Clear Sky Science · tr
Yorumlanabilir makine öğrenmesi, konformal ve karşıgerçekçi öngörülerle karbonik anhidraz inhibitörlerini akılcı hale getiriyor
Neden daha akıllı kanser ilaçları önemli
Kanser ilaçları sıklıkla kaba araçlar gibidir: tümör hücrelerine saldırırken sağlıklı dokulara da zarar vererek ciddi yan etkilere yol açabilirler. Bu hedefi keskinleştirmenin umut vaat eden bir yolu, tümörlerin düşük oksijenli ortamlarda hayatta kalmasına yardımcı olan karbonik anhidraz adlı enzimin belirli varyantlarını bloke etmektir. Ancak bu enzimin birkaç varyantı neredeyse aynı göründüğü için, tümörlerdeki “zararlı” versiyonları vücutta yaygın bulunan “iyi” olandan ayıran ilaçlar tasarlamak zordur. Bu çalışma, yorumlanabilir makine öğrenmesinin araştırmacıların bu zorluğu aşmasına ve daha seçici, daha güvenli ilaç adayları tasarlamasına nasıl yardımcı olabileceğini gösteriyor.
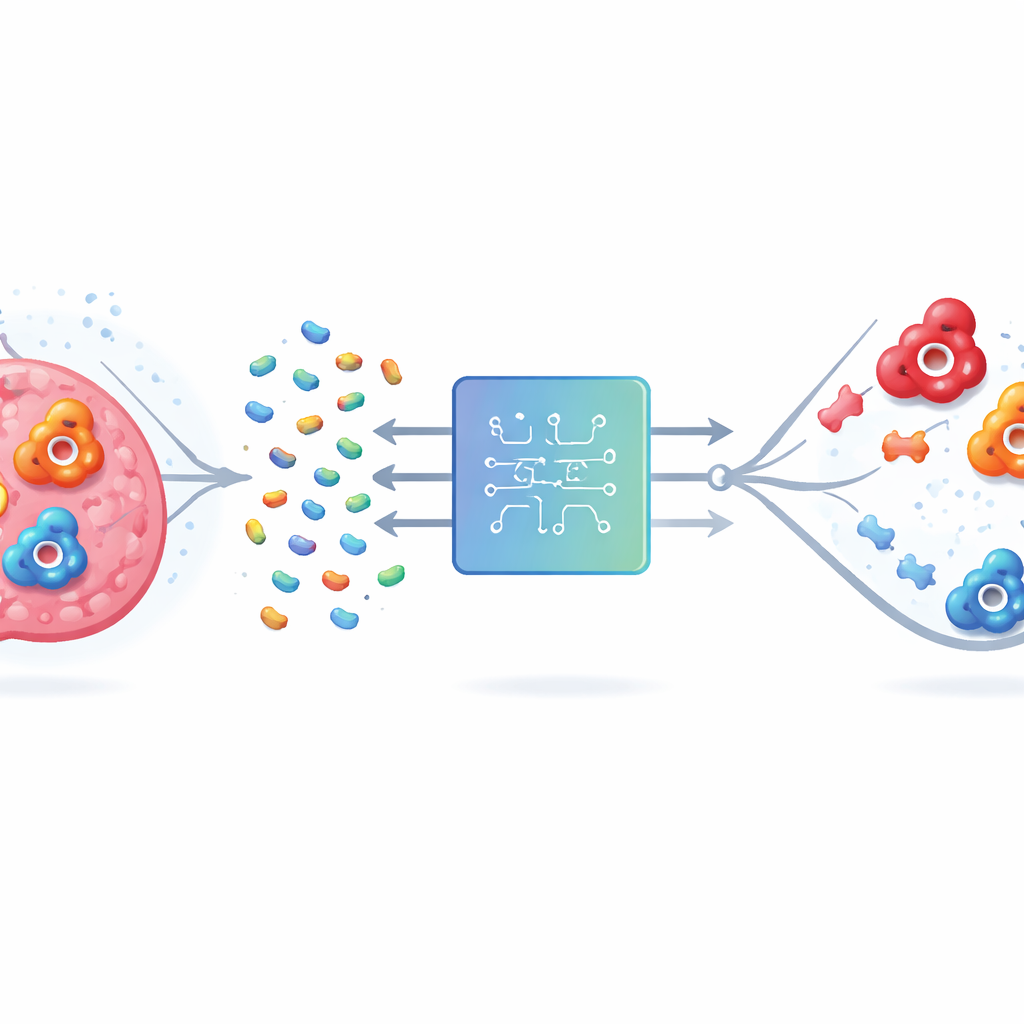
Yanlış hedefe isabet etme sorunu
İnsan karbonik anhidrazı (hCA) birçok formda, yani izoformda bulunur. Bunlardan IX ve XII, oksijenden yoksun tümörlerde kanser hücrelerinin hayatta kalmasıyla ilişkilidir; bu nedenle bunları engellemek hastalığı yavaşlatabilir ve tedaviyi iyileştirebilir. Ancak izoform II sağlıklı dokularda yaygındır ve aktif bölgesi IX ve XII ile çok benzer görünür. Üçüne birden bağlanan ilaçlar metabolik asidoz ve görme bozuklukları gibi istenmeyen sorunlara yol açabilir. Geleneksel laboratuvar ve bilgisayar yöntemleri zorluk yaşar çünkü enzimler büyük ve karmaşık moleküllerdir ve olası ilaç benzeri bileşiklerin sayısı astronomiktir. Bunların hepsini ya laboratuvarda ya da bilgisayarda eksiksiz test etmek pratik olarak mümkün değildir.
Temiz ve güvenilir bir veri temeli oluşturmak
Yazarlar bunun üstesinden gelmek için öncelikle ChEMBL veri tabanından hCA II, IX ve XII üzerine test edilmiş binlerce molekülden oluşan dikkatle temizlenmiş bir veri kümesi derlediler. Kimyasal yapıları standartlaştırdılar, kuşkulu ölçümleri çıkardılar ve bu inhibitör sınıfına tipik ortak bir çinko-bağlayıcı gruba sahip bileşiklere odaklandılar. Katı eşik değerleri kullanarak molekülleri açıkça aktif veya açıkça inaktif olarak etiketlediler ve modelleri yanıltabilecek sınırdaki vakaları eldediler. İnaktif moleküller aktif olanlardan çok daha fazla olduğundan, öğrenme algoritmalarının çoğunluk sınıfını tercih etmemesi için veriyi dengelediler. Ayrıca eğitim ve test kümelerinin farklı çekirdek moleküler iskeletler içermesini sağlayan “iskelet-temelli” bir veri bölme yöntemi kullandılar; bu, modellerin gerçekten yeni bileşiklerle nasıl başa çıkacağını daha gerçekçi biçimde gösterir.
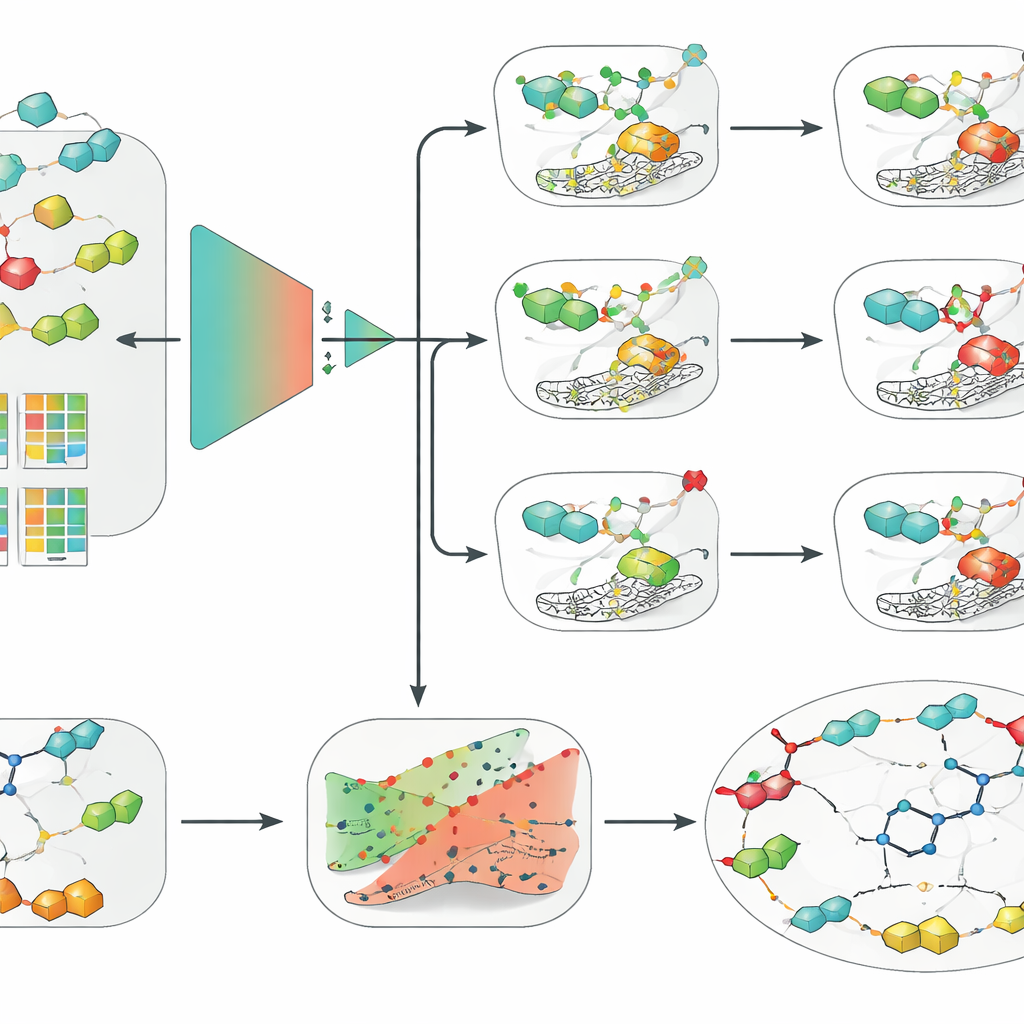
Veri sınırlı olduğunda basit modeller derin öğrenmeyi yener
Bu dikkatle küratelenmiş veri kümesiyle ekip, lojistik regresyon, rastgele ormanlar ve destek vektör makineleri (SVM) gibi klasik makine öğrenmesi yöntemlerinden moleküler yapılara doğrudan çalışan grafik tabanlı modelleri içeren modern derin sinir ağlarına kadar geniş bir yelpazeyi karşılaştırdı. Bunları geleneksel el yapımı tanımlayıcılar, anahtar-tabanlı parmak izleri ve kimyasal dil modelinden öğrenilmiş gömme temsilleri gibi çeşitli molekül kodlama yöntemleriyle eşleştirdiler. Tüm üç enzim izoformu ve daha katı iskelet-temelli değerlendirme altında bir kombinasyon tutarlı şekilde öne çıktı: genişletilmiş-bağlantı parmak izleriyle beslenen bir SVM; bu, bir molekül içindeki yerel kimyasal çevreleri yapılandırılmış biçimde tanımlayan bir yaklaşımdır. Şaşırtıcı şekilde, bu nispeten basit düzenek daha moda olan grafik ve derin öğrenme modellerinden daha iyi performans gösterdi; bu da veri kalitesinin, dikkatli doğrulamanın ve iyi moleküler tanımlayıcıların, veri kümeleri mütevazı büyüklükteyken algoritmik karmaşıklıktan daha önemli olabileceğini vurguluyor.
Güvenilir güven aralığı ve insan dostu açıklamalar eklemek
Araştırmacılar daha sonra en iyi SVM modellerini gerçek ilaç keşfinde kullanılabilir hale getirmek için iki ek katmanla sardılar. İlk olarak, tek bir evet-hayır cevabı vermek yerine olası sonuçlar bölgesi ve garanti edilen bir hata oranı sağlayan konformal öngörü çerçevesini uyguladılar. Bu, bilim insanlarının modelin ne kadar temkinli olmasını istediklerini ayarlamalarına ve modelin gerçekten belirsiz olduğu durumları tanımasına olanak veriyor. İkincisi, modelin gerekçesini daha sezgisel hale getirmek için karşıgerçekçi açıklamalar kullandılar. Belirli bir molekül için, tahmin edilen sonucu aktiften inaktive (veya tersi) çevirecek yakın ilişkili analoglar ürettiler. Klinik aday SLC-0111 için bu çiftleri incelediklerinde — IX ve XII’yi seçici olarak bloke edip II'yi değil — yöntem bağımsız olarak önemli bir medikal kimya içgörüsünü yeniden keşfetti: molekülün “kuyruk” kısmındaki küçük değişiklikler, hangi izoforma bağlanmayı tercih ettiğini güçlü şekilde değiştirir.
Algoritmalardan pratik ilaç tasarım araçlarına
Yaklaşımlarını erişilebilir kılmak için yazarlar üç SVM modelini, belirsizlik katmanını ve karşıgerçekçi motoru CAInsight adlı grafiksel bir araca paketlediler. Bir kullanıcı bir molekülün metin temsilini sağlayabilir ve tek bir tıklamayla hCA II, IX ve XII’ye karşı tahmini aktiviteyi, her tahminin ne kadar güvenilir olduğuna dair bir tahmini ve aktiviteyi artırabilecek veya azaltabilecek yapısal düzeltme önerilerini elde edebilir. Modeller tek adımda kesin güç veya seçicilik tahmin etmek yerine molekülleri aktif veya inaktif olarak sınıflandırmaya odaklansa da, gerçek ilaç adayları için bilinen davranışları yeniden üretiyor ve ince yapısal değişiklikleri ayırt edebiliyorlar. Yazarlar, daha büyük ve daha tutarlı veri kümeleri ile aktivite eşiklerinin nasıl seçildiğine dair daha derin bir analizin performansı daha da iyileştirebileceğini belirtiyorlar.
Geleceğin kanser ilaçları için bunun anlamı
Düz bir ifadeyle bu çalışma, dikkatle inşa edilmiş ve iyi açıklanmış makine öğrenmesi modellerinin, kimyagerlerin benzer görünen enzim hedeflerini daha iyi ayırt eden kanser ilaçları tasarlamasına yardımcı olabileceğini gösteriyor. Sağlam istatistikleri, belirsizlik tahminlerini ve sezgisel “ya şöyle olsaydı” örneklerini birleştirerek çerçeve yalnızca hangi moleküllerin muhtemelen işe yarayacağını tahmin etmekle kalmıyor, aynı zamanda nedenini de öneriyor. Bu tür şeffaf yapay zeka sanal taramayı hızlandırabilir, yeni bileşiklerin üretken tasarımını destekleyebilir ve laboratuvardaki deneme-yanılma yükünü azaltarak nihayetinde hastalar için daha seçici ve daha güvenli tedavilerin keşfine katkıda bulunabilir.
Atıf: Ghamsary, M.S., Rayka, M. & Naghavi, S.S. Interpretable machine learning rationalizes carbonic anhydrase inhibition via conformal and counterfactual prediction. Sci Rep 16, 8419 (2026). https://doi.org/10.1038/s41598-026-39771-2
Anahtar kelimeler: karbonik anhidraz inhibitörleri, yorumlanabilir makine öğrenmesi, ilaç seçiciliği, konformal öngörü, karşıgerçekçi açıklamalar