Clear Sky Science · tr
Sinir ağlarındaki tam özellik çakışmaları
Farklı Görüntüler Akıllı Bir Makineyi Ne Zaman Kandırır
Günümüz yapay zeka sistemleri yüzleri tanıyabiliyor, tıbbi görüntüleri okuyabiliyor ve sürücüsüz araçları yönlendirebiliyor. Küçük, özenle hazırlanmış değişikliklerle bir görüntünün kandırılabileceğini zaten biliyoruz. Bu makale daha da şaşırtıcı bir şeyi gösteriyor: aynı ağlar bazen büyük, bariz değişikliklere kör olabilir ve çok farklı görüntüleri sanki aynıymış gibi işlemeye devam edebilir. Bu durumun nasıl ve neden gerçekleştiğini anlamak, gerçekten güvenebileceğimiz yapay zekâ sistemleri istiyorsak hayati önem taşıyor.
Ufak Dokunuşlardan Büyük Kör Noktalara
Derin sinir ağları bugün görme, dil ve pek çok alandaki ilerlemelerin temelini oluşturuyor. Adversarial örnekler üzerine yapılan önceki araştırmalar, neredeyse görünmez bir değişikliğin bir ağı yüksek güvenle yanlış sınıflandırmaya sürükleyebileceğini ortaya koydu. Daha yakın tarihli çalışmalar ise tersine bir sorunu açığa çıkardı: bazı ağlar büyük, bariz değişikliklere neredeyse hiç tepki vermiyor ve hemen hemen aynı tahminleri üretmeye devam ediyor. Bu durumlarda, iki çok farklı görüntüden çıkarılan iç özellikler “çakışıyor”, yani ağ bunları neredeyse aynı şekilde temsil ediyor. Bu çalışma bu fikri daha da ileri taşıyarak, yaygın ağların yalnızca yaklaşık çakışmalara değil, iki farklı girdinin tam olarak aynı iç sinyallere eşlendiği tam özellik çakışmalarına sahip olabileceğini kanıtlıyor.
Çakışmalar Ağın İçinde Nasıl Oluşur
Bu çakışmaları açıklamak için yazarlar sinir ağlarının içini inceliyor ve katmanları birbirine bağlayan, eğitimli sayı olan ağırlık matrislerine odaklanıyor. Bir özellik çakışması, iki farklı girdinin bir katmanda aynı çıktıyı ürettiği zaman ortaya çıkar; bu gerçekleştiğinde, sonraki tüm katmanlar da aynı şeyi gördüğü için girdileri ayırt edemez. Matematiksel olarak bu, iki girdi arasındaki farkın bir katmanın ağırlıklarının “null space”inde—yani katmanın tamamen göz ardı ettiği giriş uzayı yönlerinde—olduğu durumlarda meydana gelir. Yazarlar, bir ağırlık matrisinin sıfır özdeğere sahip olduğu veya daha yüksek boyutlu bir uzaydan daha düşük boyutlu bir uzaya haritalama yaptığı her durumda, böyle göz ardı edilen yönlerin kaçınılmaz olduğunu gösteriyor. Çünkü sınıflandırma, segmentasyon ve nesne tespiti için popüler modeller dahil olmak üzere çoğu gerçek dünya mimarisi birçok böyle katman kullanıyor, çakışmalar nadir kenar durumlar değil, bu ağların neredeyse kaçınılmaz bir özelliği oluyor.
Çakışan Girdiler Oluşturmanın Yeni Bir Yolu
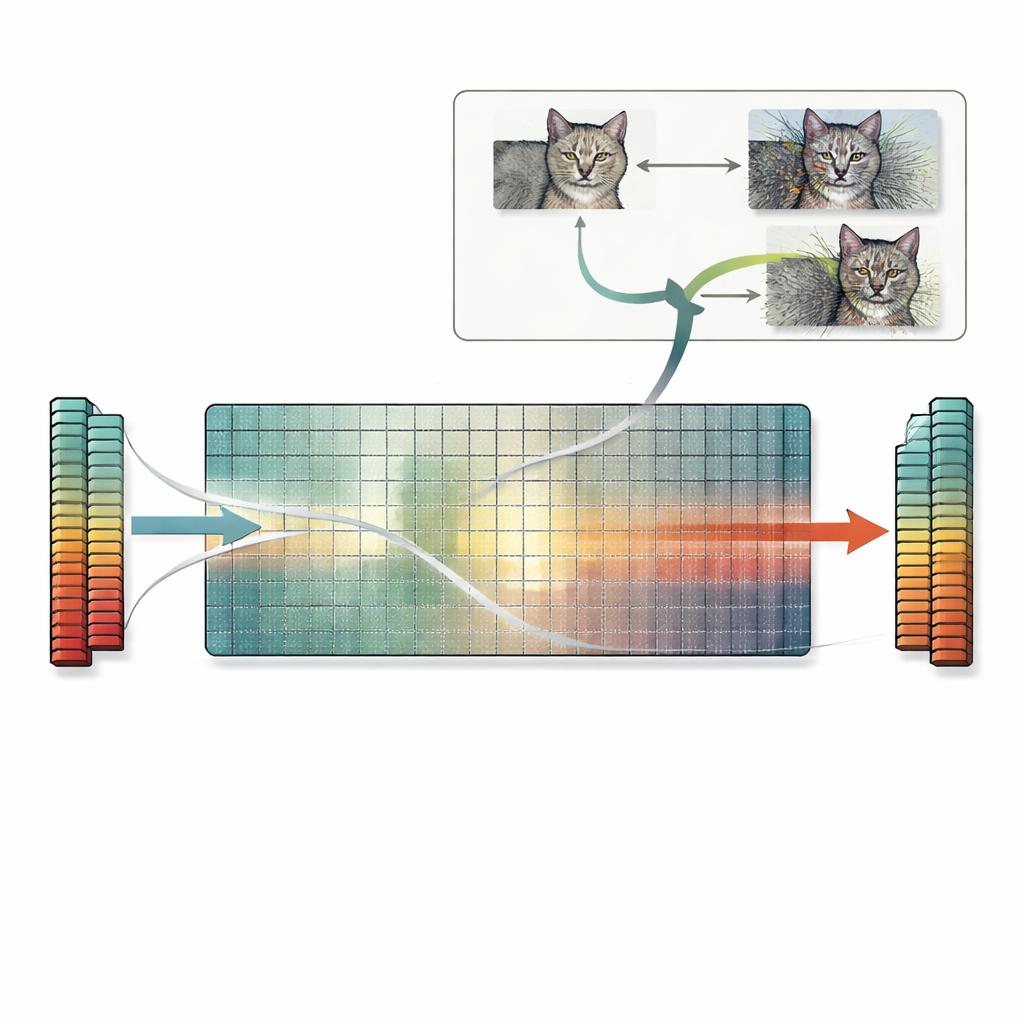
Bu içgörü üzerine inşa edilen makale, boşluk-uzayı araması (null-space search) adında pratik bir reçete sunuyor. Deneme-yanılma veya gradyan tabanlı hilelere dayanmak yerine, bu yöntem doğrudan ilk ağırlık matrisinin null space’ini kullanıyor. Herhangi bir görüntüden başlayarak, yazarlar ilk katmanın görmediği bir vektör hesaplıyor ve sonra bu vektörün ölçeklenmiş bir versiyonunu görüntüye ekliyor. Çünkü o yön katman için görünmez, ağın iç özellikleri—ve son tahmini—tam olarak aynı kalıyor; görüntü insan gözüne ciddi şekilde bozulmuş görünse bile. Aynı fikir evrişimsel katmanlara ve prensipte daha sonraki katmanlara da genişletilebiliyor. Yazarlar birçok standart modeli tarayarak çoğunun bu tür göz ardı edilen yönlere bolca sahip olduğunu buluyor; bu da çok çeşitli görevler için sayısız çakışan görüntünün bu şekilde üretilebileceği anlamına geliyor.
Benzerlik, Açıklamalar ve Güvenlik İçin Gizli Riskler
Bu tam özellik çakışmalarının kapsamlı sonuçları var. Çakışan özelliklere sahip iki görüntü yalnızca aynı tahmine sahip olmakla kalmayacak, aynı zamanda popüler yorumlama araçlarının ürettiği açıklama haritalarını da sıklıkla paylaşacaktır. Bu, tanınmayan, ağır şekilde bozulmuş bir görüntünün temiz bir görüntü kadar iyi desteklenmiş görünmesine neden olabilir ve açıklama yöntemlerine olan güveni sarsar. Sorun aynı zamanda sinir ağlarına dayalı özellik temelli benzerlik ölçütlerini de etkiler: bu tür metrikler, özellikler tam olarak eşleştiği için ağır şekilde bozulmuş bir görüntüyü orijinaliyle “özdeş” olarak değerlendirebilir; oysa basit piksel tabanlı skorlar büyük farkları doğru şekilde işaretler. Son olarak, boşluk-uzayı araması standart adversarial saldırılarla birleştirilebilir; bu da aynı yanlış tahmini veren ve standart bozulma sınırları içinde kalan birçok farklı adversarial görüntü üretilmesine yol açarak mevcut güvenlik endişelerini derinleştirir.
Daha Güvenli Yapay Zekâ İnşası İçin Anlamı
Düz ifadeyle, bu çalışma günümüz sinir ağlarının çoğunun bilgiyi öngörülebilir şekillerde attığını, kararlarını hiç etkilemeyen giriş uzayında tüm yönlerin bırakıldığını gösteriyor. Saldırganlar bu kör noktaları, bir ağı normal olanlarla aynı muamelesini yapan tuhaf veya adversarial görüntüler oluşturmak için kullanabilir. Yazarlar, bir modelin ne kadar savunmasız olabileceğini ölçmenin bir yolu olarak bu göz ardı edilen yönlerin basit sayımlarının kullanılmasını öneriyor ve daha ince, daha iyi düzenlenmiş ağların daha küçük null space’lere sahip olarak daha dayanıklı olabileceğini savunuyor. Pratikte daha birçok şeyin test edilmesi gerekse de, temel mesaj açık: güvenilir yapay zekâ istiyorsak, ağların neye tepki verdiğine olduğu kadar neyi görmezden geldiğine de dikkat etmeliyiz.
Atıf: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Anahtar kelimeler: sinir ağları, adversarial örnekler, özellik çakışmaları, model dayanıklılığı, boşluk-uzayı araması