Clear Sky Science · tr
Hassas veriler için isteğe bağlı ve kısmi karıştırma kullanan bazı yeni nicel rastgele yanıt modelleri
Zor sorular sormak neden bu kadar zor
Uyuşturucu kullanımı, gizli gelir, vergi kaçırma veya yasadışı davranışlar gibi en önemli toplumsal soruların birçoğu, insanların dürüstçe yanıtlamak istemediği türden sorulardır. Yargılanma veya cezalandırılma korkusu varsa, insanlar yalan söyleyebilir veya yanıt vermeyi reddedebilir; bu da anket sonuçlarını yanıltıcı hale getirir. Bu makale, kişilerin kişisel yanıtlarını güvenli biçimde gizlerken araştırmacıların nüfustaki bu tür hassas davranışların ne kadar yaygın olduğunu yüksek doğrulukla ölçmelerine olanak veren yeni anket tasarımları sunar.
Şans gizliliğinizi nasıl koruyabilir
1960’lardan beri istatistikçiler rastgele yanıt adı verilen zekice bir hile kullanıyorlar. Hassas bir soruyu doğrudan yanıtlamak yerine, kişi gerçeği söyleyip söylememeye karar vermek için madeni para atma veya döndürgeç gibi rastgele bir araç kullanır. Rastgele aracın sonucunu yalnızca cevaplayan gördüğü için dışarıdan hiç kimse belirli bir yanıtın gerçek olup olmadığını bilemez. Yine de rastgele kurallar bilindiğinde araştırmacılar tüm grup için doğru ortalamaları yeniden oluşturabilir. Sonraki çalışmalar bu fikri evet–hayır sorularından sayısal sorulara genişletti; örneğin bir kişinin kaç kez kanunu çiğnediği veya ne kadar kayıtsız gelir olduğu gibi.

İnsanların ne kadarını gizleyeceklerini seçmelerine izin vermek
Geleneksel gizlilik yöntemleri herkese aynı muamelenin yapılmasını öngörür: her yanıtlayanın cevabı aynı şekilde karıştırılır, oysa bazı kişiler soru konusunda özellikle endişeli olmayabilir. Bu “tek beden herkese uyar” yaklaşımı bilgi israfına yol açabilir ve ihtiyatlı kişilerin kendilerini güvende hissetmesini sağlayamayabilir. Bunu düzeltmek için araştırmacılar isteğe bağlı modeller geliştirdiler. Bu modellerde her kişi rahatlık seviyesine bağlı olarak ya gerçek sayısını bildirebilir ya da karıştırılmış bir versiyon gönderebilir. Yeni çalışma, sayısal veriler için bu fikri geliştirerek doğrudan yanıtları çeşitli karıştırma türleriyle harmanlayan—bazen rastgele gürültü ekleyen, bazen rastgele bir faktörle çarpan, bazen de birkaç aşamalı rastgeleleştirme kullanan—dört model oluşturuyor.
Güvenlik ve doğruluk arasında denge kurmanın dört yeni yolu
Yazarlar M1’den M4’e etiketlenen dört ilişkili model tanıtıyor. Hepsi nüfustaki hassas bir sayının ortalama düzeyini yanlılık olmadan tahmin etmeyi hedefliyor; yani ortalamada gerçek değeri geri verirler. M1, mevcut bir yöntemi ikinci bir rastgeleleştirme aşaması ekleyerek genişletir; bu, herhangi bir kişinin yanıtı hakkında belirsizliği artırırken genel hesabı basit tutar. M2, bazı kişilerin doğrudan yanıt verdiği bir ilk adımı, sonra yanıtları ya çarpma yoluyla ya da rastgele gürültü ekleyerek karıştıran ikinci bir adımla birleştirir. M3 ve M4 önceki çoklu seçenekli tasarımları daha da genelleştirerek cevaplayıcılara gerçek değerlerinin birkaç olası karıştırılmış formunu sunar. Bu ek tercih ve rastgelelik katmanları bireyler için daha fazla “örtü” sağlar, aynı zamanda istatistikçilerin genel deseni çözmesine olanak tanır.
Hem gizliliği hem de kesinliği ölçmek
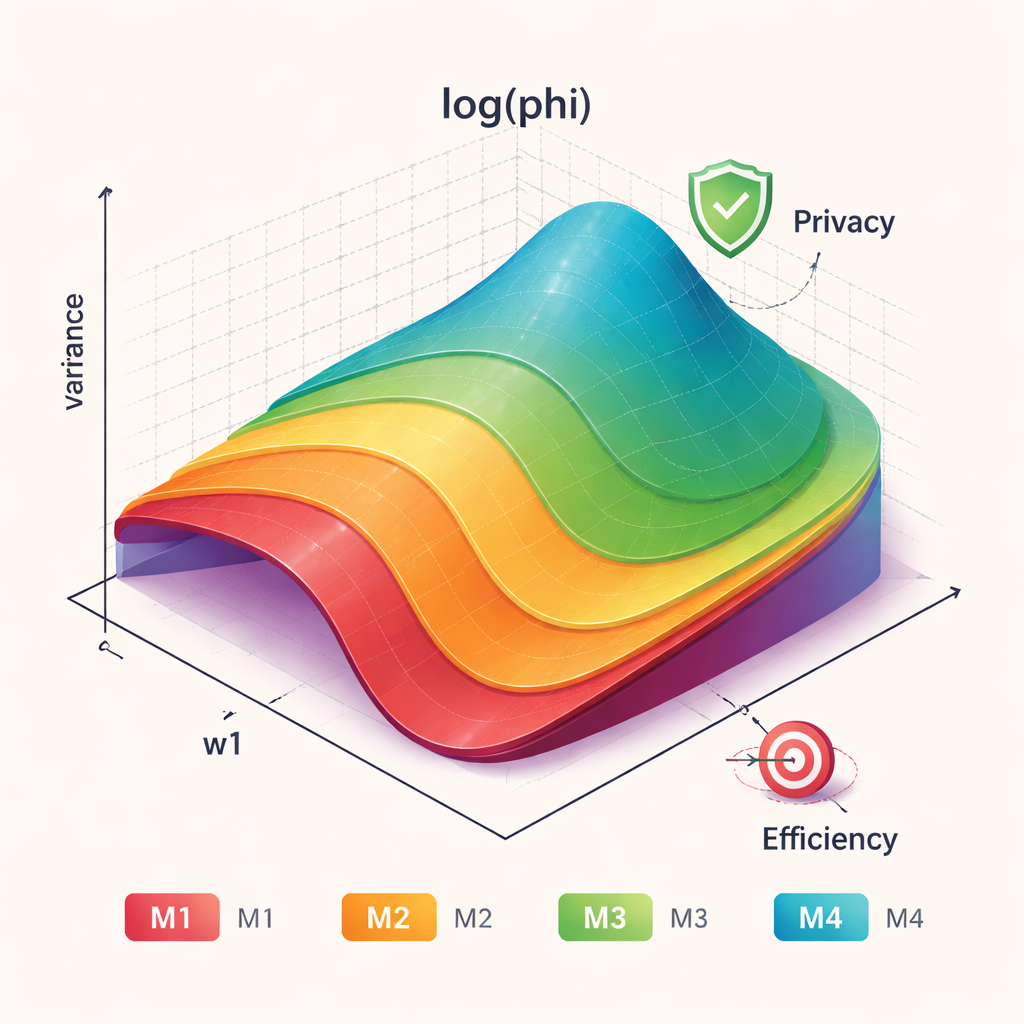
Daha fazla karıştırma insanları koruyabilir ama veriyi de bulanıklaştırabilir; bu yüzden önemli soru gizlilik ile kesinlik arasındaki takasın nasıl değerlendirilmesi gerektiğidir. Yazarlar dört modellerini yedi bilinen önceki yöntemle birkaç ölçüt kullanarak karşılaştırıyor. Nihai tahminin ne kadar değişken olduğunu yansıtan istatistiksel verimlilik ve bildirilen değerlerin bir kişinin gerçek sayısından ne kadar uzaklaştığını yakalayan gizlilik ölçüleri inceleniyor. Ayrıca analistin gizlilik ile verimlilik arasında ne kadar ağırlık vermek istediğini seçmesine imkân tanıyan phi adlı birleşik bir puan kullanılıyor. Geniş bir ayar yelpazesinde, yeni modeller—özellikle M1 ve M4—eski yöntemlere kıyasla tutarlı biçimde daha iyi birleşik puanlar gösteriyor.
Hassas bir konu için doğru aracı seçmek
Çalışma, tek bir modelin tüm durumlar için en iyi olduğunu iddia etmiyor. Bunun yerine her yaklaşımın ne zaman kullanılacağına dair açık rehberlik sunuyor. Bireysel gizliliği korumak birincil öncelikse ve araştırmacılar biraz daha istatistiksel gürültüyü kabul etmeye razıysa, M1 ile M3 arası modeller öneriliyor. Bu modeller tek bir kişinin gerçek yanıtının kolayca tahmin edilemeyeceğine dair güçlü garantiler veriyor. Anket düzenleyenler sınırlı veriden mümkün olduğunca çok doğruluk çıkarmaya—örneğin küçük veya maliyetli çalışmalarda—daha fazla önem veriyorsa, M4 genellikle en iyi performansı sergiliyor. Genel olarak, uzman olmayanlar için verilen mesaj güven verici: anketin arkasındaki rastgele kuralları dikkatle tasarlayarak, çok hassas sayısal soruları hem katılımcılar için etik açıdan daha güvenli hem de bilimsel olarak daha güvenilir bir şekilde sormak mümkün.
Atıf: Iqbal, S., Hussain, Z. & Omer, T. Some new quantitative randomized response models using optional and partial scrambling for sensitive data. Sci Rep 16, 7734 (2026). https://doi.org/10.1038/s41598-026-40714-0
Anahtar kelimeler: gizliliği koruyan anketler, rastgele yanıt, hassas veriler, anket metodolojisi, istatistiksel gizlilik