Clear Sky Science · tr
Büyük dil modelleri, elektronik sağlık kayıtlarına dayalı tahminlerin ülkeler ve kodlama sistemleri arasında aktarılabilirliğini artırıyor
Tıbbi verilerin daha akıllıca paylaşılmasının önemi
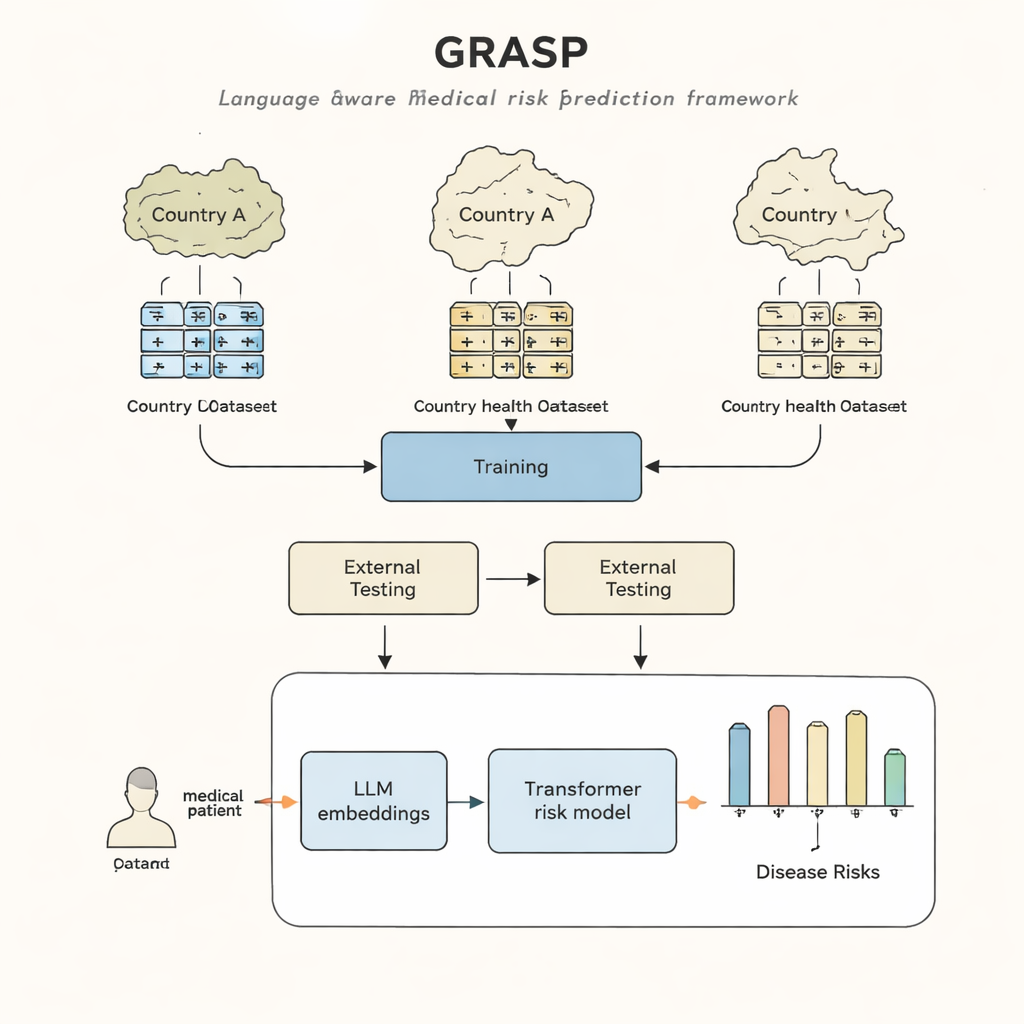
Dünyadaki hastaneler ve klinikler yıllara yayılan teşhisleri, tedavileri ve sonuçları yakalayan elektronik sağlık kayıtlarıyla adeta bir bilgi hazinesine sahip. Teoride bu bilgiler, doktorların semptomlar belirginleşmeden çok önce hangi kişilerin ciddi hastalıklara karşı yüksek risk taşıdığını saptamasına yardımcı olabilir. Ancak pratikte, bugünün bilgisayar modelleri bir ülkeden veya hastane sisteminden diğerine “taşınmakta” zorlanıyor; çünkü her yer sağlık verilerini farklı biçimlerde kaydediyor. Bu çalışma, tek bir sağlık sisteminde eğitilmiş bir modelin diğerlerinde de güvenilir biçimde çalışmasını sağlayacak boşlukları kapatmak için yapay zekadaki ilerlemeleri kullanan GRASP adlı yeni bir yaklaşım sunuyor.
Farklı hastaneler, farklı diller
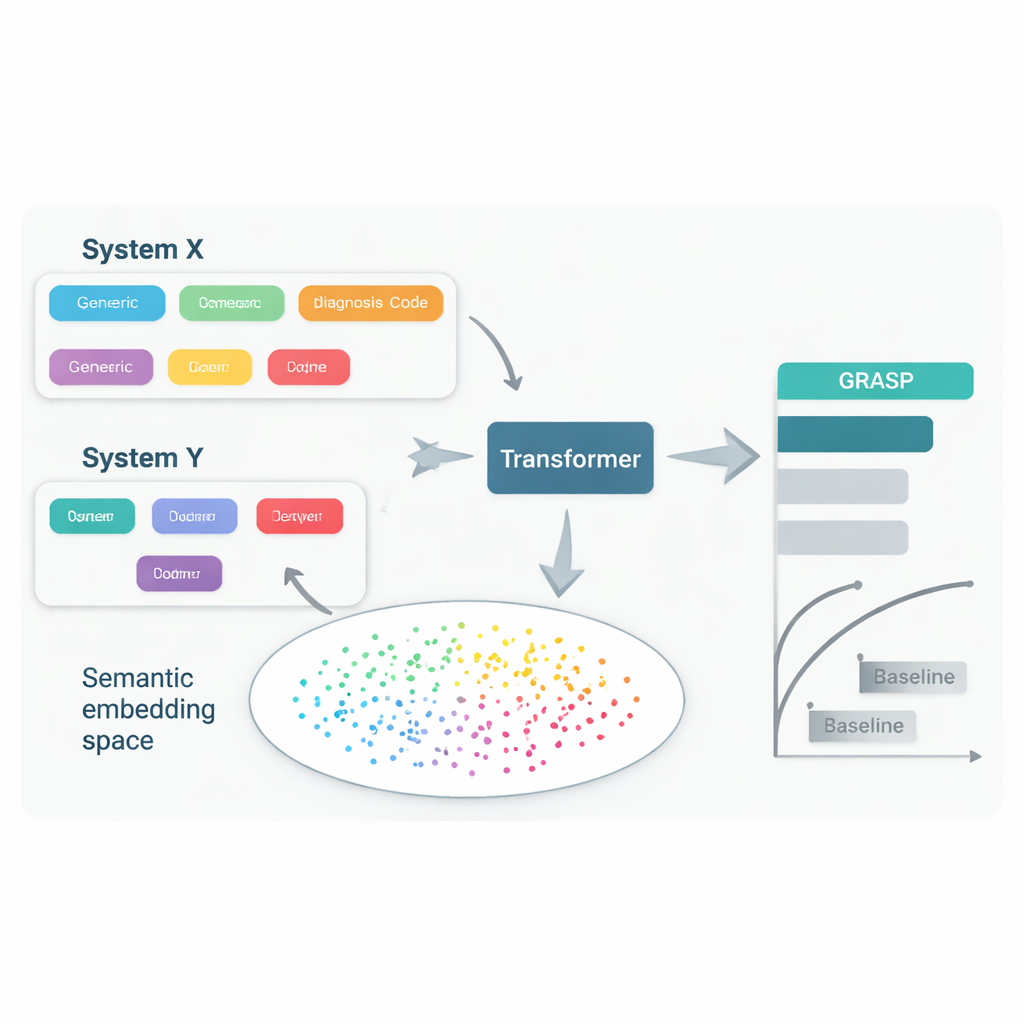
Aynı hastalık tedavi edilse bile doktorlar bunu tıbbi kayıtta farklı kod sistemleri ve yerel alışkanlıklarla kaydedebilir. Bir hastane “yüksek kan şekeri”ni bir kodla saklarken, başka bir hastane “hiperglisemi” için farklı bir kod kullanabilir; üçüncü bir yer ise tamamen başka bir sistem kullanabilir. Herkesi tek bir ortak standarda zorlamak—büyük uluslararası kodlama şemaları gibi—yararlı olsa da yavaş, pahalıdır ve hâlâ önemli farklar bırakır. Sonuç olarak, bir ülkedeki kayıtlardan hastalık tahmin eden bir bilgisayar modeli başka bir yerde uygulandığında doğruluğunu kaybedebilir ve bu araçlardan kimlerin yararlanabileceğini sınırlayabilir.
Yalnızca koda değil, anlama da yapay zekâya bırakmak
GRASP yaklaşımı basit bir fikirle başlıyor: her tıbbi kodu anlamsız bir kimlik numarası olarak görmek yerine, büyük bir dil modelinin arkasındaki insan tanımını—örneğin “akut üst solunum yolu enfeksiyonu”—okumasına ve bu anlamı sayısal bir “gömüleme”ye (embedding) dönüştürmesine izin verin. Bu gömülmeler, ilgili kavramları ortak bir alanda birbirine yakın konumlandırır; farklı kodlama sistemlerinden veya ülkelerden gelseler bile. GRASP, milyonlarca standart tıbbi terim için bu tür gömülmeleri önceden hesaplar ve bir arama tablosunda saklar. Bir hastanın tıbbi geçmişi daha sonra bu zengin vektörlerin bir dizisi olarak temsil edilir ve çeşitli girdilerle başa çıkmaya uygun bir sinir ağı türü olan transformer ağına geçirilerek o kişinin 21 önemli hastalık için ve genel ölüm riski için tahmini yapılır.
Ülkeler ve kayıt sistemleri arasında test etmek
Araştırmacılar GRASP’i İngiltere Biyobankası’ndaki yaklaşık 400.000 katılımcı verisiyle eğitti, ardından yeniden eğitmeden iki çok farklı ortamda test etti: Finlandiya’daki FinnGen projesi ve New York City’deki büyük bir hastane ağı. GRASP, popüler bir yöntem olan XGBoost ve dil tabanlı gömülmeler kullanmayan benzer bir transformer dahil güçlü alternatiflerle eşleşti veya onları geride bıraktı. Finlandiya’da GRASP özellikle iyi performans gösterdi; astım, kronik böbrek hastalığı ve kalp yetmezliği gibi durumlarda belirgin kazanımlar sağladı. İlginç biçimde, Amerikan hastane verileri ortak bir standarda dönüştürülmeden farklı bir kodlama şemasında bırakıldığında bile, GRASP yalnızca açıklamaların wording’ini anlayarak kodları hizalayabildiği için demografik bilgilerin ötesinde daha iyi tahminler verdi.
Daha az veriyle daha fazlasını elde etmek
GRASP’in bir diğer avantajı verimliliktir. Dil modeli birçok tıbbi kavramın ilişkili olduğunu zaten öğrendiği için tahmin ağı bu bağlantıları sıfırdan yeniden keşfetmek zorunda kalmaz. Yazarlar GRASP’i İngiltere verilerinin çok daha küçük alt kümelerinde—sadece 10.000 kişiye kadar—eğittiklerinde bile, aynı sınırlı örneklerle eğitilmiş rakip modelleri hem İngiltere’de hem de yurtdışına transfer edildiğinde geride bıraktı. GRASP’in risk puanları ayrıca birkaç hastalık için insanların kalıtsal genetik riskiyle daha yakından örtüştü; bu da modelin tek bir veri setindeki kalıpları ezberlemekten ziyade hastalık yatkınlığının daha derin yönlerini yakalıyor olabileceğini düşündürüyor.
Gelecekte bakım için ne anlama geliyor
Uzman olmayanlar için temel mesaj şudur: GRASP, modern dil tabanlı yapay zekânın farklı sağlık sistemlerinin katı tek bir kodlama şemasına zorlamadan “aynı dili konuşmasına” nasıl yardımcı olabileceğini gösteriyor. Tıbbi terimlerin anlamını okuyarak GRASP, ülkeler ve kayıt formatları arasında daha iyi genelleşen hastalık risk tahminleri yapabilir ve bunu daha az hasta örneğiyle gerçekleştirebilir. Yöntemin günlük bakımda kullanılmadan önce dikkatli testlere, yeniden kalibrasyona ve adalet kontrollerine hâlâ ihtiyacı olsa da, güçlü risk araçlarının bir yerde geliştirilip güvenli ve verimli biçimde dünya genelindeki hastaneler ve kliniklerle paylaşılabileceği bir geleceğe işaret ediyor.
Atıf: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Anahtar kelimeler: elektronik sağlık kayıtları, hastalık risk tahmini, büyük dil modelleri, tıbbi veri paylaşımı, sağlık hizmetlerinde yapay zeka