Clear Sky Science · tr
İskelet hareket topolojisi maskelenmiş tahmini ve karşıt öğrenme ile kendi kendine denetimli insan eylemi tanıma
Bilgisayarlara Beden Dilini Okutmak
Video kapı zilleri ile akıllı rehabilitasyon araçlarına kadar birçok modern sistem, insanların ne yaptığını yalnızca nasıl hareket ettiklerine bakarak anlamak zorunda. Ancak bilgisayarları insan hareketlerini tanımaya eğitmek genellikle her el sallama, tekme veya el sıkışma gibi hareketlerin elle etiketlendiği büyük, özenle hazırlanmış veri setleri gerektirir. Bu çalışma, makinelerin yalnızca ham hareket verilerinden—sadece vücudun hareket eden iskeletinden—etiketsiz şekilde öğrenmesini sağlayan bir yöntem sunuyor: etiket yok, yüz yok, tam renkli video yok; böylece eylem tanıma daha doğru, daha özel ve insan etiketlemesine çok daha az bağımlı hale geliyor.
Neden İskeletler Yeterli?
Tam video karelerini analiz etmek yerine yöntem, omuzlar, dirsekler, kalçalar ve dizler gibi kilit eklemlerin zaman içindeki koordinatları olan 3B iskelet verisiyle çalışıyor. Vücudun bu yalın görünümü birkaç avantaja sahip. Yüzler ve giysiler kaldırıldığından gizlilik endişelerinin büyük kısmını bertaraf ediyor ve uzun kayıtlar için bile verinin verimli işlenmesini sağlayacak kadar kompakt. İskeletler ayrıca karışık arka planlar ve aydınlatma değişimleri gibi normal video tabanlı sistemleri yanıltabilen koşullara karşı dayanıklı. Ancak mevcut iskelet tabanlı yaklaşımların çoğu hâlâ etiketli örneklere güçlü biçimde dayanıyor ve eklemlerin karmaşık, koordineli hareketlerini tam olarak yakalamakta zorlanıyor.
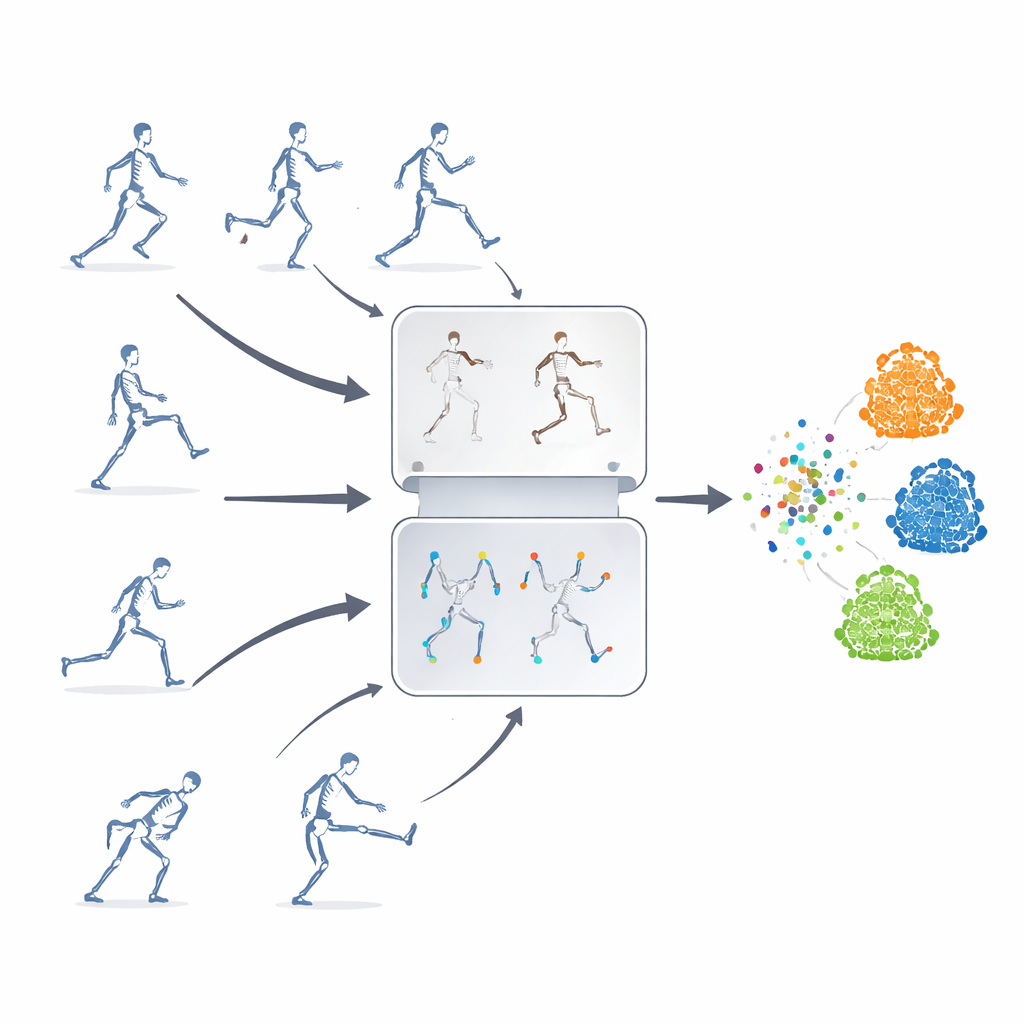
Etiketsiz Öğrenme
Yazarlar kendi kendine denetimli bir öğrenme çerçevesi öneriyor; yani sistem etiketsiz iskelet dizilerinden kendi kendine öğreniyor. Temel fikirleri genellikle ayrı kullanılan iki güçlü stratejiyi birleştirmek. Birincisi “maskelenmiş tahmin”—iskelet verisinin parçaları kasıtlı olarak gizlenir ve model geri kalan bağlamdan eksik hareketi tahmin etmek zorunda kalır. Diğeri “karşıt öğrenme”—modele aynı eylemin birden çok değiştirilmiş versiyonları gösterilir ve bunların hepsinin aynı temel hareketi temsil ettiğini fark etmesi öğretilir. Bu yaklaşımları harmanlayarak sistem hem eklem hareketlerinin ince ayrıntılarını hem de bir eylemin büyük resmi anlamını öğrenir.
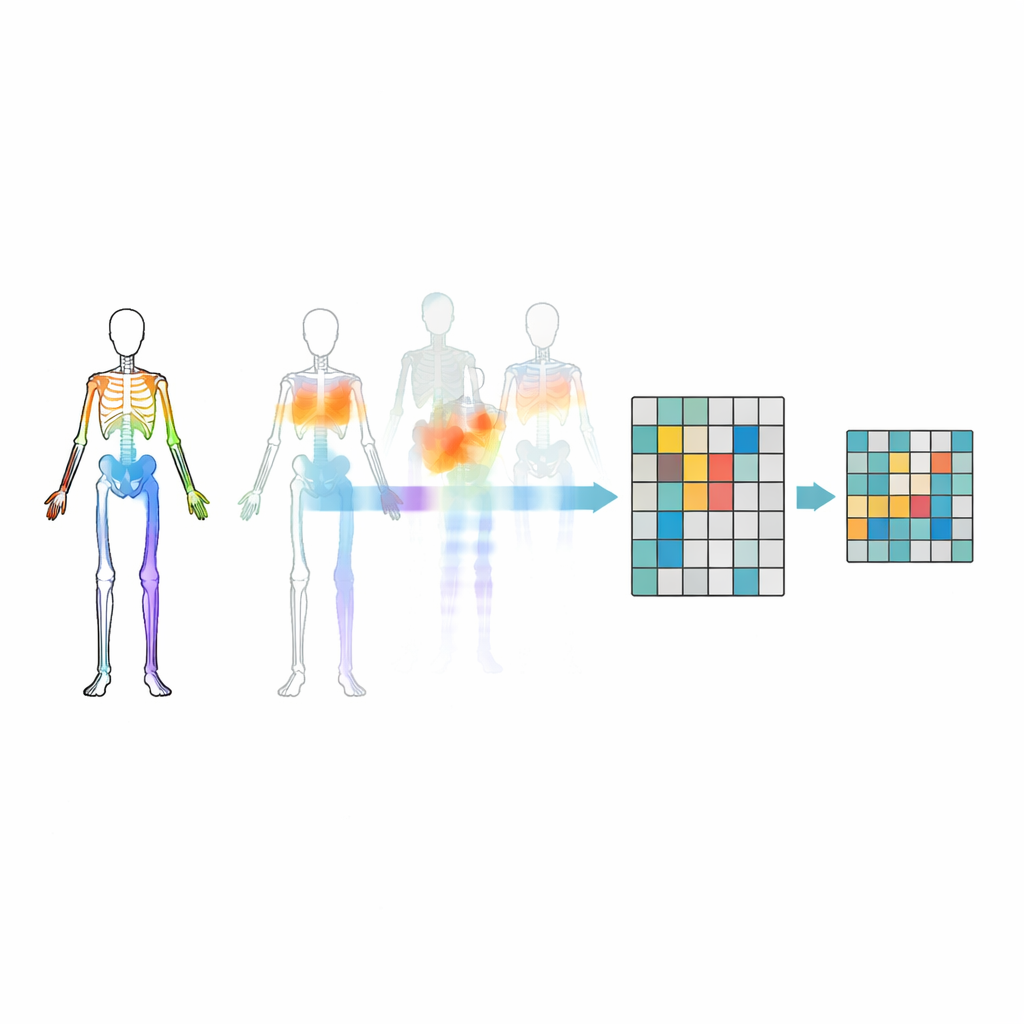
Doğru Eklemleri Gizlemek
Rastgele eklemleri maskelenmesi tek başına yeterli değil—model vücut parçaları arasındaki önemli ilişkileri göz ardı edebilir veya en belirgin harekete takılıp kalabilir. Bunu önlemek için araştırmacılar hareket–topoloji maskelenmesi stratejisi geliştirdiler. Eklemleri kollar, bacaklar ve gövde gibi anlamlı vücut bölgelerine grupluyor, sonra her bölgenin zaman içinde ne kadar güçlü hareket ettiğini ölçüyorlar. Maskelenme kararları hem vücudun yapısı hem de her bölgenin hareketliliği tarafından yönlendiriliyor; böylece bazen çok aktif parçalar gizleniyor ve model bunları vücudun geri kalanından çıkarmak zorunda kalıyor. Bu hedefli gizleme, sistemin birkaç gösterişli hareketi ezberlemek yerine eylemler sırasında eklemlerin nasıl iş birliği yaptığını öğrenmesine yardımcı oluyor.
Eylemleri Birçok Yoldan Uzatmak
Karşıt öğrenme kısmını eğitmek için aynı orijinal iskelet dizisi birçok farklı “görünüşe” dönüştürülüyor. Bazı değişiklikler nazikçe—zaman penceresini kırpma veya yörüngeyi hafifçe çarpıtma gibi—yapılırken, diğerleri daha aşırı; ters çevirme, döndürme ve daha güçlü gürültü ekleme gibi. Bu çok katmanlı güçlendirmeler (augmentation) modelin çok çeşitli hareket desenlerine maruz kalmasını sağlar ve onu bir eylemin temel yapısına odaklanmaya teşvik eder; yüzeysel detaylara değil. Aynı zamanda bir yörünge yönlendirmeli özellik düşürme modülü modelin en çok güvenilen hareket özelliklerini izler ve eğitim sırasında kasıtlı olarak bunları bastırır. Modelin en sevdiği ipuçları geçici olarak kaldırılarak, alternatif ipuçlarını keşfetmesi ve daha genel, aktarılabilir temsiller öğrenmesi sağlanır.
Ne Kadar İyi Çalışıyor?
Çerçeve, günlük davranışları, tıbbi ilişkili hareketleri ve insanlar arası etkileşimleri kapsayan üç büyük açık 3B insan eylemi benchmark’ı üzerinde test edildi. Yalnızca iskelet eklem verisini ve nispeten hafif bir tekrarlayan sinir ağını kullanmasına rağmen, yöntem daha karmaşık girdilere veya mimarilere dayanan birçok son teknoloji sistemi yakalıyor veya aşıyor. Özellikle etiketin kısıtlı olduğu veya bazı vücut parçalarının örtüldüğü durumlarda güçlü performans gösteriyor; bu tür koşullar gerçek dünya ortamlarında yaygındır. Çok farklı veri setleri arasında bilgi aktarımı konusunda hâlâ gelişme alanı olsa da, yaklaşım eylem tanıma için etiketli ve etiketsiz eğitim arasındaki farkı önemli ölçüde daraltıyor.
Gerçek Dünya Sistemleri İçin Anlamı
Bir uzman olmayan için sonuç şu: bu çalışma, bilgisayarların her hareketin ne anlama geldiğini açıkça söylemeden insan beden dilini çok daha iyi okumayı nasıl öğrenebileceğini gösteriyor. İskelet verisini eğitme sırasında akıllıca gizleyip çarpıtarak, model kötü aydınlatma, görsel karışıklık veya eksik eklemler altında bile dayanıklı hareket kalıpları öğreniyor ve bunu çok daha az insan etiketine ihtiyaç duyarak yapıyor. Bu da ev izleme ve spor koçluğundan tıbbi rehabilitasyona ve insan–robot etkileşimine kadar uygulamalar için daha özel, ölçeklenebilir ve uyarlanabilir eylem tanıma sistemlerinin yolunu açıyor.
Atıf: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Anahtar kelimeler: insan eylemi tanıma, 3B iskelet verisi, kendi kendine denetimli öğrenme, karşıt öğrenme, hareket analizi