Clear Sky Science · tr
Kamera tabanlı kişi yeniden tanımlama için çok seviyeli birleştirme ile CNN-RNN İkiz çerçevesi
Kameralar arasında insan takibinin önemi
Modern şehirler kameralarla donatılmış olsa da bu kameralar nadiren birbirleriyle "konuşur." Bir kişi bir sokak köşesinden tren istasyonuna yürürken, farklı kameralar onu yeni açılardan, değişen ışık koşullarında ve çoğu zaman kalabalığın içinden görür. Bir video klipler dizisinde aynı kişinin olup olmadığını otomatik olarak tanımak—video tabanlı kişi yeniden tanımlama olarak adlandırılır—bir olay sonrası hareketleri izlemeye, kayıp kişi aramalarına destek olmaya veya yoğun kamusal alanlarda analizler sağlamaya yardımcı olabilir. Ancak bunu doğru ve verimli şekilde, özellikle sınırlı donanım üzerinde yapmak büyük bir teknik zorluktur.
Hareket halindeki insanları eşleştirmek için daha sade bir beyin
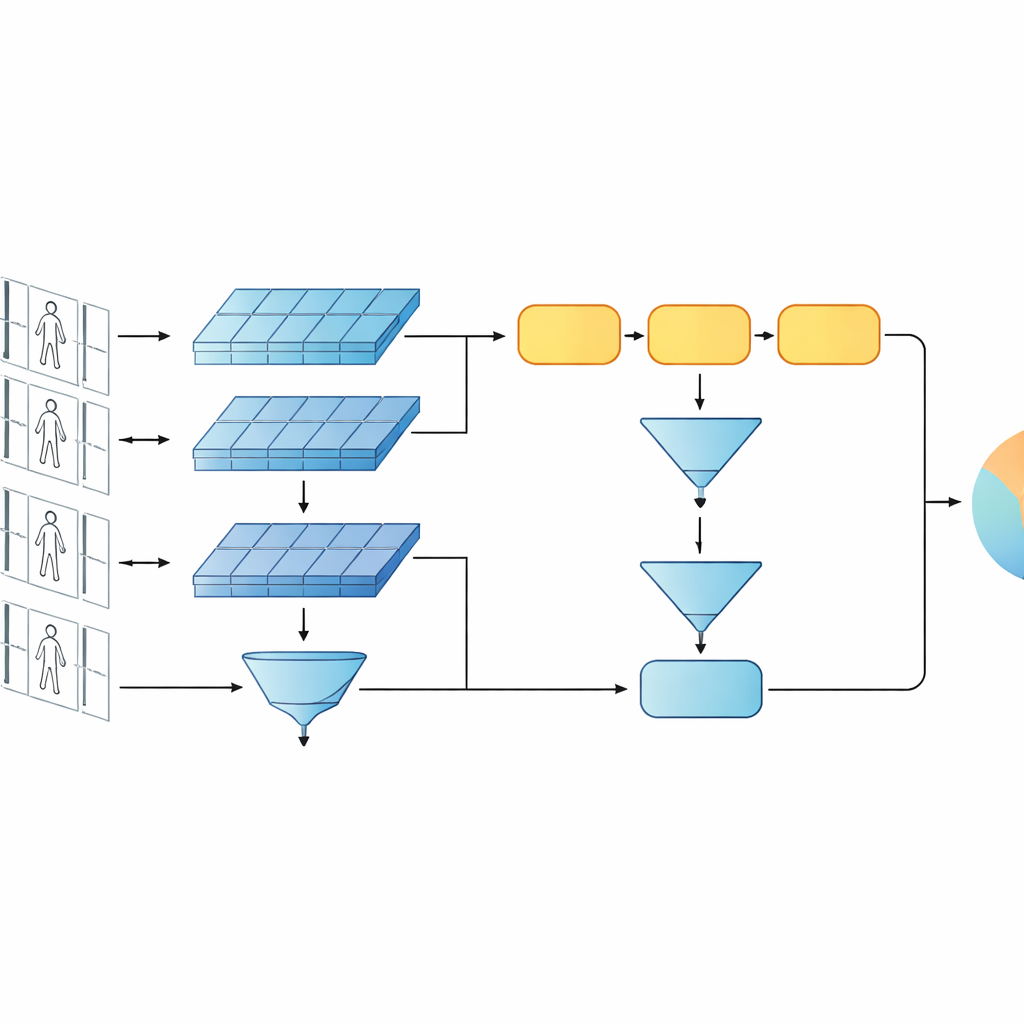
Bu çalışma, iki kısa video klibin aynı kişiyi gösterip göstermediğini söylemek üzere tasarlanmış kompakt bir yapay zeka sistemi sunar. Günün trendi olan çok derin ya da dönüştürücü (transformer) tabanlı ağlar yerine, yazarlar daha sade bir tasarıma dayanır: her video karesini analiz eden bir konvolüsyonel ağ ve görünümün zamana göre nasıl değiştiğini izleyen kapılı yinelemeli birim (GRU). Bu iki dal, iç ayarlarını paylaşan ikiz ağlar şeklinde, Siamese düzeninde yerleştirilir. Her ikiz bir video dizisini işler ve sistem aynı kişiye ait klipler için benzer iç imzalar, farklı kişiler içinse belirgin şekilde farklı imzalar üretmeyi öğrenir.
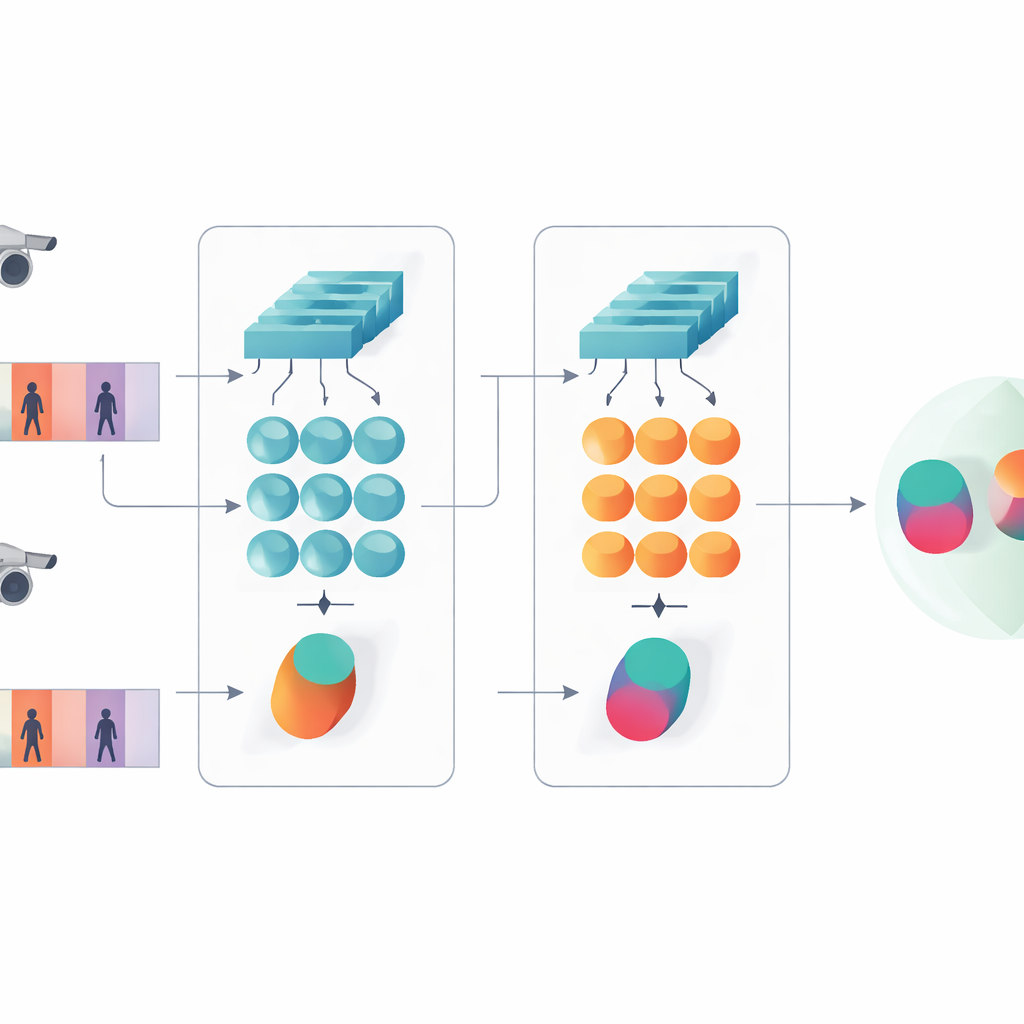
Hem ayrıntıları hem de zaman içindeki örüntüleri görmek
Çalışmanın kilit fikri, tanımanın yalnızca bir ağın en derin, en soyut özelliklerine dayanmaması gerektiğidir. Erken katmanlar hâlâ ceket dokusu, pantolon çizgileri veya sırt çantasının silueti gibi keskin görsel ayrıntılar içerir—kameranın açısındaki değişikliklere sıklıkla dayanabilen ipuçları. Önerilen model bu nedenle iki seviyeli bir tanım tutar. Bir dal, ince dokuları ve yerel desenleri özetlemek için erken katman özelliklerini tüm kareler üzerinde havuzlar. Diğer dal ise daha sonraki özellikleri GRU'ya besler; GRU kare kare diziyi izler ve sonra iç durumlarını zaman üzerinde ortalar. Bu ortalama adımı son birkaç kareyi aşırı vurgulamaktan kaçınır ve bunun yerine kişinin tüm klip boyunca nasıl göründüğüne ve hareket ettiğine dair bir fikir birliği yakalar.
İkiz ağları uzlaşmaya ve sınıflandırmaya eğitmek
Sisteme neyin önemli olduğunu öğretmek için yazarlar iki eğitim hedefini birleştirir. Birincisi, doğrulama (verification) amacı, aynı kişiye ait videolar için ikiz dalların yakın imzalar, farklı kişiler içinse uzak imzalar üretmesini teşvik eder. İkincisi, sınıflandırma amacı ağdan her eğitim klibini belirli bir kimliğe atamasını ister. Her ikisini aynı anda ve hem düşük hem de yüksek özellik seviyelerinde optimize ederek, model yalnızca kişiler arasında ayırt edici değil aynı zamanda gürültüye, örtülmeye ve ara sıra kalitesiz karelere karşı sağlam iç tanımlamalar öğrenir. Tasarım katman ve parametre açısından sığ kalarak nispeten küçük video veri kümelerinde aşırı uyumdan kaçınmasına yardımcı olur.
Gerçek gözetim tarzı videolarda test
Çerçeve, yüzlerce bireyin kısa yürüyüş dizilerini içeren ve ayrı kamera çiftlerinden yakalanmış iki yaygın video benchmark'ı olan PRID-2011 ve iLIDS-VID üzerinde değerlendirilir. Çalışma, GRU yerine diğer yinelemeli birimlerin kullanılması, yinelemeli kaç katmanın olduğu, özelliklerin zaman üzerinde nasıl havuzlandığı ve düşük ya da yüksek seviyeli dalların açılıp kapatılması gibi farklı tasarım seçeneklerini dikkatle araştırır. Bu testlerin genelinde, ortalama havuzlamalı tek katmanlı bir GRU ve tam çok seviyeli düzenlemeyle en iyi doğruluk sürekli olarak elde edilir. Model, daha karmaşık birçok yinelemeli ve Siamese sistemiyle eşleşir veya onları geride bırakır; bazı dikkat (attention) tabanlı tasarımlarla da rekabetçi performans gösterirken çok daha az parametre ve hesaplama kullanır.
Gerçek dünya konuşlandırmaları için verimlilik
Doğruluğun ötesinde, çalışma pratikliğe vurgu yapar. Tüm ağın yalnızca yaklaşık bir ila iki milyon eğitilebilir parametresi vardır—popüler derin residual veya transformer tabanlı gövdelerden kat kat daha az—ve kare başına onların hesaplama maliyetinin bir kısmını gerektirir. Bu, kameraların yakınındaki kenar sunucular gibi sınırlı bellek ve işlem gücüne sahip cihazlara dağıtım için daha uygun hale getirir. Deneyler ayrıca, sistemin her depolanan kişi için daha fazla kare gördüğü daha uzun galeri dizilerinin tanımayı önemli ölçüde iyileştirdiğini, ancak işleme maliyetinde lineer bir artışa yol açtığını gösterir. Yazarlar, bu tür kompakt ve dikkatli tasarlanmış mimarilerin günümüzün en büyük modellerinin ağır faturası olmadan güvenilir kişi yeniden tanımlama sunabileceğini savunur.
Günlük gözetim sistemleri için anlamı
Basitçe söylemek gerekirse, bu makale akıllı tasarımın salt büyüklüğü yenebileceğini gösterir: yüzeysel görüntü analizi, hafif dizi modellemesi ve görsel benzerliğin iki seviyeli görünümünü birleştirerek, modeli küçük ve hızlı tutarken kameralar arasında kimlerin kim olduğunu yüksek güvenilirlikle izlemek mümkündür. Birçok kamerada çalışması gereken, genellikle sıkı donanım ve enerji kısıtları olan geleceğin sistemleri için, bu tür verimli ve çok seviyeli yaklaşım daha yetenekli ve sorumlu video analizlerini gerçek dünyaya taşıyabilir.
Atıf: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Anahtar kelimeler: kişi yeniden tanımlama, video gözetimi, Siamese sinir ağları, zamansel modelleme, verimli derin öğrenme