Clear Sky Science · tr
R-GAT: sınırlı veri senaryoları için grafik tabanlı artık ağ kullanan kanser belge sınıflandırması
Kanser makalelerini sınıflandırmanın önemi
Her gün bilim insanları erken tanıdan umut verici ilaçlara kadar kanser üzerine yüzlerce yeni çalışma yayımlıyor. Bu çalışmaların çoğu önce özetler halinde, yani makalelerin kısa tanımları olarak ortaya çıkıyor. Hekimler, araştırmacılar ve politika yapıcılar hepsini okumaya vakit bulamıyor; oysa önemli bir makaleyi kaçırmak ilerlemeyi yavaşlatabilir. Bu çalışma basit ama güçlü bir soruyu ele alıyor: sınırlı miktarda etiketli veri ve sınırlı hesaplama kaynağı olduğunda bile, kanserle ilgili özetleri kanser türüne göre otomatik olarak, hızlı ve hafif bir bilgisayar sistemiyle ayırmak mümkün mü?
Kanser araştırmasını okumanın daha akıllı bir yolu
Yazarlar PubMed veritabanında bulunan dört tür özet üzerine odaklanıyor: tiroid kanseri, kolon kanseri, akciğer kanseri ve daha genel biyomedikal konularla ilgili özetler. Bu dört grup arasında yaklaşık eşit büyüklükte, dikkatle denetlenmiş 1.875 adet güncel özetten oluşan bir koleksiyon oluşturdular. Bu denge, herhangi bir kanser türüne karşı önyargıyı azaltmaya yardımcı oluyor. Modelleme öncesinde metinler temizlendi: kelimeler tokenlere ayrıldı, yazım kontrolü yapıldı, ilişkili kelime formları birleştirildi ve bilgi taşımayan terimler çıkarıldı. Temizlenmiş özetler, farklı model türlerinin adil şekilde karşılaştırılabilmesi için çeşitli standart yöntemlerle sayısal forma dönüştürüldü.
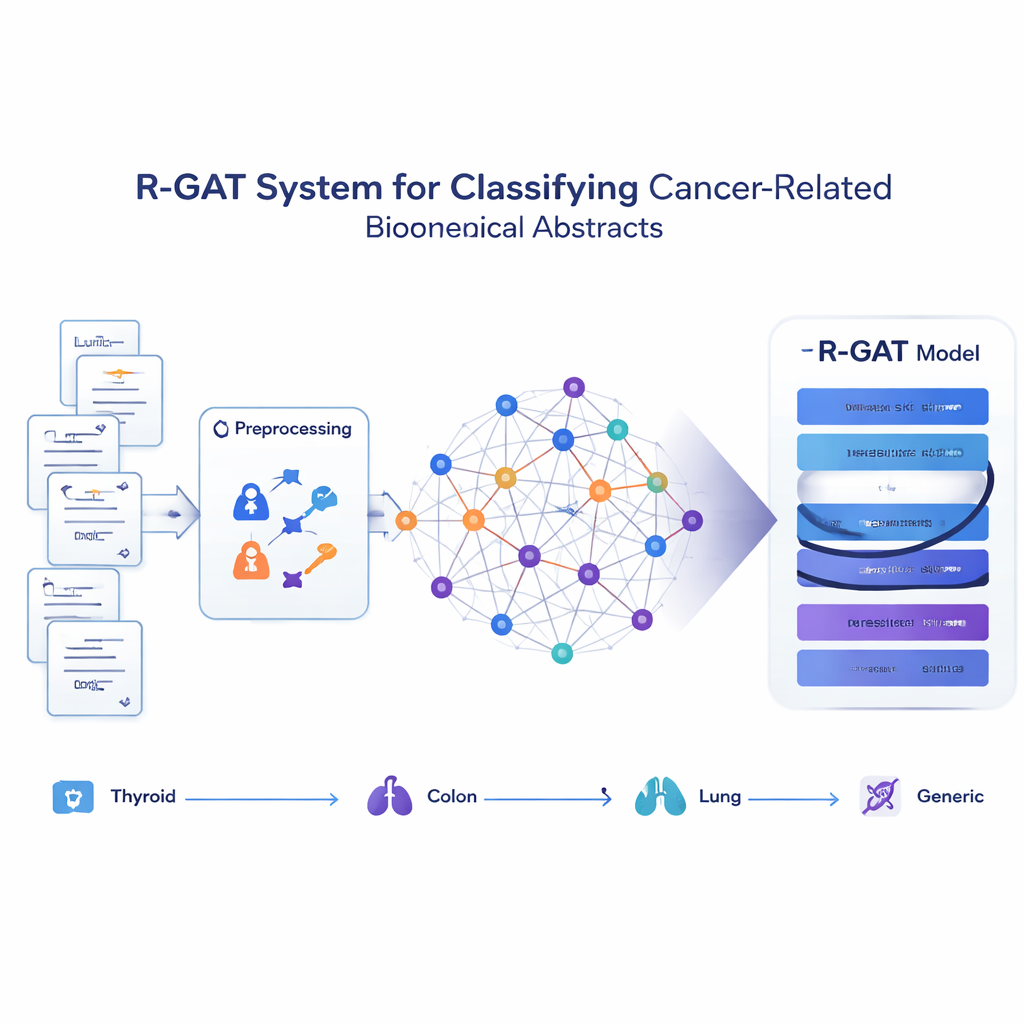
Makaleleri fikirlerin bir ağına dönüştürmek
Önerilen yöntem olan R-GAT (Residual Graph Attention Network), her özeti izole bir kelime dizisi olarak ele almak yerine tüm koleksiyonu bir ağ olarak görüyor. Bu ağda her özet bir düğüm, bağlantılar ise iki özetin içerik açısından ne kadar benzer olduğunu temsil ediyor. İki makale yakından ilişkili konuları tartışıyorsa aralarındaki bağlantı güçlü; değilse zayıf ya da yok. Bu yaklaşım, modelin bir özeti komşuları bağlamında incelemesini sağlıyor; tıpkı bir insan okuyucunun ilgili çalışmaları bilerek bir çalışmayı daha iyi anlaması gibi.
Yeni modelin komşulardan öğrenme biçimi
R-GAT modern yapay zekanın iki temel fikri üzerine inşa ediliyor: dikkat (attention) ve artık bağlantıları (residual connections). Dikkat mekanizması modelin ağdaki tüm komşuları eşit görmek yerine en ilgili olanlara daha fazla odaklanmasını sağlıyor. Birden çok dikkat “başı” aynı anda farklı türde desenleri arıyor. Artık bağlantıları, derin ağ katmanları boyunca bilgiyi doğrudan ileten kısayollar gibi davranarak modelin öğrenme sırasında önemli sinyalleri kaybetmesini önlemeye yardımcı oluyor. Grafiği birkaç dikkat katmanı ve bu kısayol yolları üzerinden işledikten sonra sistem, tüm ağdan gelen bilgiyi sıkıştırarak son bir sınıflandırıcıya veriyor; bu sınıflandırıcı her özetin dört kategoriden hangisine ait olduğunu tahmin ediyor.
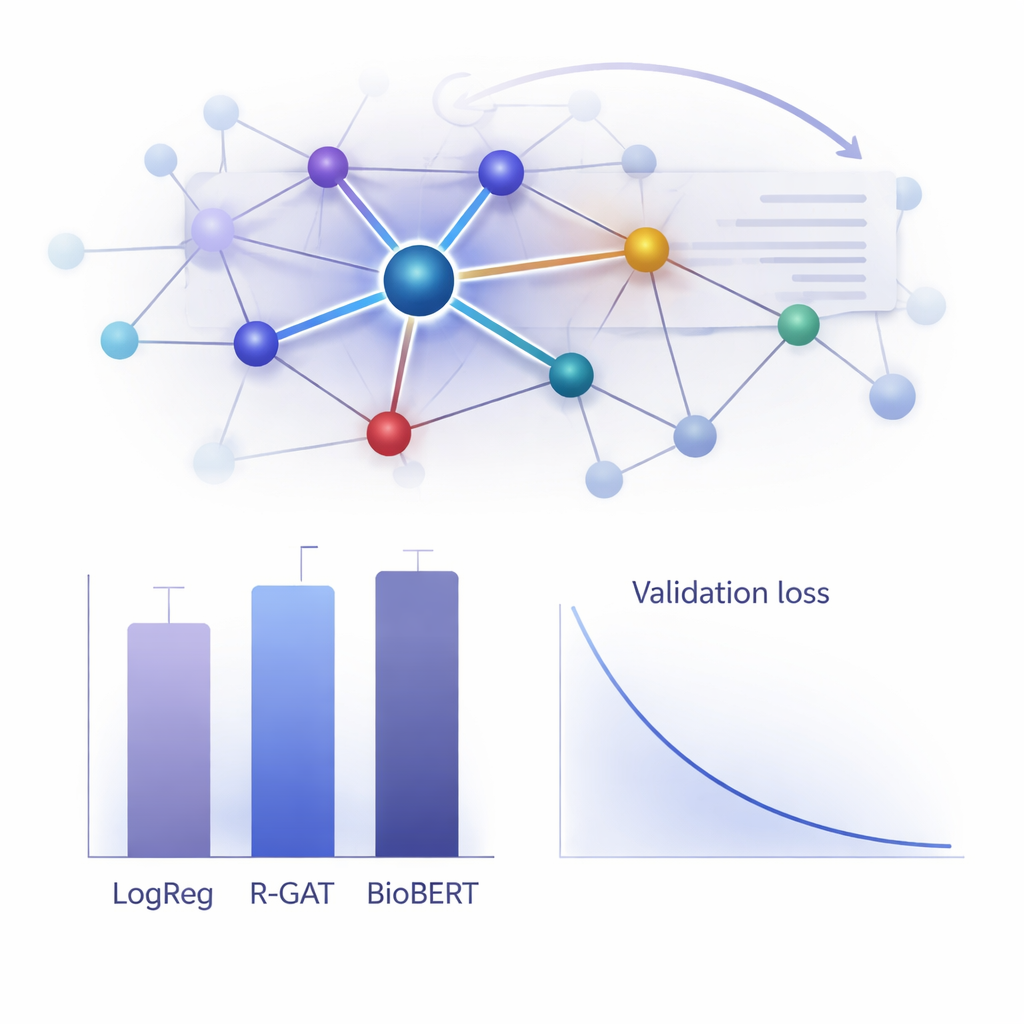
Pratikte ne kadar iyi çalışıyor?
R-GAT’in değerini değerlendirmek için yazarlar, klasik lineer modellerden popüler ama hesaplama açısından ağır olan BioBERT gibi son teknolojiye kadar geniş bir alternatif yelpazesiyle karşılaştırma yaptılar. Şaşırtıcı şekilde, kelime sayımı özelliklerini kullanan basit bir lojistik regresyon modeli bu özel veri setinde en yüksek ham skoru elde etti ve BioBERT de son derece iyi performans gösterdi—ancak her ikisinin de belirli özellik seçimlerine bağımlılık ya da önemli hesaplama gereksinimleri gibi dezavantajları vardı. R-GAT yaklaşık 0,96 makro F1-skora ulaşarak en iyi modellerine yakın bir performans sergiledi ve farklı eğitim–test bölünmeleri boyunca çok kararlı sonuçlar gösterdi. Dikkat ya da artık bağlantıları kaldırıldığında yapılan dikkatli testler performansta belirgin düşüşler gösterdi; bu da her iki bileşenin de veri sınırlı olduğunda modelin sağlamlığı için kritik olduğunu doğruluyor.
Gelecekteki kanser araştırmaları için anlamı
Bir uzman olmayan için çıkarım basit: R-GAT, devasa veri kümeleri ya da pahalı donanımlar gerektirmeden kanser araştırması makalelerini kanser türüne göre yüksek ve tutarlı doğrulukla ayırmaya yardımcı olan pratik bir araçtır. Piyasadaki en güçlü dil modellerinin yerini almaz, ancak güvenilir bir ara yol sunar—özellikle sıkı veri ve bütçe kısıtları altında güvenilir, tekrarlanabilir sonuçlara ihtiyaç duyan hastaneler, araştırma grupları veya halk sağlığı ekipleri için yararlıdır. Yazarlar hem modellerini hem de düzenlenmiş veri setlerini açıkça yayımlayarak başkalarının geliştirilmiş sistemler oluşturup test edebileceği ortak bir kıstas sağlıyor. Uzun vadede, bu tür araçlar uzmanların kanser literatürünü yakından takip etmelerini ve yeni bulguları daha iyi hasta bakımına dönüştürmelerini kolaylaştırabilir.
Atıf: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Anahtar kelimeler: kanser bilişimi, biyomedikal metin madenciliği, belge sınıflandırma, graf sinir ağları, sınırlı veriyle öğrenme