğru”—sadece bir puan sapma—puanları veren bir yöntem, katı bir eşleşme metriğinde kötü görünür; oysa davranışı bir insan uzmana çok benzeyebilir. Farklı değerlendiricilerin aynı şeyi ne kadar tutarlı puanladığına—yani değerlendirici güvenilirliğine—odaklanarak çalışma, hem insanların hem de makinelerin güvenilir biçimde neler değerlendirebileceğine dair daha dürüst bir bakış sunuyor.
Bu Günlük Yapay Zeka İçin Ne Anlama Geliyor
Bir sıradan kullanıcı için çıkarım hem umut verici hem de uyarıcı. İyi yapılandırılmış LLM’ler artık insan yardımcılar veya diğer botlar tarafından verilen yazılı yanıtların uzman empati standartlarını karşılayıp karşılamadığını kontrol etmeye yardımcı olabilir ve çoğu durumda eğitimsiz insan değerlendiricilerden daha tutarlı davranır. Bu, sağlık, eğitim ve müşteri hizmetlerinde kullanılan sohbet botlarını izlemeyi ve geliştirmeyi kolaylaştırabilir. Aynı zamanda çalışma, tüm “empati testlerinin” eşit yaratılmadığını da uyarıyor: belirsiz veya örtüşen sorular insan anlaşmasını sarsıyor ve bunun sonucunda makine yargılarını da zayıflatıyor. Duygusal destek gibi hassas bir şeyi yapay zekaya değerlendirmesi için güvenmeden önce, uzmanların kendilerinin “iyi”nin ne olduğunda anlaşabildiğinden emin olmalı ve makinelerin nerede güvenle yardımcı olabileceğini, nerede insan yargısının şart olduğunu bu kıstasa göre belirlemeliyiz.
Atıf: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Anahtar kelimeler: empatik iletişim, büyük dil modelleri, yapay zeka eşlikçileri, ruh sağlığı desteği, insan–yapay zeka etkileşimi