Clear Sky Science · tr
Beyin MRG rapor bulgularından tanısal izlenim üretimi için büyük dil modellerinin değerlendirilmesi: çok merkezli bir ölçüt ve okuyucu çalışması
Hastalar için daha akıllı MRG raporlarının önemi
Beyin görüntülemesi yaptırdığınızda, bir radyolog binlerce gri tonunu neyin yanlış olduğunu açıkça belirten bir ifadeye —ya da her şeyin normal göründüğüne— dönüştürmek zorundadır. Bu nihai “izlenim” inme bakımı, beyin tümörleri, enfeksiyonlar ve daha fazlası hakkında kritik kararları yönlendirir. Ancak beyin MRG’lerini okumak karmaşık ve zaman alıcıdır ve yoğun çalışan doktorlar, özellikle kalabalık hastanelerde, hata yapabilirler. Bu çalışma, gelişmiş yapay zeka dil modellerinin yazılı MRG bulgularını doğru, hızlı ve tutarlı tanısal izlenimlere dönüştürmede radyologlara güvenilir biçimde yardımcı olup olamayacağını araştırıyor.
Ham görüntü tanımlarını net yanıtlarla birleştirmek
Beyin MRG’leri, radyologların lezyonun nerede olduğunu, ne kadar parlak göründüğünü ve şişlik olup olmadığını belirterek yazdığı bir “bulgular” bölümünde tanımladıkları bir dizi görüntü üretir. Gerçek zorluk, bu ayrıntıların tümünü “akut infarkt” veya “beyin apsesi” gibi bir tanısal izlenime dönüştürmektir. Araştırmacılar, Çin’deki üç hastaneden günlük beyin koşullarının %95’inden fazlasını kapsayan 16 tanısal kategoriye yayılan 4293 beyin MRG raporu topladı. Ardından yazılı bulguları doğru tanılara ne kadar iyi dönüştürebildiklerini görmek için 10 farklı büyük dil modelini—gelişmiş metin tabanlı yapay zeka sistemlerini—test ettiler.
Büyük, iyi eğitilmiş yapay zekalar öne çıktı
Ekip, yaklaşık 8 milyardan 671 milyara kadar iç parametreleri olan modelleri karşılaştırdı; bu, kabaca bir tıp öğrencisinin bilgisinden uzman bir takımın bilgisine geçişe benzetilebilir. En büyük model olan DeepSeek‑R1, bulguların yapılandırılmış versiyonları ve hasta yaşı, semptomlar veya travma öyküsü gibi temel klinik bilgilerin sağlandığı durumlarda tutarlı şekilde en iyi performansı gösterdi. Bu koşullar altında DeepSeek‑R1, belirli beyin durumlarının varlığını veya yokluğunu yüksek duyarlılık ve özgüllükle doğru tanımladı ve hasta düzeyinde doğruluğu %87’nin üzerinde sağladı. Özellikle 10 milyarın altındaki daha küçük modeller ciddi şekilde zorlandı ve genellikle olguların yalnızca yaklaşık %30’unu doğru tahmin etti—bu, gerçek klinik uygulamada kabul edilebilirin çok altında.
Neden yapı ve bağlam yapay zekayı akıllı kılar
Araştırmacılar modellere yalnızca serbest biçimli metin vermedi. Raporları, her lezyonun nerede olduğunu, kaç tane olduğunu ve farklı MRG sekanslarında nasıl göründüğünü açık, standartlaştırılmış öğelere dönüştürmek için başka bir yapay zeka sistemi de kullandılar. Bu yapıyı eklemek ve kısa klinik notlarla birleştirmek çarpıcı bir fark yarattı. DeepSeek‑R1 için ham serbest metin bulgularından yapılandırılmış bulgular artı klinik bağlama geçiş, duyarlılığı, genel doğruluğu ve özet performans ölçütlerini yükseltti. Basitçe söylemek gerekirse, yapay zeka daha temiz, daha düzenli bilgiler ve biraz hasta geçmişi sağlandığında çok daha iyi performans gösterdi—bu, insan radyologların raporlar düzenliyken ve klinik soru net olduğunda en iyi şekilde çalıştıklarını yansıtıyor.
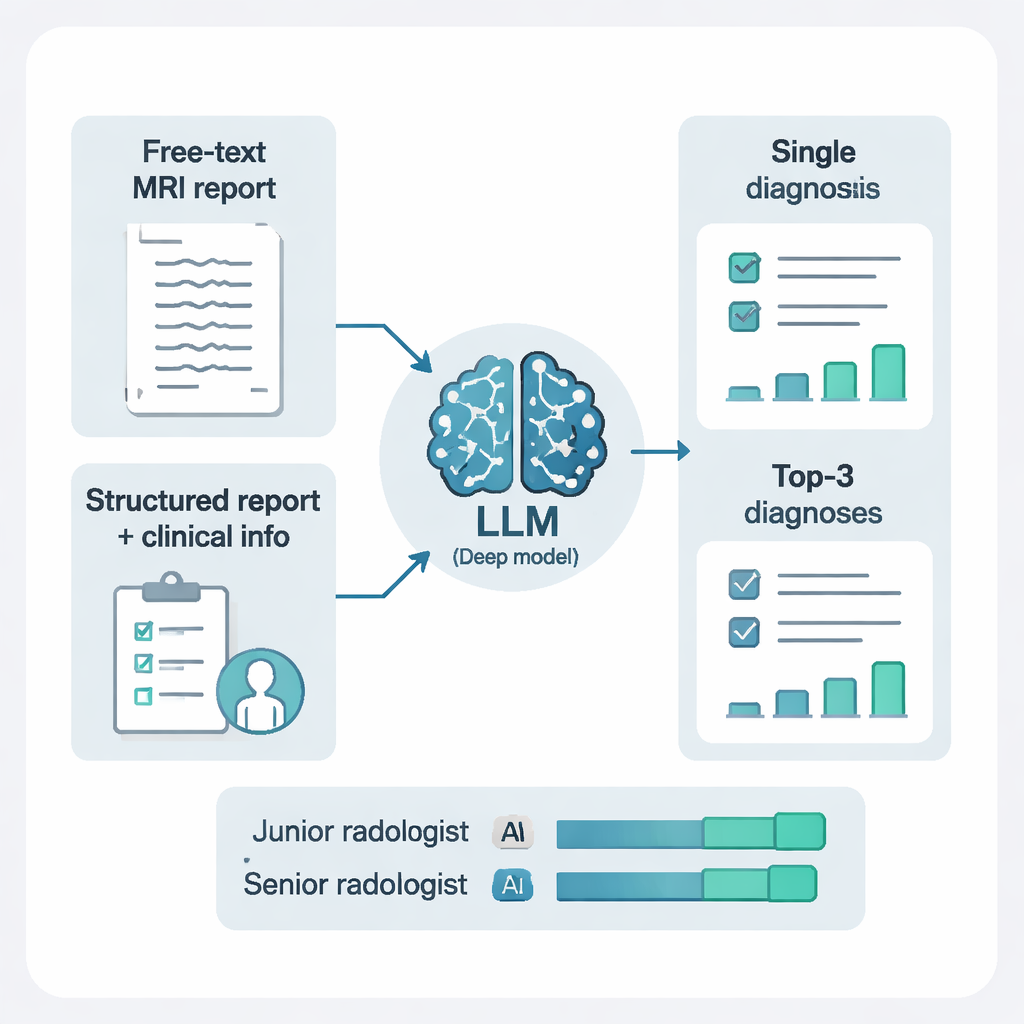
Tek bir tahminden sıralı kısa listeye
Gerçekte, radyologlar zor vakalar için genellikle birden fazla olası tanı sunar. Çalışma iki istem tarzını test etti: yapay zekadan yalnızca bir tanı istemek veya en iyi üç olasılığını kısa bir açıklama ile istemek. Üç sıralı tanıya izin vermek performansı önemli ölçüde artırdı. Bu “ayırıcı tanı” yaklaşımıyla doğru cevap, hastaların %97’sinden fazlasında ilk üç öneriden birinin içinde yer aldı. Bu, tek bir zorunlu tahminin yanıltıcı olabileceği, ancak kısa ve mantıklı bir listenin ileri test ve tedaviyi etkili biçimde yönlendirebileceği tümörler, kanamalar veya inflamatuar hastalıklar gibi karmaşık olgularda özellikle faydalı oldu.
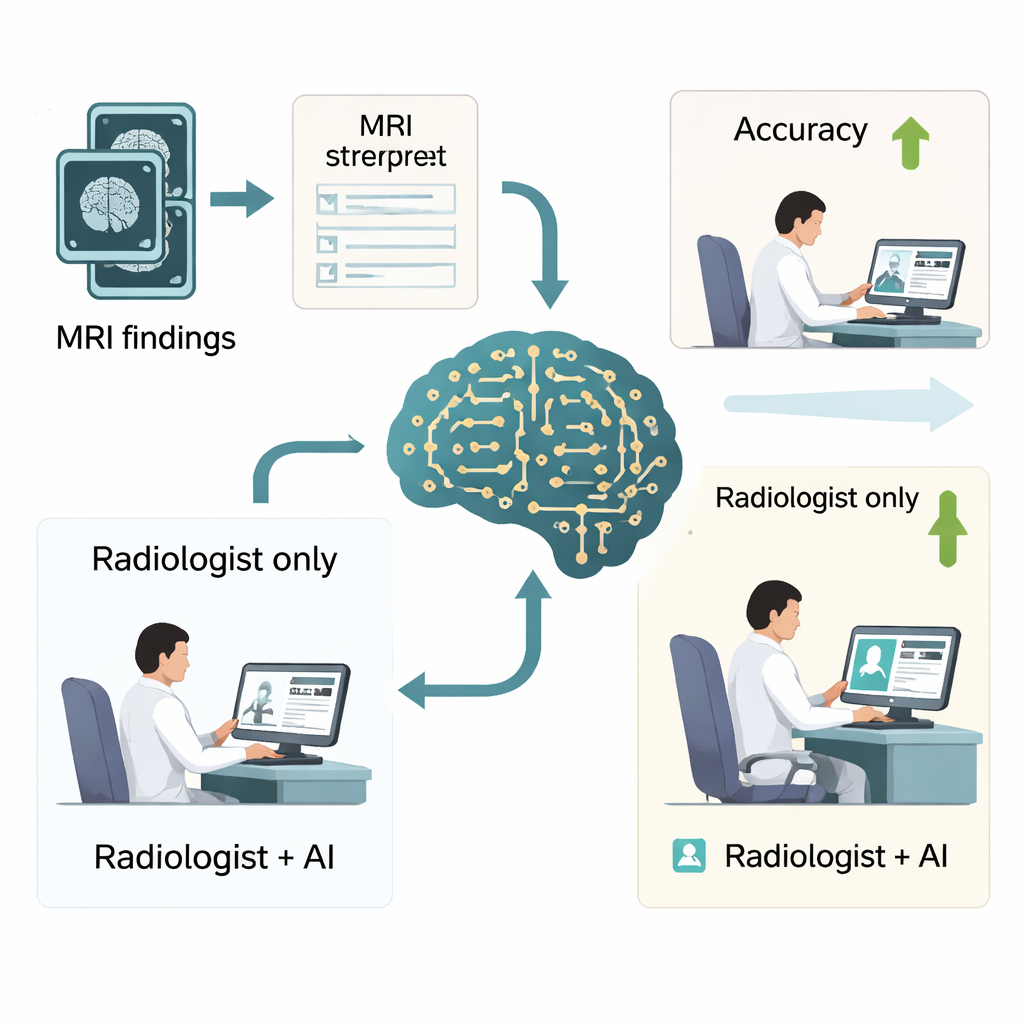
Yoğun çalışan radyologlar üzerinde gerçek dünya etkisi
Bu kazanımların uygulamada önemli olup olmadığını görmek için yazarlar, DeepSeek‑R1 yardımcılığıyla ve onsuz olmak üzere 500 beyin MRG raporunu değerlendiren altı radyolog—üçü junior, üçü kıdemli—ile bir okuyucu çalışması yürüttüler. Yapay zeka yardımıyla genel tanı doğruluğu yaklaşık dörtte üç seviyesinden %90’ın üzerine çıktı ve kesinlik ile çağrı (precision ve recall) gibi önemli bir kalite ölçütü de önemli ölçüde iyileşti. Okuma süresi de düştü; vaka başına yaklaşık bir dakikadan daha kısa sürelere indi; bu, her radyolog için yılda onlarca saat tasarruf anlamına gelebilir. En büyük faydalar junior radyologlarda gözlendi; performansları deneyimli uzmanlarınkine daha yakınlaştı, ancak çalışma aynı zamanda doktorların çok ince bulgular, örneğin belirli beyin kanaması türleri için, yapay zekaya körü körüne güvenmeme konusunda dikkatli olmaları gerektiğini vurguladı.
Geleceğin beyin görüntüleme raporları için anlamı
Hastalar için temel çıkarım şudur: Güçlü dil tabanlı yapay zeka sistemleri, özellikle iyi yapılandırılmış bilgiler ve temel klinik ayrıntılar sağlandığında, radyologların karmaşık MRG tanımlarını daha net, daha doğru tanısal izlenimlere dönüştürmesine zaten yardımcı olabilir. Bu araçlar insan uzmanlığının yerini almaz; bunun yerine dikkatli bir ikinci bakış sunarak mantıklı öneriler sağlayabilir ve zaman kazandırabilirler. Daha geniş ölçekli doğrulama ve hastane sistemlerine güvenli entegrasyon sağlandığında, bu tür yapay zeka destekleri beyin görüntüleme raporlarını daha hızlı, daha güvenilir ve daha tutarlı hale getirmeye yardımcı olabilir—nihayetinde inme, tümör, enfeksiyon ve birçok diğer beyin durumuna sahip hastaların bakımını iyileştirerek.
Atıf: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Anahtar kelimeler: beyin MRG tanısı, radyoloji yapay zeka, büyük dil modelleri, klinik karar destek, DeepSeek-R1