Clear Sky Science · tr
Sadece 2D bir kodlayıcı kullanarak veri açısından verimli bir 3B tıbbi görsel-dil modeli
3B Taramalardan Daha Akıllı Yardım
Hekimler BT veya MRG taramalarını okurken tek tek görüntülere bakmazlar—yüzlerce dilimi zihinsel olarak bir araya getirip üç boyutlu bir anlayış oluştururlar. Bilgisayarları da aynı şekilde eğitmek, daha hızlı, daha tutarlı tanılar ve hastalar için daha açıklayıcı raporlar sağlama desteği sunabilir. Ancak 3B taramalarla uğraşan mevcut yapay zekâ sistemleri son derece "veri aç"tır; birçok hastanenin sahip olmadığı büyük, özenle etiketlenmiş veri kümelerine ihtiyaç duyarlar. Bu makale, mevcut 2D görüntü teknolojisinden 3B düzeyinde anlayış elde etmenin bir yolunu sunuyor; daha kolay ve daha ucuz inşa edilip dağıtılabilecek güçlü araçlar vaat ediyor.
3B Taramaların Yapay Zekâ İçin Neden Zor Olduğu
Günümüz "görsel–dil" sistemleri zaten 2D tıbbi bir görüntüye bakıp soru yanıtlayabiliyor veya düz bir dilde rapor taslağı oluşturabiliyor. Bu yeteneği 3B hacimlere genişletmek, yapay zekânın tam organlar ve yalnızca birçok dilim birlikte görüldüğünde ortaya çıkan ince lezyonlar hakkında muhakeme yapmasını sağlayacaktır. Sorun şu ki, çoğu mevcut 3B sistem özel 3B görüntü kodlayıcılarına dayanıyor ve bunlar sıfırdan büyük miktarda etiketli tarama koleksiyonları üzerinde eğitiliyor. Böyle veri kümeleri nadirdir, anotasyonları pahalıdır ve genellikle iyi finanse edilen merkezlerle sınırlıdır; bu da kimlerin faydalanabileceğini kısıtlar. Aynı zamanda, her dilimi ayrı bir 2D görüntü gibi ele almak dilimler arasındaki doğal sürekliliği yok sayar ve modeli tekrarlayan bilgilerle boğar.
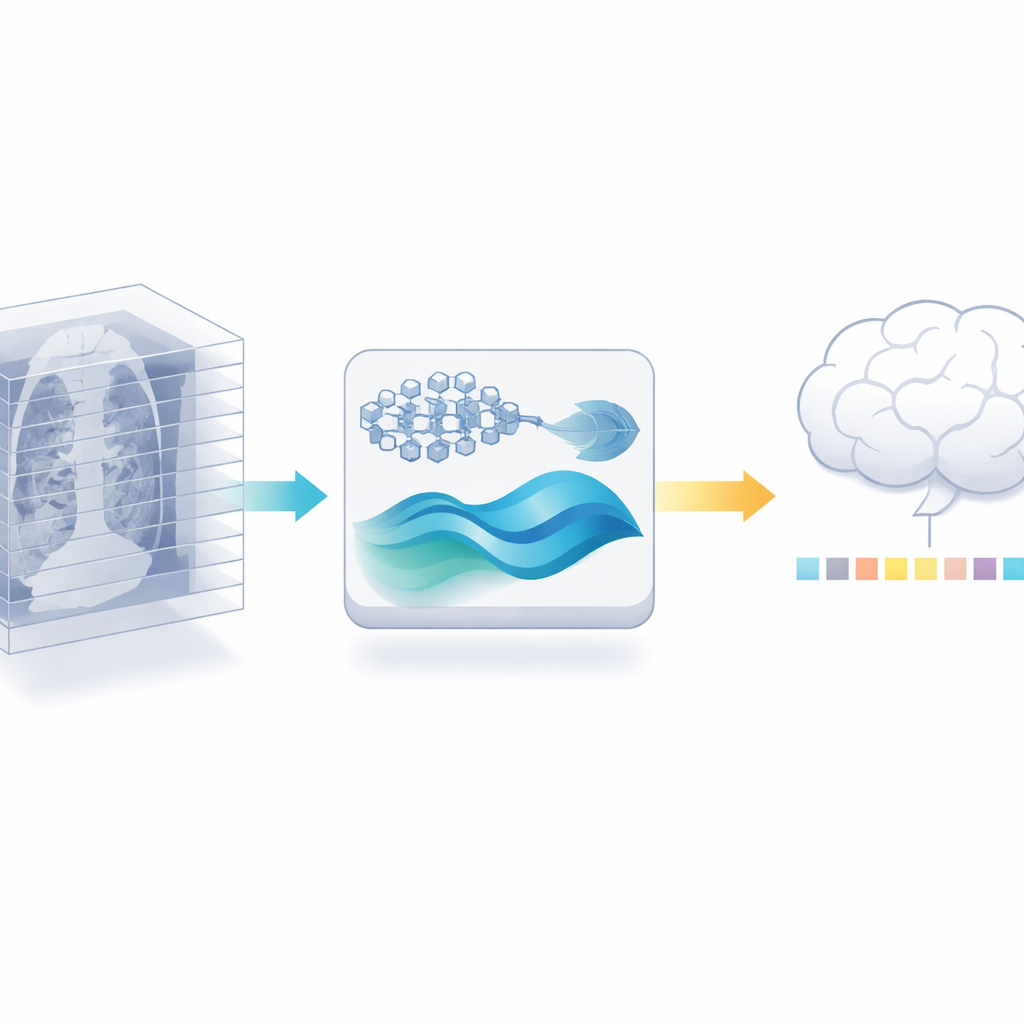
3B İş İçin 2D Bir Uzmanı Yeniden Kullanmak
Yazarlar farklı bir yol öneriyor: yeni bir 3B kodlayıcı eğitmek yerine, tıbbi literatürde milyonlarca etiketli görüntü üzerinde zaten eğitilmiş güçlü bir 2D tıbbi görüntü modelini yeniden kullanıyorlar. Önce her 3B taramayı bireysel dilimlerine ayırıyor ve bu 2D modelin her dilimden ayrıntılı özellikler çıkarmasına izin veriyorlar. Sonra dikkatli biçimde fazlalığı buduyorlar: bir taramadaki bitişik dilimler genellikle neredeyse aynı göründüğünden, bir benzerlik kontrolü birçok yakınduplicate'ı atabilirken en bilgilendirici görünüşleri koruyabiliyor. Bu adım tek başına, sonraki aşamaların işlemesi gereken veri miktarını daha fazla etiketlenmiş tarama talep etmeden azaltıyor.
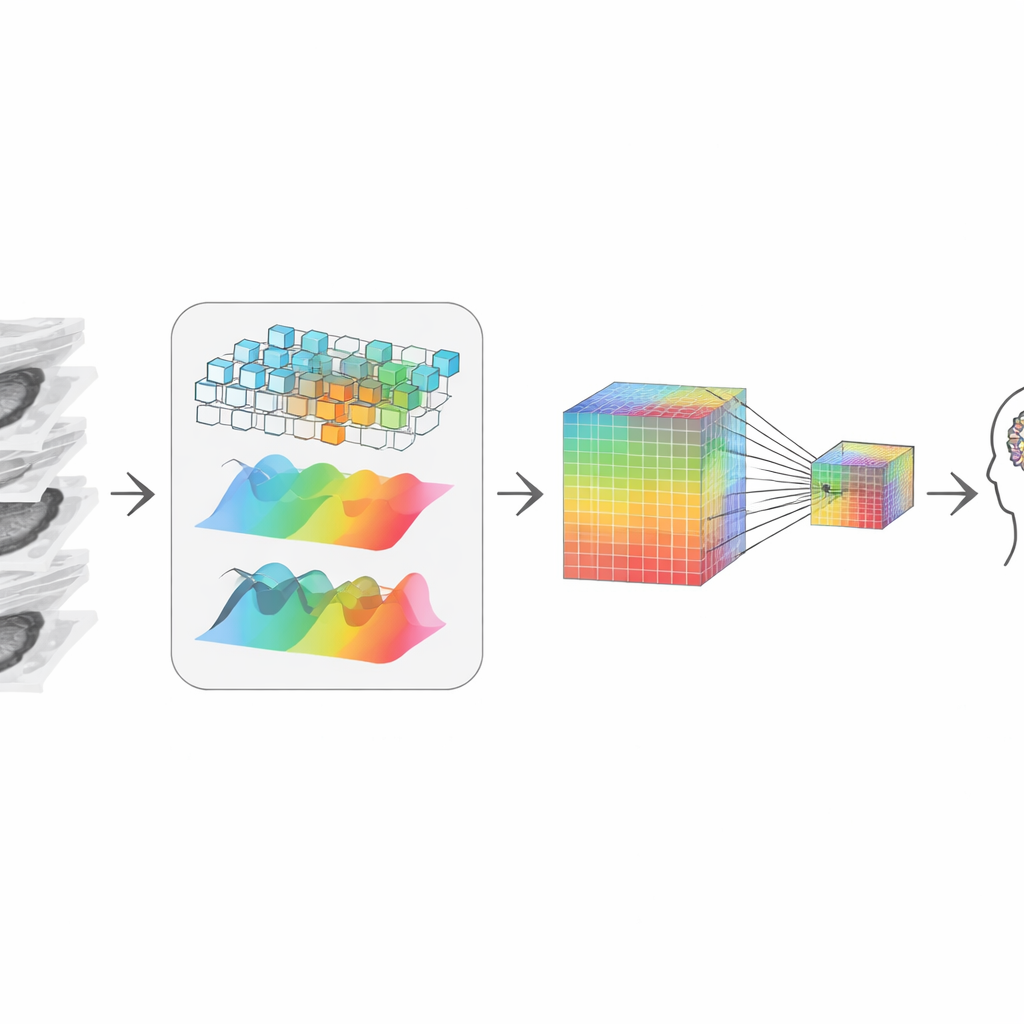
Parçalardan 3B Hikâyeyi Yeniden Kurmak
Budadıktan sonra sistem kalan dilimleri tutarlı bir 3B görüntüye "yeniden diker". Yazarlar bunu verinin iki tamamlayıcı görünümünü birleştirerek yapıyorlar. Bir yol, hacim boyunca hareket eden bir büyüteç gibi yerel şekillere ve kenarlara bakıyor; keskin sınırlar ve dokulara duyarlı. Diğer yol ise veriyi frekans görünümüne dönüştürüyor; bu, dilimler arasındaki geniş desenleri ve uzun menzilli yapıyı—örneğin bir tümörün nasıl yayıldığını veya bir organın genel şekil özelliklerini—daha iyi yakalıyor. Uyarlanabilir bir birleştirme adımı, her noktada hangi görüşe ne kadar güvenileceğini öğrenerek hem ince ayrıntılara hem de küresel bağlama saygı gösteren bir temsil üretiyor; tüm bunlar 2D dilimlerden başlanmasına rağmen mümkün oluyor.
Sıkıştırırken Küçük İpuçlarını Korumak
Büyük bir dil modeliyle—soru yanıtlayan ve rapor yazan bölüm—ile iletişim kurmak için görsel bilgi makul sayıda belirtece, yani "görsel kelimeye" sıkıştırılmalıdır. Basit bir küçültme küçük ama kritik sinyalleri bulanıklaştırır; örneğin tanıda önemli olan küçük kalsifikasyonlar veya ince doku değişiklikleri kaybolabilir. Bunu önlemek için yazarlar iki kanallı bir temsil oluşturuyor: biri ayrıntıyla zengin yüksek çözünürlüklü bir versiyon tutuyor, diğeri ise daha küçük, daha ucuz bir versiyon. Bir dikkat mekanizması, küçük versiyondaki her noktanın seçici olarak büyük versiyona "geri bakmasına" ve en keskin ayrıntıları çekmesine izin veriyor. Sonuç, yine de radyologun önem vereceği ipuçlarını taşıyan kompakt bir görsel özet oluyor ve ardından muhakeme için dil modeline gönderiliyor.
Gerçek Tıbbi Görevlerde Kanıt
Tasarımı test etmek için araştırmacılar, iki ana soruyu soran halka açık 3B kıyaslama setlerinde değerlendirdiler: sistem 3B taramaların radyoloji tarzı doğru betimlemelerini yazabiliyor mu ve içlerinde görünenler hakkında soruları yanıtlayabiliyor mu? Yaklaşım, hiçbir zaman 3B-özgü bir kodlayıcı eğitmemiş olmasına rağmen, her iki görevde de birkaç güçlü 3B tabanlı modeli geride bıraktı. Daha doğru, klinik olarak zengin raporlar üretti ve tam olarak hangi organın, anormalliğin veya konumun dahil olduğuna dair zor sorular da dahil olmak üzere soruları daha doğru yanıtladı. Ayrıca daha hızlı çalıştı, çok daha az 3B eğitim verisi gerektirdi ve MRG ile PET gibi farklı tarama türlerine iyi genelleşti.
Gelecek Bakımı İçin Anlamı
Günlük ifadeyle, bu çalışma veri aç 3B modelleri sıfırdan başlatmadan hacimsel taramalarda yüksek kaliteli yapay zekâ desteği almanın mümkün olduğunu gösteriyor. Güçlü bir 2D uzmanı akıllıca yeniden kullanarak, bilgilendirici dilimleri dikkatle seçerek ve küçük ayrıntıları koruyarak 3B görüntüyü yeniden kurarak, yazarlar çok daha az veri ve hesaplama ile son teknoloji performans elde ediyorlar. Yaygın biçimde benimsenirse, bu tür bir yaklaşım gelişmiş yapay zekâ yardımını—daha iyi raporlar, daha net açıklamalar ve daha güvenilir triyaj gibi—büyük veri kaynaklarından yoksun hastane ve kliniklere sunabilir ve sofistike görüntüleme analizini rutin klinik uygulamaya daha yakın hale getirebilir.
Atıf: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Anahtar kelimeler: 3B tıbbi görüntüleme, görsel-dil modelleri, radyoloji yapay zekâsı, veri açısından verimli öğrenme, BT ve MRG analizi