Clear Sky Science · tr
KM-DBSCAN: yeşil yapay zeka doğrultusunda veri indirgeme için geliştirilmiş yoğunluk ve merkez tabanlı sınır tespit çerçevesi
Yapay zekayı küçültmek neden onu daha çevreci yapabilir
Yapay zekanın görünmeyen bir maliyeti var: elektrik. Modern makine öğrenimi modellerini eğitmek genellikle milyonlarca veri noktasını enerji tüketen donanımda işlemenizi gerektirir ve bu da karbon emisyonlarına yol açar. Bu makale, modellerin gerçekten ihtiyaç duyduğu bilgileri atlamadan veri setlerini eğitim öncesi küçültmenin yeni bir yolu olan KM-DBSCAN'i tanıtıyor. En bilgilendirici verileri tutarak yöntem öğrenmeyi hızlandırıyor, enerji kullanımını düşürüyor ve el yazısı rakam tanımadan cilt kanserinin erken tespitine kadar çeşitli görevlerde hâlâ doğru tahminler veriyor.
Çok fazla veri, çok fazla enerji
Yıllarca yapay zekada hakim inanç daha fazla verinin neredeyse her zaman daha iyi modeller getirdiği oldu. Bu doğruluğu artırabilse de daha uzun eğitim süreleri, daha güçlü bilgisayarlar ve daha yüksek elektrik faturaları anlamına gelir. Araştırmacılar, her maliyete razı olarak doğruluğu kovalayan "Kırmızı AI" ile performansı çevresel etkiyle dengelemeye çalışan "Yeşil AI" ayrımını yapmaya başladılar. Daha çevreci yapay zekaya giden umut verici yollardan biri veri indirgeme: modele mevcut tüm örnekleri vermek yerine, özellikle bir sınıflandırıcının kararlarını belirleyen zorlu sınır durumlarını iyi tanımlayan çok daha küçük bir örnek kümesi belirlemek.
İki basit fikri birleştirip akıllı bir filtre haline getirmek
KM-DBSCAN çerçevesi, ham veriye akıllı bir filtre görevi görecek şekilde iki iyi bilinen kümeleme tekniğini birleştirir. Önce K-Ortalamalar (K-Means) adı verilen hızlı bir yöntem noktaları kompakt kümelere ayırır ve her grubu temsil eden bir merkez — yani bir merkezî nokta — ile değiştirir. Bu, problemi binlerce ya da milyonlarca noktadan birkaç yüz temsilciye indirger. Ardından, merkezler üzerinde yoğunluk tabanlı bir yöntem (DBSCAN) çalıştırılarak hangi bölgelerin kümeler arası sınırda, hangilerinin yoğun, homojen iç kısımda ya da izole parazit (gürültü) olduğuna bakılır. DBSCAN, merkez düzeyinde çalıştırıldığında çok daha hızlı olur ve tüm veri noktalarına doğrudan uygulandığındaki parametre hassasiyetine kıyasla daha az kırılgandır.

Sadece zorlayıcı, bilgilendirici örnekleri tutmak
KM-DBSCAN farklı grupların nerede temas ettiğini veya örtüştüğünü belirledikten sonra yalnızca bu sınırların yakınındaki veri noktalarını tutar; derin iç noktaları ve belirgin aykırıları atar. İç noktalar büyük ölçüde tekrarlayıcıdır: hepsi benzer görünür ve modele sınıfları hakkında aynı mesajı gönderir. Buna karşılık sınır noktaları modele bir sınıfın nerede bittiğini ve diğerinin nerede başladığını tam olarak söyler. Sentetik oyuncak veri setlerinde bu strateji, çoğu nokta kaldırılmış olsa bile bir sınıflandırıcının tam veriden öğrendiğiyle aynı karar sınırlarını yeniden üretebiliyor. Banana, USPS rakamları, Adult gelir veri seti, araç çarpışma verileri, kuru fasulye çeşitleri ve melanom cilt görüntüleri gibi gerçek dünya veri setlerinde ise küçültülmüş kümeler problemin ana yapısını korurken orijinalin büyüklüğüne göre bir büyüklük mertebesi daha küçük oluyor.
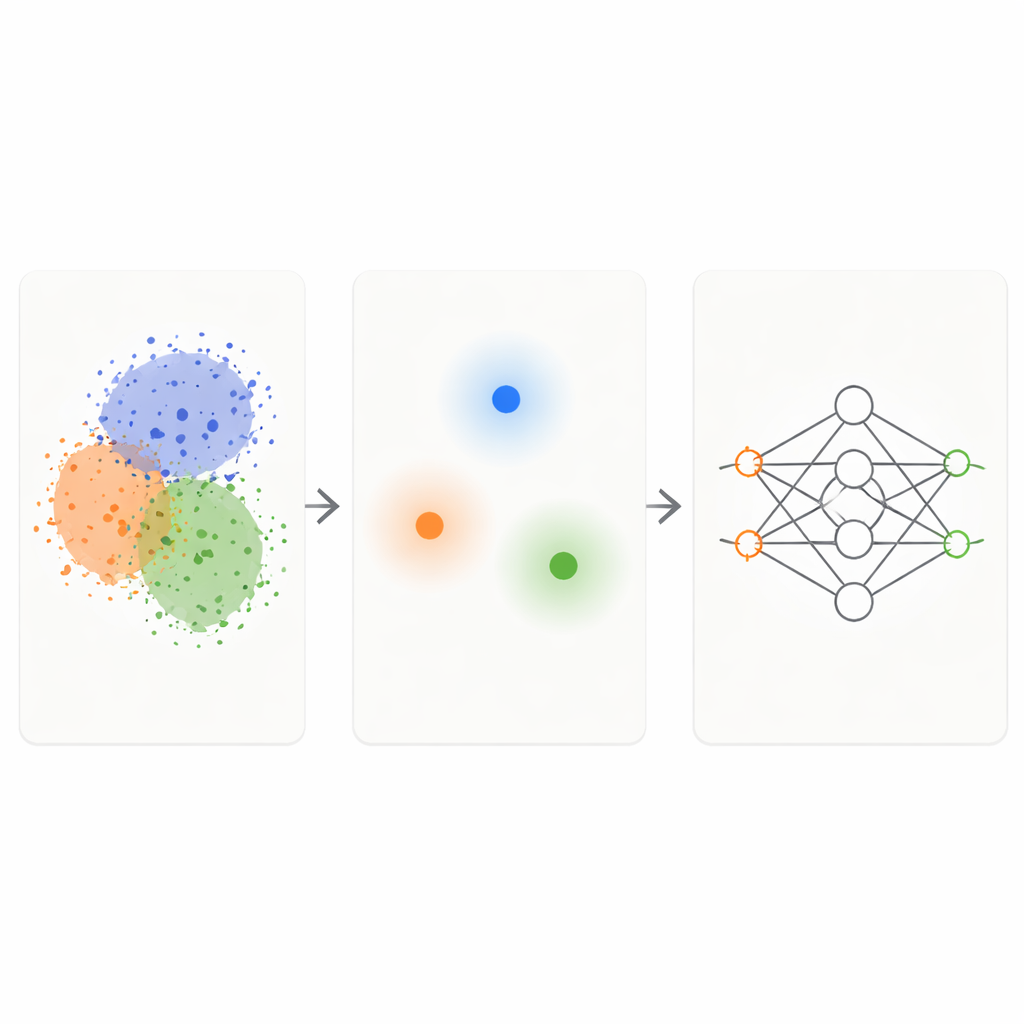
Hız, karbon tasarrufu ve gerçek uygulamalar
Yazarlar KM-DBSCAN'i destek vektör makineleri, çok katmanlı algılayıcılar ve evrişimli sinir ağları dahil olmak üzere çeşitli yaygın modellerin ön işlemi olarak test etti. Birçok durumda, azaltılmış veri üzerinde eğitim on katlarca, yüzlerce veya binlerce kez daha hızlı olurken doğruluk neredeyse aynı kaldı—bazen hafifçe iyileşti bile. Örneğin el yazısı rakam tanımada yöntem eğitim kümesini orijinal boyutunun yalnızca %1,4üne indirdi ama doğruluğu artırdı ve eğitimi 284 kat daha hızlı hale getirdi. Dengesiz sınıfların bulunduğu bir gelir tahmin görevinde, verinin yalnızca ~%3'ü kullanılarak doğrulukta çok az kayıpla 6907 kat hızlanma sağlandı. Bir melanom tespit deneyinde ise derin bir sinir ağı, orijinal cilt görüntüsü veri setinin üçte birinden azı ile eğitilirken %90’ın üzerinde doğruluk elde etti ve karbon emisyonları %70’ten fazla azaltıldı.
Günlük yapay zeka için bunun anlamı
Uzman olmayanlar için ana mesaj, daha akıllıca seçimlerin salt hacmi yenebileceğidir. KM-DBSCAN, bir modelin hangi örnekleri gördüğünü dikkatle seçmenin—en bilgilendirici sınır vakalarına odaklanmanın—hesaplama zamanı ve enerji kullanımını nasıl kesebileceğini ve yine de güvenilir tahminler sunabileceğini gösteriyor. Bu yaklaşım, veri kalitesinin ve eğitim hattının düşünceli tasarımının hammadde model büyüklüğü kadar önemli olduğu Yeşil AI yöneliminin geneline iyi uyuyor. Geniş çapta benimsenirse, bu tür veri farkındalıklı filtreleme tıptan trafik güvenliği sistemlerine kadar pek çok alanda daha sürdürülebilir çözümler sağlayabilir ve büyük hesaplama kaynaklarına sahip olmayan kuruluşların da güçlü yapay zeka araçlarına erişimini kolaylaştırabilir.
Atıf: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Anahtar kelimeler: yeşil yapay zeka, veri indirgeme, kümeleme, makine öğrenmesi verimliliği, melanom tespiti