Clear Sky Science · tr
Merkezi olmayan makine öğrenmesi ve AI klinik modellerinin yerel ve merkezi alternatiflerle karşılaştırılması: sistematik bir derleme
Verileri Paylaşmadan Tıbbi Bilgi Paylaşmanın Neden Önemli Olduğu
Çağdaş tıp, hastalığı daha erken tespit etmek, doğru tedaviyi seçmek ve kimlerin en yüksek risk altında olduğunu öngörmek için giderek daha fazla yapay zekâya dayanıyor. Yine de en iyi AI araçları büyük miktarda hasta verisi gerektirir ve hastaneler sıkı gizlilik yasaları ve etik kaygılar nedeniyle kayıtlarını basitçe birleştiremez. Bu makale, hastanelerin ham hasta verilerini hiç paylaşmadan birlikte AI eğitebilmesini sağlayan “merkezi olmayan” öğrenme yaklaşımlarına dair on yılı aşkın araştırmayı inceliyor ve pratik bir soruyu gündeme getiriyor: bu gizliliği koruyan yöntemler geleneksel yaklaşımlarla karşılaştırıldığında gerçekte ne kadar iyi performans gösteriyor?
Gizliliği Korurken Hastalardan Öğrenmenin Yeni Yolları
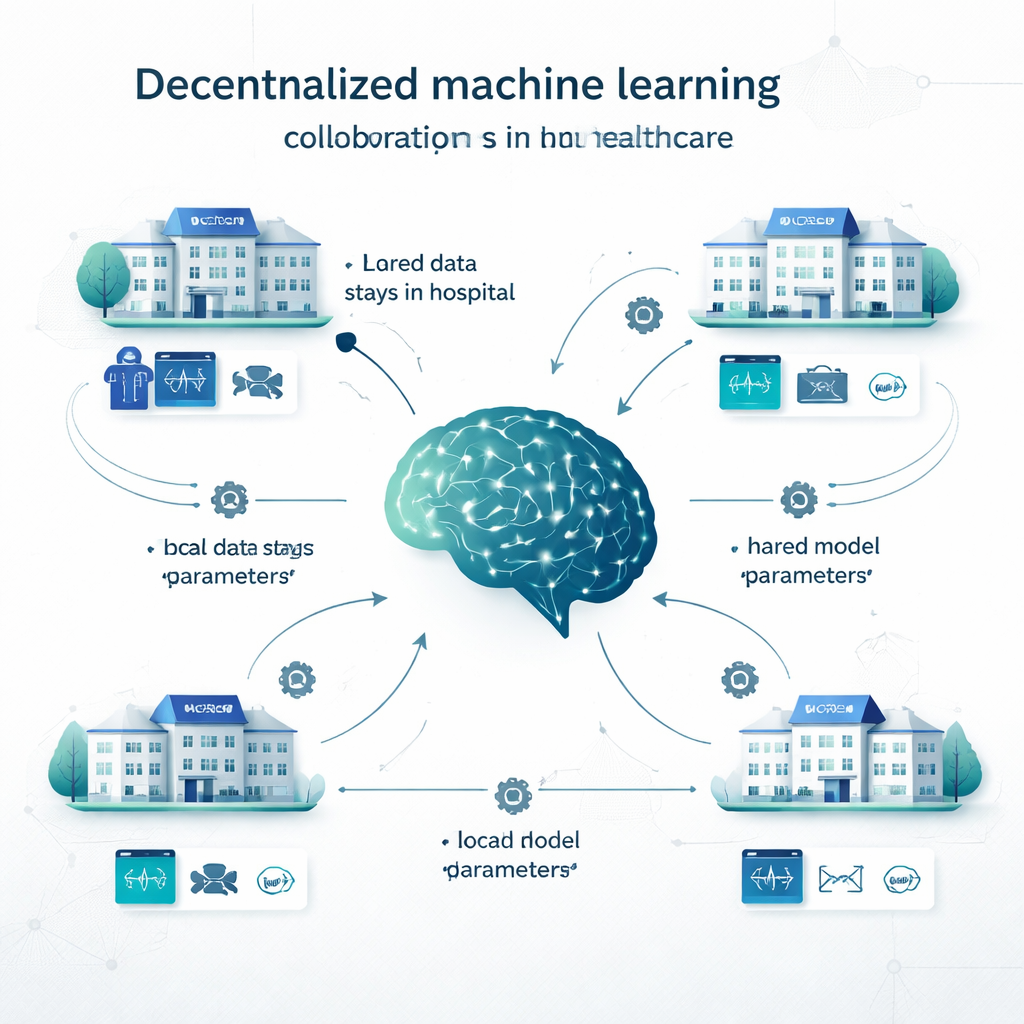
Geleneksel merkezi öğrenmede hastaneler tüm verilerini tek bir büyük veritabanına kopyalar ve tek bir model orada eğitilir. Yerel öğrenmede ise her kurum kendi verisinde kendi modelini oluşturur; işbirliği yoktur. Merkezi olmayan öğrenme ise ortada bir yol sunar. Örneğin federated learning’de her hastane modeli yerel olarak eğitir, ardından yalnızca modelin ayarları (bir sinir ağındaki “düğmeler” gibi) paylaşılıp ortak bir model oluşturulur; hasta kayıtları asla siteden çıkmaz. Swarm learning ise merkezi koordinatörü ortadan kaldırır ve kurumların model güncellemelerini doğrudan değiştirmesine izin verir. Diğer merkezi olmayan yaklaşımlar, birden çok yerel modelin tahminlerini birleştirmeyi veya modeli siteler arasında bölmeyi içerir. Bu yöntemler, kanser tespiti ve COVID‑19 tanısından kalp hastalığı, diyabet, beyin bozuklukları ve ruh sağlığı durumlarına kadar çok çeşitli sorunlarda test edilmiştir.
Araştırmacıların İncelediği Konular
Yazarlar 2012 ile Mart 2024 arasında yayımlanmış 11 büyük veritabanını sistematik olarak taradı ve 165.010 çalışmayı elemelere tabi tuttu. Çoğaltılmış kayıtlar ve gerçek klinik kararları içermeyen çalışmalar çıkarıldıktan sonra 160 makale kaldı. Bu makaleler topluca 710 merkezi olmayan modeli ve merkezi veya yerel modellerle 8.149 doğrudan performans karşılaştırmasını rapor etti. Çoğu çalışma tanıya odaklandı, ancak tümörlerin çevrelenmesi gibi görüntü segmentasyonu, hayatta kalma veya komplikasyonlar gibi gelecekteki sonuçların tahmini ve birleşik görevler üzerine de çok sayıda çalışma vardı. Ele alınan veri türleri tıpta kullanılan hemen hemen her ana kaynağı kapsıyordu: elektronik sağlık kayıtları, BT ve MRI taramaları, röntgenler, dijital patoloji slaytları, kalp ve beyin sinyalleri ve hatta genetik veriler.
Gizliliği Koruyan Modellerin Merkezi AI ile Karşılaştırılması
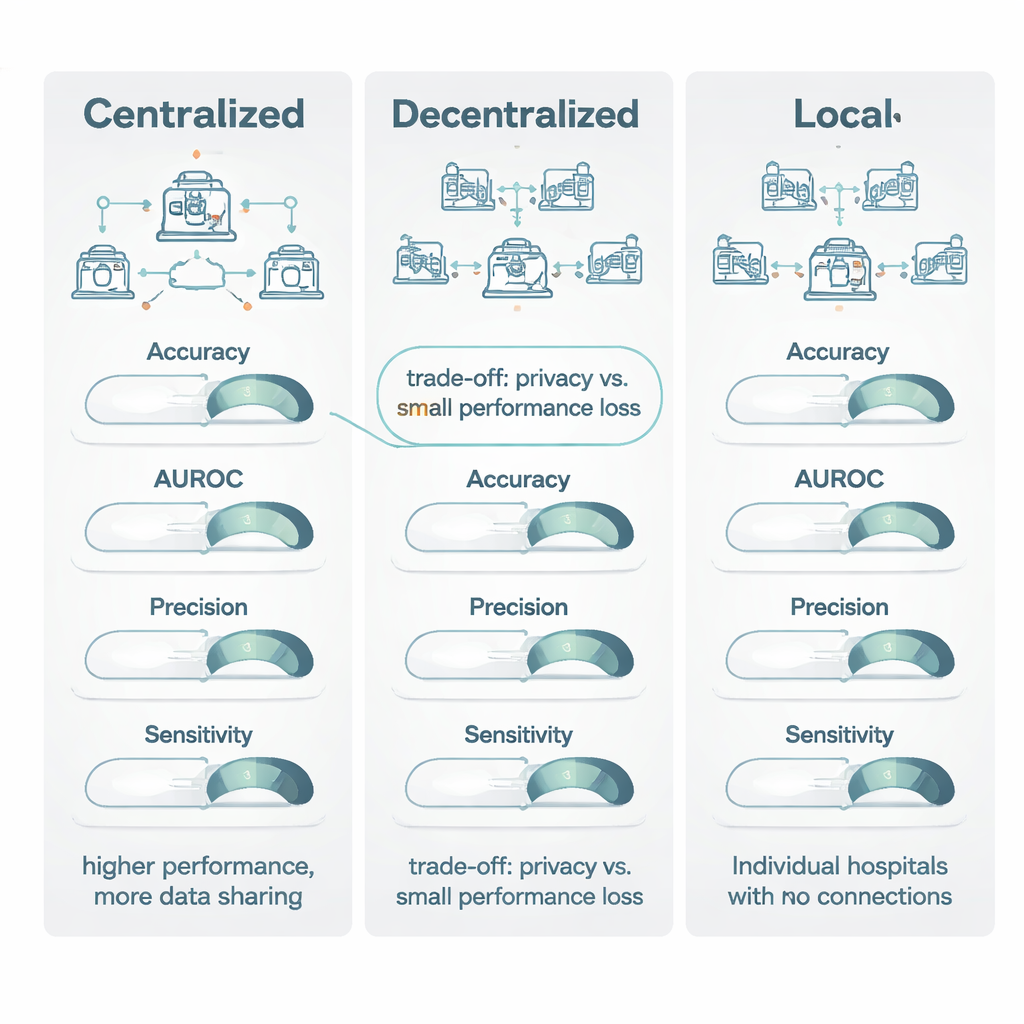
Merkezi olmayan modeller, havuzlanmış verilerle eğitilmiş merkezi modellerle karşılaştırıldığında, merkezi öğrenme genellikle biraz önde çıktı. Merkezi öğrenme özellikle doğruluk gibi eşik tabanlı ölçütlerde ve Dice katsayısı adı verilen yaygın bir görüntüleme skorunda başarılıydı; yaklaşık dörtte üç oranında ve orta ila büyük bir avantaj sayılacak düzeyde galip geldi. Ancak ROC eğrisi altındaki alan (AUROC) gibi sıralama türü ölçütlerde—bir modelin hastaları daha düşükten daha yükseğe risk sırasına dizme yeteneğini yakalayan—merkezi olmayan ve merkezi modeller çok daha yakındı; merkezi eğitimin küçük bir üstünlüğü vardı. Önemli olarak, her iki model de yazarların “klinik açıdan uygun” performansa (en az 0,80 puan) ulaştığında, merkezi modelin tipik kazancı ılımlıydı: genellikle %1–1.5 puandan daha azdı. Birçok durumda bu, “mükemmel vs kabul edilebilir”e işaret ediyor; “kullanılabilir vs işe yaramaz”a değil.
Merkezi Olmayan Öğrenmenin Tek Başına Gitmekten Neden İyi Olduğu
Derlemede en güçlü sinyal, merkezi olmayan modeller ile tamamen yerel modellerin karşılaştırılmasında ortaya çıktı. Doğruluk, AUROC, F1 skoru, duyarlılık, özgüllük ve özellikle precision gibi tüm ana ölçütlerde merkezi olmayan yöntemler neredeyse her zaman daha iyi performans gösterdi ve sıklıkla geniş bir farkla öne çıktı. Doğrudan karşılaştırmalarda, merkezi olmayan öğrenme doğruluk, precision ve AUROC gibi ana ölçütler için karşılaştırmaların %80’inden fazlasında yerel modelleri geride bıraktı. Birçok durumda yerel modeller klinik kullanım için belirlenen 0.80 eşik değerine ulaşamazken, karşılık gelen merkezi olmayan model bu eşiği rahatça geçti ve duyarlılığı bazen 27 yüzde puanına kadar artırdı. Yazarlar bunu çok merkezli modellerin kazandığı daha geniş deneyime bağlıyor: birçok hastaneden gelen örüntüleri “görerek”, tarayıcı veya kayıt tutma kaynaklı kurum‑özgü tuzaklara daha az aldanıyor ve gerçekten genelleşen hastalık özelliklerine daha fazla duyarlı hale geliyorlar.
Performans, Gizlilik ve Pratik Kullanım Arasında Denge Kurmak
Derleme, gizlilik kuralları ve lojistik verilerin birleştirilmesine izin verdiğinde ve performanstaki her kesir puanın önemli olduğu çok nadir hastalıklar gibi durumlarda merkezi öğrenmenin hâlâ altın standart olduğunu sonucuna varıyor. Ancak merkezi olmayan öğrenme, GDPR ve AB AI Yasası gibi yasalar veya kurumsal politikalar nedeniyle veri paylaşımının kısıtlandığı durumlar için güçlü ve klinik olarak kabul edilebilir bir alternatif sunuyor. Modelleri tamamen yerel tutmaya kıyasla merkezi olmayan yaklaşımlar, verileri hastane duvarları içinde tutarken hem doğruluk hem de güvenilirlikte büyük kazançlar sağlıyor. Yazarlar, sağlık sistemlerinin hafif performans ödünlerinin gizlilik ve işbirliğinde sağlanan önemli avantajlara değip değmeyeceğine karar verebilmesi için gelecek çalışmalarda gizlilik teknikleri ve hesaplama maliyetlerinin daha açık raporlanması gerektiğini savunuyorlar.
Atıf: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Anahtar kelimeler: federated learning, sağlık hizmetlerinde AI, tıbbi veri gizliliği, merkezi olmayan makine öğrenmesi, klinik öngörü modelleri