Clear Sky Science · tr
Klinik yapay zeka sistemlerinde operasyonel güvenliği tanımlamak
Tıpta Güvenli Yapay Zeka Neden Önemli
Hastaneler, taramaları okumak ve hastalıkları işaretlemek için yapay zekayı hızla benimsiyor, ancak sıradan doğruluk puanlarının cevaplayamadığı bir soru var: makinenin karar vermesine ne zaman gerçekten izin vermek güvenlidir? Bu makale, doktorların bir yapay zeka sistemine ne zaman güvenle dayanabileceğine, ne zaman görmezden gelmeleri gerektiğine ve ne zaman kendilerinin daha yakından inceleme yapmasının gerektiğine karar verebilecekleri pratik bir yaklaşım sunuyor. Amaç yalnızca daha akıllı algoritmalar geliştirmek değil; bunları hasta koruyan, gereksiz testleri azaltan ve klinisyenlerin yükünü artırmak yerine hafifleten bir şekilde günlük bakıma entegre etmektir.
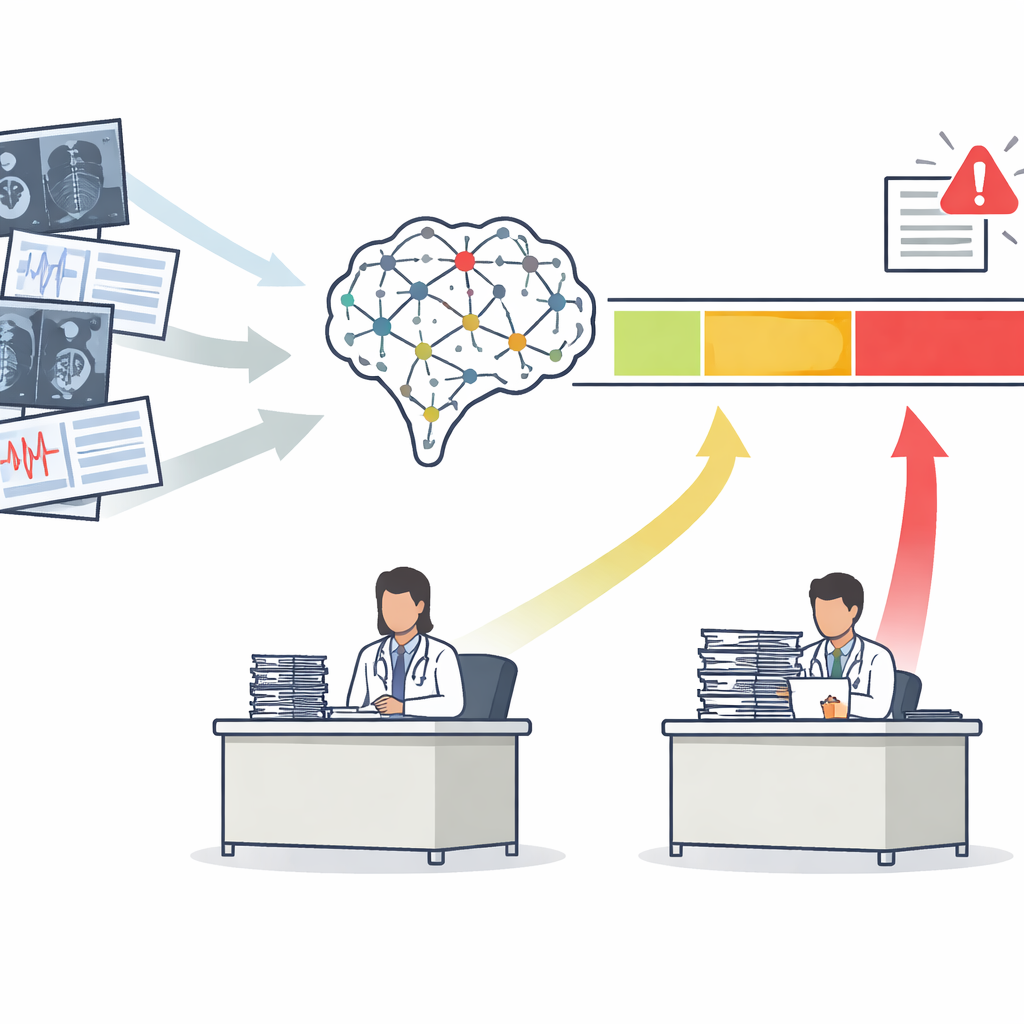
Tek Puanlı Değerlendirmeden Üç Açık Eylem Bölgesine
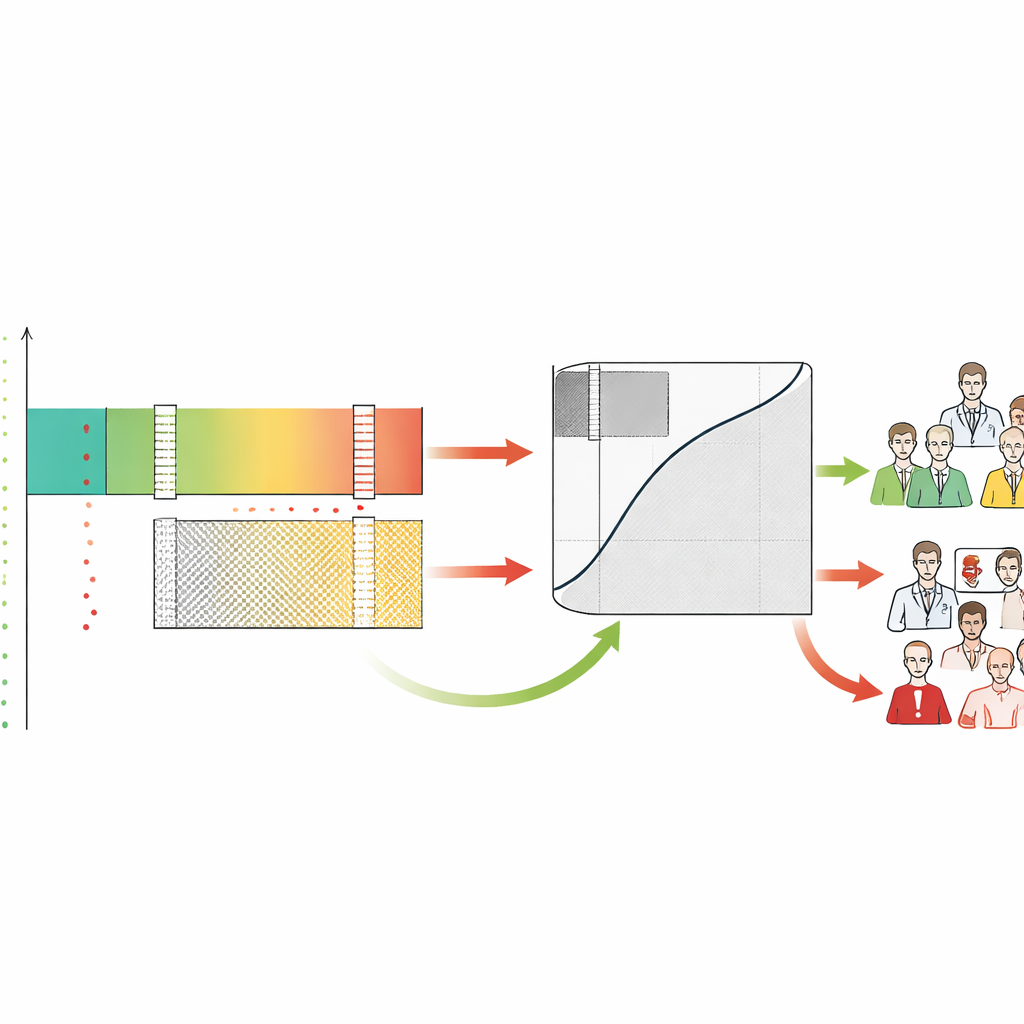
Çoğu tıbbi yapay zeka aracı, mamogramda kanser görülme olasılığı gibi tek bir risk puanı verir. Geleneksel olarak geliştiriciler, bunları hasta ve sağlıklı kişileri ne kadar iyi ayırdığını özetleyen bir eğri ile değerlendirir. Yazarlar bunun yeterli olmadığını savunuyor. Risk puanlarını alıp bunları üç pratik bölgeye dönüştüren Güvenlik Bilinçli ROC (SA-ROC) çerçevesini öneriyorlar. Yüksek puanlı "kabul et" (rule-in) bölgesi, acil takip gibi harekete geçmeyi tetikleyecek kadar güvenilir sonuçlara sahip hastaları içerir. Düşük puanlı "hariç tut" (rule-out) bölgesi, güvenle düşük öncelik verilebilecek kadar güvenilir sonuçları içeren hastaları kapsar. Bunların arasında ise yapay zekanın yeterince güvenilir olmadığı ve bir insan uzmanının vakayı gözden geçirmesi gereken "gri bölge" bulunur.
Klinisyenlerin Güvenlik Eşiğini Belirlemesine İzin Vermek
SA-ROC’un kritik özelliği, klinisyenlerin ve kurumların kendi güvenlik hedeflerini önceden tanımlamalarına olanak sağlamasıdır. Pozitif bir sonuca göre hareket etmeden önce ne kadar emin olmak istediklerini (işaretlenen bulgunun gerçekten anormal olma olasılığının kabul edilebilir asgari değeri) ve negatif bir sonuçta rahatlamak için ne kadar emin olmak istediklerini (temizlenen bir vaka gerçekten normal olma olasılığının kabul edilebilir asgari değeri) seçerler. Bu hedefler verildiğinde çerçeve, bu hedefleri sağlayan tam sınırları bulmak için modelin puanları arasında arama yapar. Üst sınırın üzerindeki puanlar rule-in güvenli bölgesini, alt sınırın altındaki puanlar rule-out güvenli bölgesini oluşturur ve aradaki her şey gri bölge haline gelir. Çerçeve daha sonra her bölgede kaç hastanın yer aldığını ve insanlara geri gönderilen belirsiz iş yükü—yapay zekanın çözmediği vakalar—miktarını nicelleştirir.
Benzer Yapay Zekâlar Arasındaki Gizli Farklılıkları Ortaya Çıkarmak
Yazarlar, geleneksel doğruluğu neredeyse aynı olan iki yapay zekâ sisteminin bu güvenlik bakış açısından bakıldığında çok farklı davranabileceğini gösteriyor. Simülasyonlarda, aynı genel performansa sahip modeller, puanlarının dağılımına bağlı olarak rule-in, rule-out ve gri bölgelerin çok farklı boyutlarını üretti. Biri hastalığı güvenle doğrulamada üstün olabilirken, diğeri büyük sayıda düşük riskli hastayı güvenle temizlemede başarılı olabilir. ABD Gıda ve İlaç Dairesi onaylı iki meme kanseri tarama aracının gerçek dünya vaka incelemesinde, daha yüksek standart doğruluk puanına sahip olan sistem yüksek güvenli tarama açısından aslında daha kötüydü. En sıkı güvenlik ayarında—düşük riskli grupta hiçbir kanserin kaçmasına izin verilmeyen durumda—iddialı biçimde daha zayıf olduğu düşünülen sistem, radyologun kuyruğundan neredeyse iki kat daha fazla kadını güvenle çıkardı. Böylece SA-ROC, geleneksel ölçütlerin gizlediği bir tür "performans tersine dönmesi"ni açığa çıkarır.
İnsan–Yapay Zeka Gerilimini ve İş Yükünü Anlamak
Her vakayı rule-in, rule-out veya gri olarak etiketleyerek çerçeve ayrıca insan doktorların bu bölgelerde nasıl davrandığını ortaya koyar. Yazarlar, radyologların sıklıkla yapay zekanın güvenle düşük riskli olduğunu değerlendirdiği vakaları aşırı çağırdığını ve makinenin en güvenilir olduğu bölgede birçok yanlış alarm ürettiğini buldu. Buna karşılık, hem insanlar hem de yapay zekâ gri bölgede zorlanıyor, bu da gri bölgeyi gerçekten uzman dikkatinin gerektiği alan olarak doğruluyor. SA-ROC, bu gri bölgenin boyutunu kararsızlığın maliyetini temsil eden tek bir sayı ile yakalar. Küçük bir gri bölge daha fazla güvenli otomasyon ve daha az insan işi anlamına gelir; büyük bir gri bölge ise birçok vakanın hâlâ dikkatli manuel inceleme gerektirdiğini ve sistemin rahatlatmak yerine tükenmişliği artırabileceğini gösterir.
Güvenlik Kurallarını Günlük Uygulamaya Dönüştürmek
Ölçümün ötesinde, çerçeve politikaları somut yapay zeka davranışına dönüştüren bir yönetişim aracı olarak tasarlanmıştır. Hastaneler bunu iki şekilde kullanabilir. Birincisi, doğrudan güvenlik gereksinimlerini veya gri bölgeye göndermeye razı oldukları vaka sayısına ilişkin sınırları belirleyip çerçevenin karşılık gelen eşik değerleri hesaplamasını sağlamaktır. İkincisi, farklı sonuçlara—bir kanseri yakalamak, birini kaçırmak, gereksiz test istemek veya insan incelemesine ertelemek—değerler ve cezalar atayıp çerçevenin genel faydayı maksimize eden politikayı aramasını sağlamaktır. Bu stratejiler, kitle tarama programları, uzman yönlendirmeleri veya araştırma kohortları gibi çok farklı hedefler için ayarlanabilir ve hepsi aynı temel modeli kullanır.
Bu Hastalar ve Klinikler İçin Ne Anlama Geliyor
Daha sade ifadeyle, bu çalışma sadece "bu yapay zekâ doğru" demek yerine "işte klinikte ne zaman ve nasıl güvenilebileceği"ni tam olarak söylemenin bir yolunu sunuyor. Yapay zekâ çıktılarının güvenli, güvensiz ve belirsiz bölgelere ayrılması ve bunların açık güvenlik vaatlerine bağlanması, SA-ROC’un sağlık sistemlerinin makinelerin ne zaman kendi başına hareket edebileceğine ve ne zaman insanların kesinlikle kontrolü elinde tutması gerektiğine karar vermesine yardımcı olur. Geleneksel doğruluk puanlarının yanıltıcı olabileceğini ve gerçek güvenliğin hataların en maliyetli olduğu uç davranışlara bağlı olduğunu vurgular. Geniş ölçekte benimsenip daha büyük, gerçek dünya ortamlarda doğrulanırsa, bu çerçeve daha güvenilir otomasyonu destekleyebilir, gereksiz alarmları ve testleri azaltabilir ve en zor yapay zekâ vakalarını—gri bölgeyi—hem algoritmalar hem de tıp için öğrenme ve iyileşme odaklı bir kaynağa dönüştürebilir.
Atıf: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Anahtar kelimeler: klinik yapay zeka, operasyonel güvenlik, tıbbi görüntüleme, karar destek, risk sınıflandırması