Clear Sky Science · tr
CGDFNet: bağlam tarafından yönlendirilen ayrıntı birleştirmesiyle çift kollu gerçek zamanlı semantik segmentasyon ağı
Arabaları Tüm Sokağı Görmeye Öğretmek
Günümüz arabaları ve robotları etraflarındaki dünyayı anlamak için giderek daha fazla kameraya dayanıyor—yolları, kaldırımları, insanları, araçları ve işaretleri gerçek zamanlı olarak tespit etmek gibi. Bu makale, özellikle yoğun kent sokaklarında bu tür “sahne anlama” görevlerini daha hızlı ve daha doğru gerçekleştirmek üzere tasarlanmış yeni bir bilgisayarlı görü sistemi olan CGDFNet’i sunuyor. İnce ayrıntıları (trafik lambası direkleri veya bisiklet tekerlekleri gibi) ve büyük ölçekli düzeni (yollar ve binalar gibi) aynı anda korumayı öğrenerek, CGDFNet otomatik sürüş ve diğer gerçek zamanlı görme görevlerini daha güvenli ve daha güvenilir hale getirmeyi amaçlıyor.
Piksel Düzeyinde Görmenin Neden Bu Kadar Talepkar Olduğu
Semantik segmentasyonda, bir bilgisayar bir görüntüdeki her bir piksele bir kategori atar: yol, araba, yaya, gökyüzü vb. Bu, bir arabanın etrafına kutu çizmekten çok daha zordur çünkü sistemin nesne sınırlarını ve küçük şekilleri yüksek hassasiyetle izlemesi gerekir. Birçok yüksek doğruluklu yöntem mevcut, ancak bunlar genellikle yavaş ve yüksek güç tüketimine sahiptir; bu da arabalarda, dronlarda veya giyilebilir cihazlarda gerçek zamanlı sistemler için uygun değildir. Öte yandan, hızlı çalışan hafif yöntemler genellikle ayrıntılardan ödün verir veya daha geniş sahneyi kaybeder; küçük nesneler, ince yapılar veya kalabalık kentsel ortamlarla başa çıkmakta zorlanırlar.
İki Yol: Biri Ayrıntı, Biri Bağlam İçin
CGDFNet bu gerilimi çift kollu bir tasarımla çözüyor: bir kol keskin ayrıntılara odaklanırken, diğeri geniş bağlamı yakalar. Verimli bir omurga ağ üzerine kurulan sistemde, daha alt katmanlar kenarları ve dokuları korumak için daha yüksek çözünürlük tutan “ayrıntı kolu”na beslenir. Daha derin katmanlar ise sahneyi daha sıkıştırılmış bir biçimde gören ve genel yapı ile nesneler arasındaki ilişkileri anlamada iyi olan “bağlam kolu”na gider. Önceki iki kollu tasarımların büyük ölçüde bu akışları ayrı tutup sonra kaba biçimde birleştirmesinin aksine, CGDFNet bu akımların işlem boyunca birbirleriyle iletişim kurmasını teşvik eder; böylece ince ayrıntılar ağın sahne hakkındaki genel bilgisi ile sürekli karşılaştırılır.
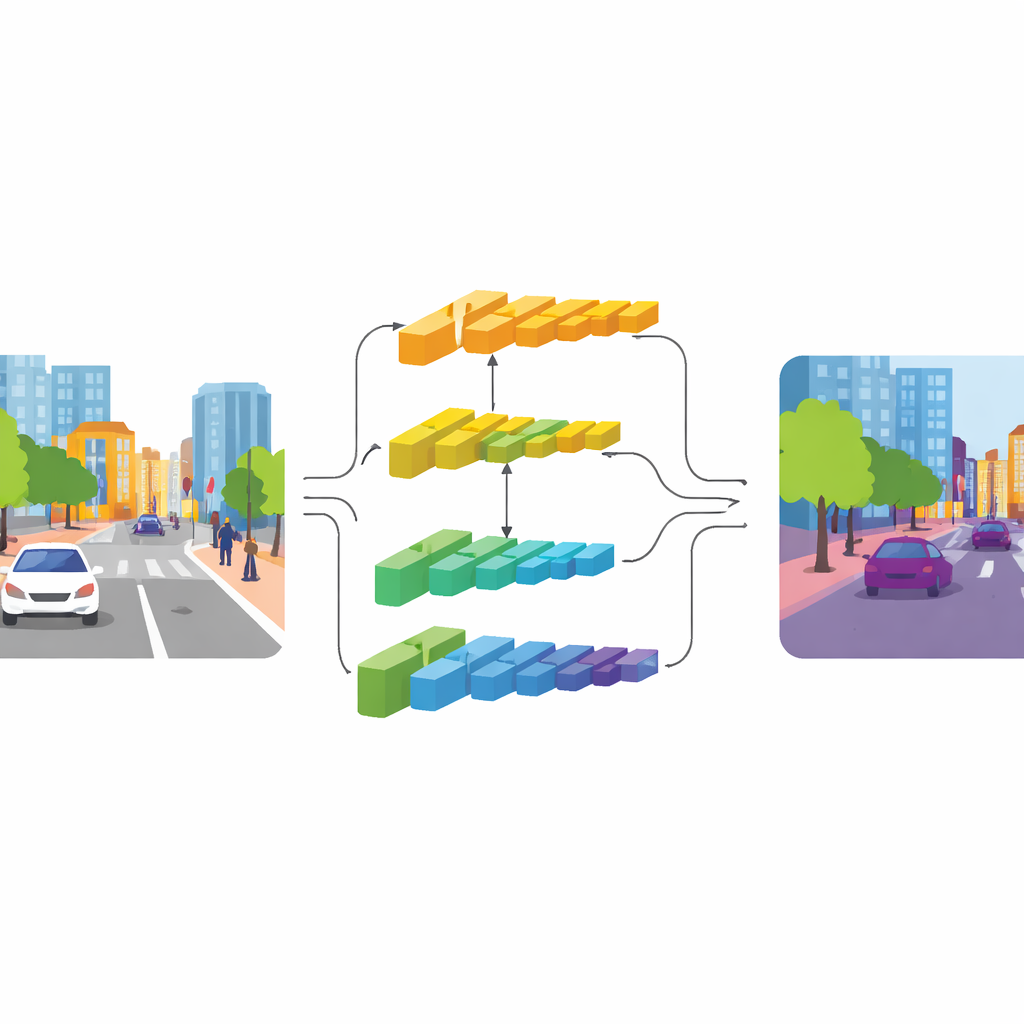
Ayrıntıları Anlamla Yönlendirmek
Bu etkileşimi güçlendiren iki ana bileşen vardır. Bağlam kolunda, Semantik İyileştirme Modülü özellik haritalarında en bilgi verici bölgeleri ve kanalları vurgulamayı öğrenir. Bunu, yerel ipuçlarını (sahnede hangi kısımların birbirine yakın olarak aktif olduğu) küresel ipuçlarıyla (ağın tüm görüntüde ne gördüğü) birleştirerek yapar; böylece temsil hem komşuluk ayrıntısını hem de sahne düzeyinde anlamı taşır. Ayrıntı kolunda ise Bağlam‑Yönlendirmeli Ayrıntı Modülü bu semantik bilgiyi otobüsün sınırı veya bir bisikletin gövdesi gibi önemli kenarlara ve ince yapılara dikkat çekmek için kullanır. Bu modül, komşu pikseller arasındaki değişimlere daha duyarlı olan özel bir tür konvolüsyona dayanır; bu da çok fazla ek parametre eklemeden konturları ve küçük nesneleri doğal olarak vurgular.
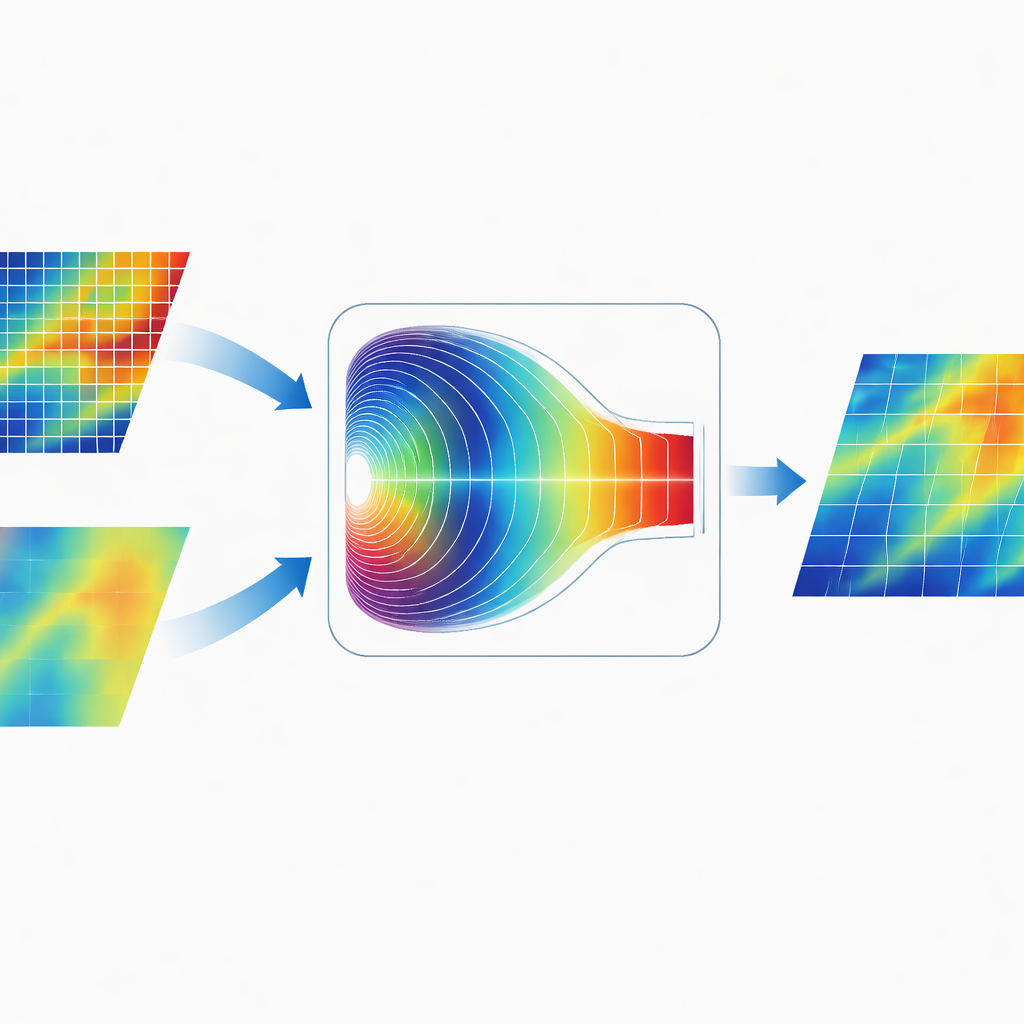
Bilgiyi Frekans Dünyasında Karıştırmak
CGDFNet’in ayırt edici özelliklerinden biri iki kolu nasıl birleştirdiğidir. Haritalarını görüntü alanında basitçe toplamak yerine, yazarlar Fourier‑Düzlemi Uyarlanabilir Birleştirme Modülü tasarlar. Bu modül, birleşik özellikleri geçici olarak frekans alanına dönüştürür; burada desenler yavaş, geniş varyasyonlar ve hızlı, keskin değişimler açısından temsil edilir. Ardından uyarlanabilir bir kapı mekanizması hangi frekans bileşenlerinin ayrıntı kolundan, hangilerinin bağlam kolundan vurgulanacağını öğrenir. Bu ağırlıklandırmadan sonra özellikler geri dönüştürülür ve bu, yalnızca uzaysal birleştirmeye göre keskin kenarları uyumlu küresel yapıyla daha etkili bir şekilde birleştiren bir temsil verir.
Gerçek Sokaklardaki Sonuçlar
Araştırma ekibi CGDFNet’i kentsel sürüş sahneleri için yaygın olarak kullanılan iki ölçüt üzerinde test etti: Avrupa şehirlerinden toplanmış Cityscapes ve Birleşik Krallık’tan sürücü perspektifiyle kaydedilmiş CamVid. CGDFNet büyük görüntüleri gerçek zamanlı hızlarda işledi—Cityscapes’te yaklaşık 88 kare/saniye ve CamVid’de yaklaşık 129 kare/saniye—aynı zamanda birçok son teknoloji sistemiyle rekabet eden veya onları aşan segmentasyon doğruluğu elde etti. Özellikle tel örgüler, trafik işaretleri, otobüsler ve bisikletler gibi genellikle segmentasyonda zor olunan kategorilerde iyi performans gösterdi; bu tür kategorilerde hassas sınırların ve küçük yapıların korunması kritik öneme sahiptir.
Günlük Teknoloji İçin Anlamı
Uygulama açısından CGDFNet, gerçek zamanlı kullanım için yeterince hızlı ve karmaşık kentsel sahnelerde küçük, güvenlikle ilgili ayrıntılara saygı gösterecek kadar titiz görme sistemleri oluşturmanın mümkün olduğunu gösteriyor. Ayrıntıya odaklanan bir kolu, bağlama odaklanan bir kolu ve frekans alanında akıllı bir birleştirme adımını birleştirerek ağ sokağın dengeli bir görünümünü korur: her şeyin nerede olduğunu ve her nesnenin nerede başladığını ve bittiğini bilir. Yoğun kalabalıklar veya kötü hava koşulları gibi zorluklar devam etse de, yaklaşım sürücü olmayan araçlardan akıllı trafik kameralarına ve yardımcı robotlara kadar gelecekteki cihaz içi görme için umut verici bir plan sunuyor.
Atıf: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Anahtar kelimeler: gerçek zamanlı semantik segmentasyon, otonom sürüş görmesi, çift kollu sinir ağı, Fourier tabanlı özellik birleştirme, kentsel sahne anlama