Clear Sky Science · tr
Bulut ortamlarında iş yükü tahmini için dinamik makine öğrenimi yaklaşımı
Neden akıllı trafik tahmini önemli
Her video akışı yaptığınızda, büyük bir spor etkinliğini çevrimiçi takip ettiğinizde veya bir flaş satışta alışveriş yaptığınızda, binlerce kişi aynı anda tıklıyor olabilir. Perde arkasında bulut veri merkezleri, siteleri hızlı tutarken boşta duran makineler için gereksiz para harcamamak adına çaba gösterir. Bu makale, pratik açıdan büyük etkisi olan basit bir soruyu ele alıyor: bulut sistemleri, sunucuları tam zamanında açıp kapatacak kadar ani web trafiği dalgalarını nasıl öngörebilir, tahminle aşırı ödeme yapmak yerine doğru zamanda hazırlanabilir?
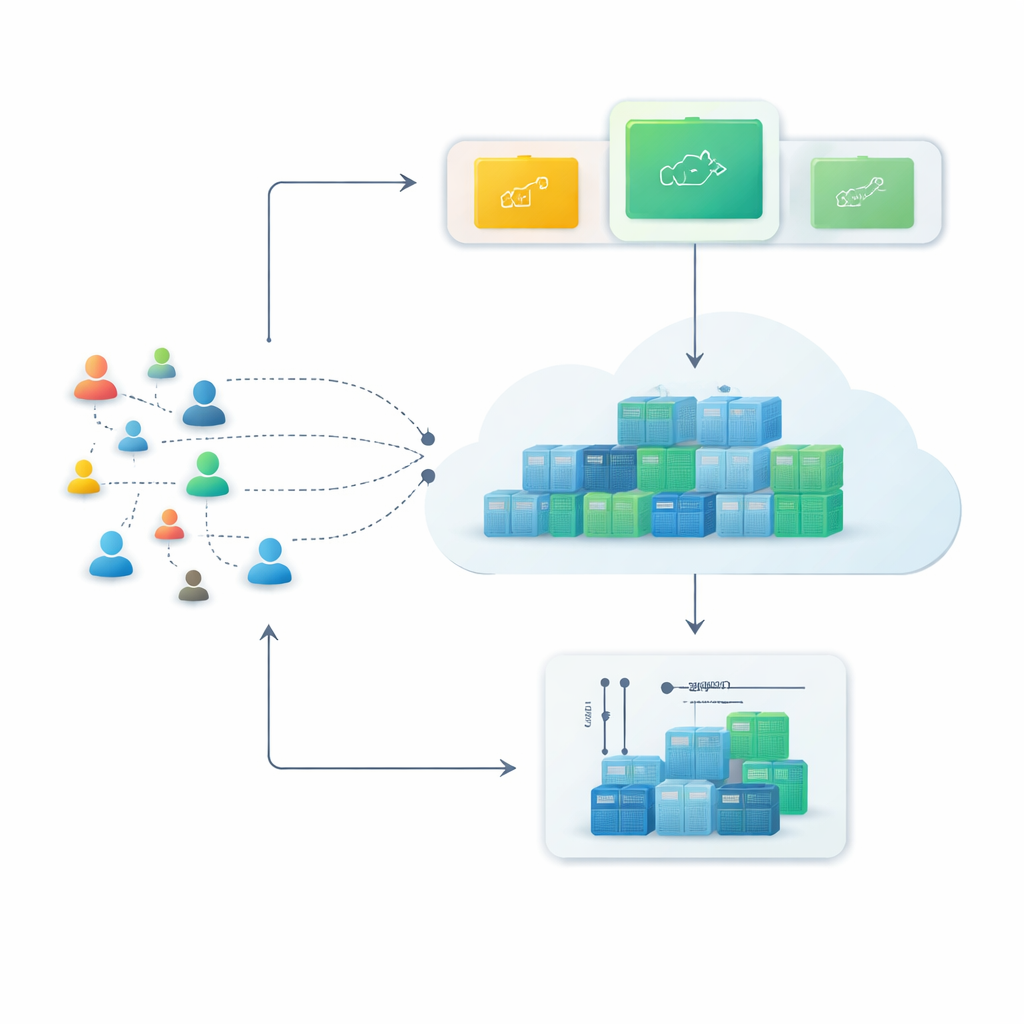
Sert sunuculardan esnek konteynerlere
Modern bulut platformları giderek konteynerlere dayanıyor; birkaç saniyede başlatılıp durdurulabilen küçük yazılım paketleri. Geleneksel sanal makinelerle karşılaştırıldığında konteynerler daha hafif ve daha yoğun paketlenebilir, bu da yoğun saatlerde hızla büyümesi ve sonrasında tekrar küçülmesi gereken servisler için ideal kılar. Ancak bu esneklik, sistem sorunları önceden görebiliyorsa işe yarar—yani önümüzdeki birkaç dakikada kaç web isteği geleceğini tahmin edebiliyor ve önceden doğru sayıda konteyner hazırlayabiliyorsa.
Neden tek tip tahmin başarısız olur
Önceki araştırmalar, klasik istatistiklerden derin sinir ağlarına kadar trafiği tahmin etmek için pek çok yol denedi. Bazı yöntemler talep gün içinde yumuşakça değiştiğinde iyi çalışıyor; diğerleri ise Dünya Kupası gibi beklenmedik sıçramaların olduğu durumlarda daha iyi oluyor. Sorun şu: hiçbir yöntem her zaman en iyi değil. Operatörler tek bir favori modeli seçip ona bağlı kalırsa, kullanıcı davranışı değiştiğinde doğruluk keskin biçimde düşebilir; bunun sonucu ya yavaş siteler olur ya da az kullanılan makineler sessizce para ve enerji tüketir.
Asla durmayan bir öğrenme döngüsü
Bunu aşmak için yazarlar Monitor–Train–Test–Deploy adını verdikleri kapalı döngü bir çerçeve öneriyor. Fikir, tahmini canlı bir süreç olarak ele almak. Önce sistem gelen web isteklerini zaman damgalı bir geçmişe sürekli kaydeder. Ardından birkaç farklı tahmin yöntemini paralel olarak eğitir; her biri bu yakın geçmişteki örüntüleri öğrenmeye çalışır. Sonra bu aday modelleri en son veriler üzerinde test eder ve tahminlerinin gerçekten ne kadar saptığına göre puanlar. Sadece en iyi performans gösteren model canlı tahminler yapmakla görevlendirilir; bu tahminler kaç konteyner çalıştırılacağına rehberlik eder. Yeni trafik geldikçe döngü tekrar eder: tahmin hataları artıp iki döngü üst üste tolere edilen seviyeyi aşarsa, sistem otomatik olarak yeniden eğitim yapar ve kontrolü farklı bir modele devredebilir.
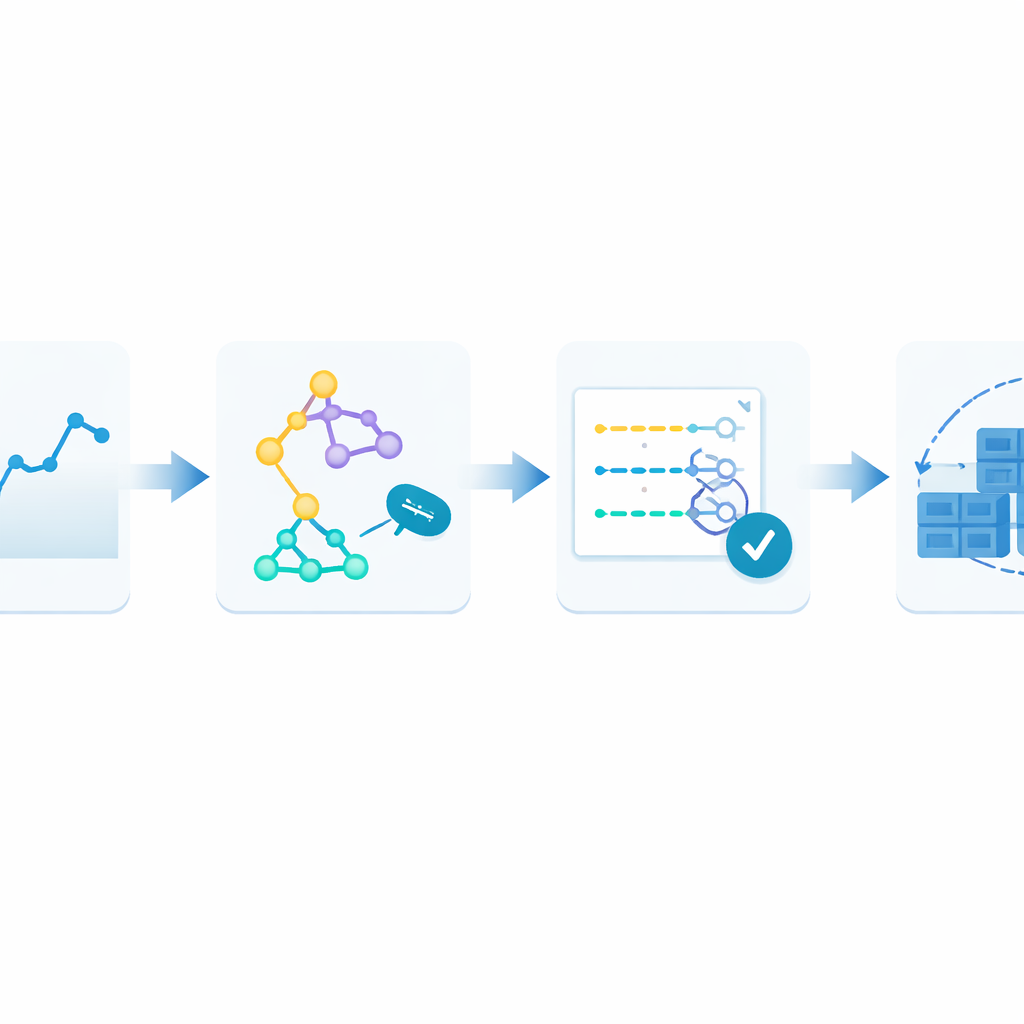
Çerçeveyi teste koymak
Araştırmacılar bu yaklaşımı hem sayısal hem de gerçek web etkinliği izleri kullanarak değerlendirdiler. Birkaç idealize desen ürettiler—yumuşak çan eğrileri, farklı hızlarda sürekli yükselen yükler ve oldukça düzensiz trafik—ve ayrıca ilginin ani arttığı 1998 ve 2018 Dünya Kupası resmi sitelerinin kayıtlarını kullandılar. Her durum için istatistik tabanlı bir yöntem, destek vektör modeli, karar ağacı topluluğu ve ileriki deneylerde popüler bir çeşit geri beslemeli sinir ağı dahil olmak üzere üç ya da dört tanıdık tahmin aracını karşılaştırdılar. Önemli sonuç şuydu: “kazanan” durumla birlikte değişti—talep istikrarlı olduğunda basit istatistiksel modeller öne çıktı, trafik vahşi ve patlamalı hale geldiğinde ise öğrenme tabanlı yöntemler açıkça üstün oldu.
Doğruluk ve verimlilikte kazanımlar
Gözlemlenen davranışa o an için en uygun modele sürekli geçiş yaparak, çerçeve sabit bir modele bağlı kalmaya kıyasla tahmin hatalarını yaklaşık yüzde 15'e kadar azaltabildi. Aynı derecede önemli olan, bunu tüm modelleri sürekli çalıştırmadan yapmasıydı. Canlı işletimde yalnızca bir tahminci aktiftir; diğerleri periyodik olarak yeniden eğitilir ve kontrol edilir, bu da hesaplama yükünü makul tutar. Yazarlar ayrıca ne zaman yeniden eğitim yapılacağına dair kademeli olarak sıkılaştırılan bir eşik tanımlıyor; böylece sistem tekrar eden hatalara karşı daha az toleranslı hale geliyor ve uzun süreli kötü tahmin riski azalıyor.
Günlük bulut kullanıcıları için anlamı
Pratikte çalışma, tahmin modellerinin rekabet etmesine izin vererek ve seçimlerini zaman içinde uyarlayarak bulut platformlarının daha akıllıca işletilebileceğini gösteriyor. Kullanıcılar için bu, büyük etkinlikler sırasında daha pürüzsüz çevrimiçi deneyimler ve kalabalıklar aniden ortaya çıktığında daha az yavaşlama anlamına gelebilir. Sağlayıcılar içinse daha yalın kaynak kullanımı, daha düşük işletme maliyetleri ve daha az israf edilmiş enerji vadeder. Tek bir zeki algoritmaya bahis yapmak yerine, bu çalışma talebi öngörme biçimini sürekli öğrenen, test eden ve revize eden esnek bir kontrol döngüsünü savunuyor.
Atıf: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Anahtar kelimeler: bulut iş yükü tahmini, otomatik ölçeklendirme, konteynerler, makine öğrenimi, zaman serisi