Clear Sky Science · tr
Federated learning ile dolaşan modelleri birleştirmek performansı artırıyor ve dijital sağlıkta eşitlik için fırsatlar açıyor
Verileri paylaşmadan tıbbi bulguları paylaşmanın önemi
Modern tıp, taramalar ve sağlık kayıtlarındaki örüntüleri bulmak için giderek daha fazla yapay zekâya dayanıyor. Ancak hasta verileri hassastır ve sıklıkla toplandıkları hastanenin dışına çıkarılamaz. Bu, önemli bir gerilim yaratıyor: ham hasta verilerini sınırlar-arası ya da büyük merkezî sunuculara göndermeden, dünya çapındaki hastaneler güçlü yapay zekâ araçları geliştirmek için nasıl iş birliği yapabilir? Bu çalışma, yalnızca doğruluğu hedeflemekle kalmayıp aynı zamanda iyi kaynaklandırılmış hastaneler ile daha küçük, az kaynaklı klinikler arasında adaleti sağlamayı amaçlayan yeni bir yöntemi tanıtıyor.
Verileri taşımadan bir yapay zekâyı eğitmenin iki yolu
Günümüzde, hastanelerin verileri yerinde tutarken birlikte yapay zekâ eğitmelerine izin veren iki ana strateji var. Federated learning’de her hastane paralel olarak modelin kendi yerel kopyasını eğitir; bu yerel modeller daha sonra merkezi bir sunucuda ortak bir “küresel” modelde birleştirilir. Dolaşan model yaklaşımında ise tek bir model hastaneden hastaneye gider ve her sahada sırayla eğitilir. Her iki yöntem de gizliliği korur, fakat her birinin dezavantajları vardır. Federated learning, bazı hastanelerin çok az veriye sahip olduğu veya tüm hasta türlerini görmediği durumlarda zorlanabilir; zayıf veya dengesiz yerel modellerin birleştirilmesi, ağırlıklı olarak büyük ve zengin merkezleri yansıtan zayıf bir küresel modele yol açabilir. Dolaşan model bu dengesizliklere karşı daha sağlam olabilir, ancak daha yavaş ve yönetilmesi daha zor olabilir.
Her iki yaklaşımın en iyilerini kullanan hibrit strateji
Yazarlar, federated learning ile dolaşan modelin güçlü yönlerini harmanlayan FedTM adlı hibrit bir eğitim şeması öneriyor. Eğitim iki aşamada gerçekleşiyor. İlk olarak, yalnızca daha eksiksiz ve dengeli veri kümelerine sahip en büyük hastanelerin standart federated learning teknikleriyle paralel olarak modeli eğittiği bir “ısıtma” aşaması geliyor. Bu, güçlü bir başlangıç modeli oluşturuyor. Ardından, bu ısıtılmış modelin her sahayı sırasıyla ziyaret ettiği bir “inceltme” aşaması geliyor; burada çok az sayıda beyin taramasına veya hatta yalnızca bir hastaya sahip çok küçük klinikler de dahil ediliyor. İkinci aşamada, model dolaşırken kademeli olarak güncelleniyor ve her siteden gelen bilgiyi, verilerin yerel kontrollerinin dışına çıkmasına gerek kalmadan kapsıyor.
Yöntemin Parkinson hastalığı beyin taramalarında test edilmesi
FedTM’yi sınamak için araştırmacılar, dünya genelindeki 83 görüntüleme merkezinden alınan 1.817 beyin MRI taramasını kullanarak bir yapay zekâyı Parkinson hastalığı olanları sağlıklı bireylerden ayırt edecek şekilde eğittiler. Bu, özellikle zorlu bir ortam: merkezlerin yarısından fazlası ondan az tarama katkıda bulundu, yalnızca yaklaşık üçte biri hem hasta hem de sağlıklı kontrol verisine sahipti ve tarama protokolleri büyük farklılıklar gösteriyordu. Bu gerçek dünya koşullarında saf federated learning görevi iyi öğrenemedi; saf dolaşan model daha iyi performans gösterdi ancak hâlâ gelişmeye alan bıraktı. FedTM, özellikle ısıtma aşaması yedi en büyük ve en dengeli site ile yapıldığında, her ikisinden de belirgin şekilde daha iyi performans gösterdi: sınıflandırma kalitesinin standart bir ölçütü olan ROC eğrisi altındaki alan, yalnızca dolaşan modelde %77’den FedTM ile yaklaşık %82’ye yükseldi; duyarlılık, özgüllük ve F1-skoru gibi diğer klinik açıdan önemli metriklerde de benzer kazançlar görüldü.
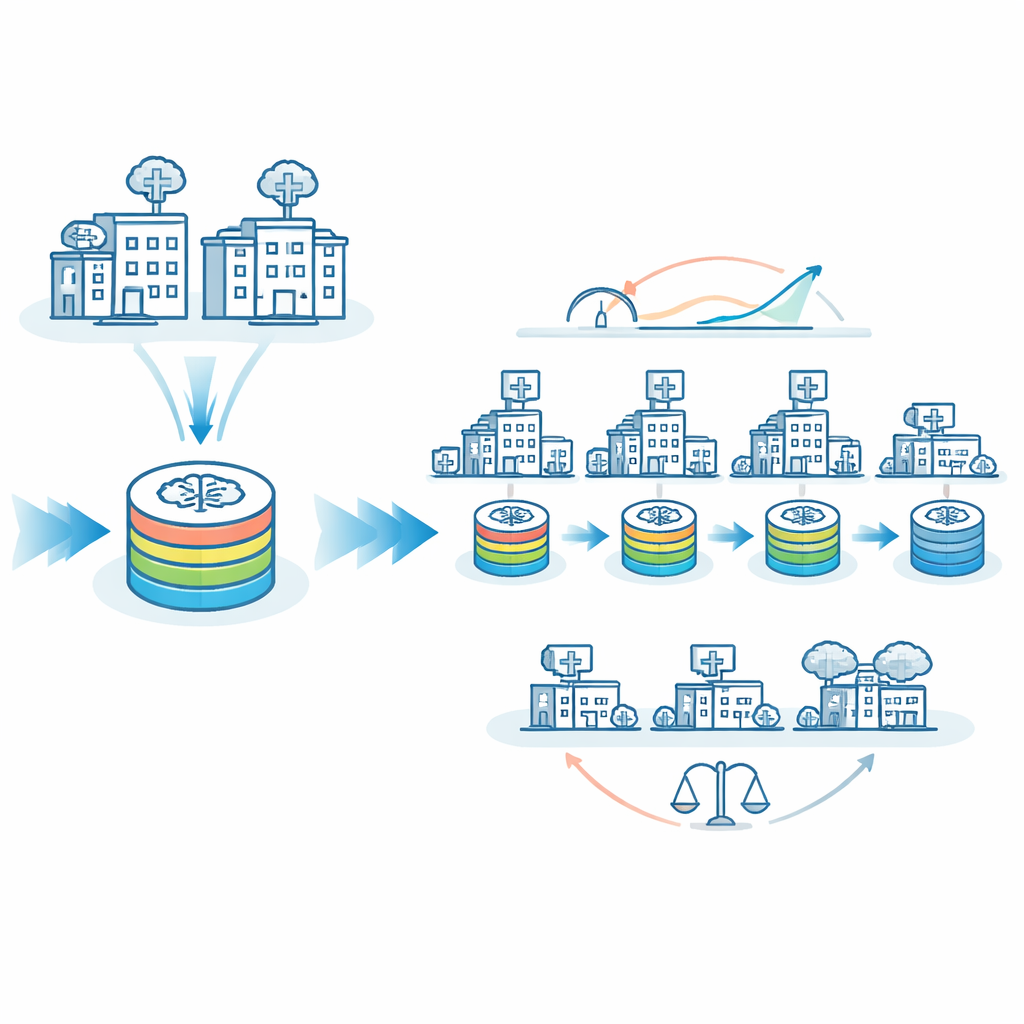
Büyük ve küçük hastaneler arasında yapay zekâyı daha adil kılmak
Tıbbi yapay zekâda önemli bir endişe eşitliktir: bir model, küçük, kırsal veya az kaynaklı hastanelerdeki hastalar için, büyük akademik merkezlerde olduğu kadar iyi çalışıyor mu? Ekip, yapay zekânın “daha büyük” ile “daha küçük” sahalardaki yanlış tahmin yapma sıklığını inceledi. Yalnızca dolaşan modelle yanlış sınıflandırma oranları bu gruplar arasında yaklaşık 8 yüzde puanı farklılık gösteriyordu. FedTM uygun şekilde ayarlandığında, büyük ve küçük sahalar için yanlış sınıflandırma oranları neredeyse aynı, yaklaşık %26 oldu. Başka bir deyişle, model yalnızca genel olarak daha doğru olmakla kalmadı, aynı zamanda daha dengeli hale geldi. FedTM ayrıca yoğun hesaplamanın çoğunu daha iyi kaynaklandırılmış sitelerdeki ısıtma aşamasına kaydırdı ve küçük sahaların çalıştırması gereken eğitim döngüsü sayısını neredeyse yarıya indirdi; oysa toplam eğitim süresi benzer kaldı.
Bu küresel dijital sağlık için ne anlama geliyor
FedTM, gizliliğe saygı gösteren, performansı artıran ve küresel ölçekte faydaları daha adil paylaşan yapay zekâ araçlarına yönelik pratik bir yol sunuyor. Çok az veriye sahip sahaların bile nihai model üzerinde etkili olmasına izin vererek, bu çerçeve az kaynaklı veya uzak bölgedeki insanların yeni tanı araçları geliştirilirken geride kalmamalarını sağlamaya yardımcı olabilir. Çalışma tek bir beyin taraması türü ve tek bir hastalığa odaklanmış olsa da, yaklaşım ilke olarak birçok başka tıbbi probleme uyarlanabilir. Sağlık sistemleri mobil cihazları ve giyilebilirleri giderek daha fazla benimsedikçe ve düzenlemeler veri egemenliğini vurguladıkça, FedTM gibi hibrit stratejiler güvenilir, kapsayıcı ve sorumlu tıbbi yapay zekâ oluşturmanın anahtarı hâline gelebilir.
Atıf: Souza, R., Stanley, E.A.M., Ohara, E.Y. et al. Combining federated learning and travelling model boosts performance and opens opportunities for digital health equity. npj Digit. Med. 9, 294 (2026). https://doi.org/10.1038/s41746-026-02483-y
Anahtar kelimeler: federated learning, dolaşan model, Parkinson hastalığı, tıbbi görüntüleme yapay zekası, sağlık eşitliği