Clear Sky Science · tr
LLM'lere dayalı dinamik stratejilerle sağlam bir doğal dil metinden SQL üretim çerçevesi
Günlük Soruları Veritabanı Cevaplarına Çevirmek
Modern kuruluşlar veriyle dolup taşıyor, ancak çoğu kişi buna sorgu yapmak için gereken teknik dili konuşamıyor. Bu makale, kullanıcıların düz yazıyla sorular sormasına ve bunları otomatik olarak kesin veritabanı komutlarına dönüştürmesine imkân veren TriSQL adlı bir sistemi tanıtıyor. Büyük dil modellerinin karmaşıklığı nasıl yönettiğini dikkatle düzenleyerek, çerçeve en zor sorularda bile veri erişimini hem daha doğru hem de daha güvenilir hale getirmeyi amaçlıyor.
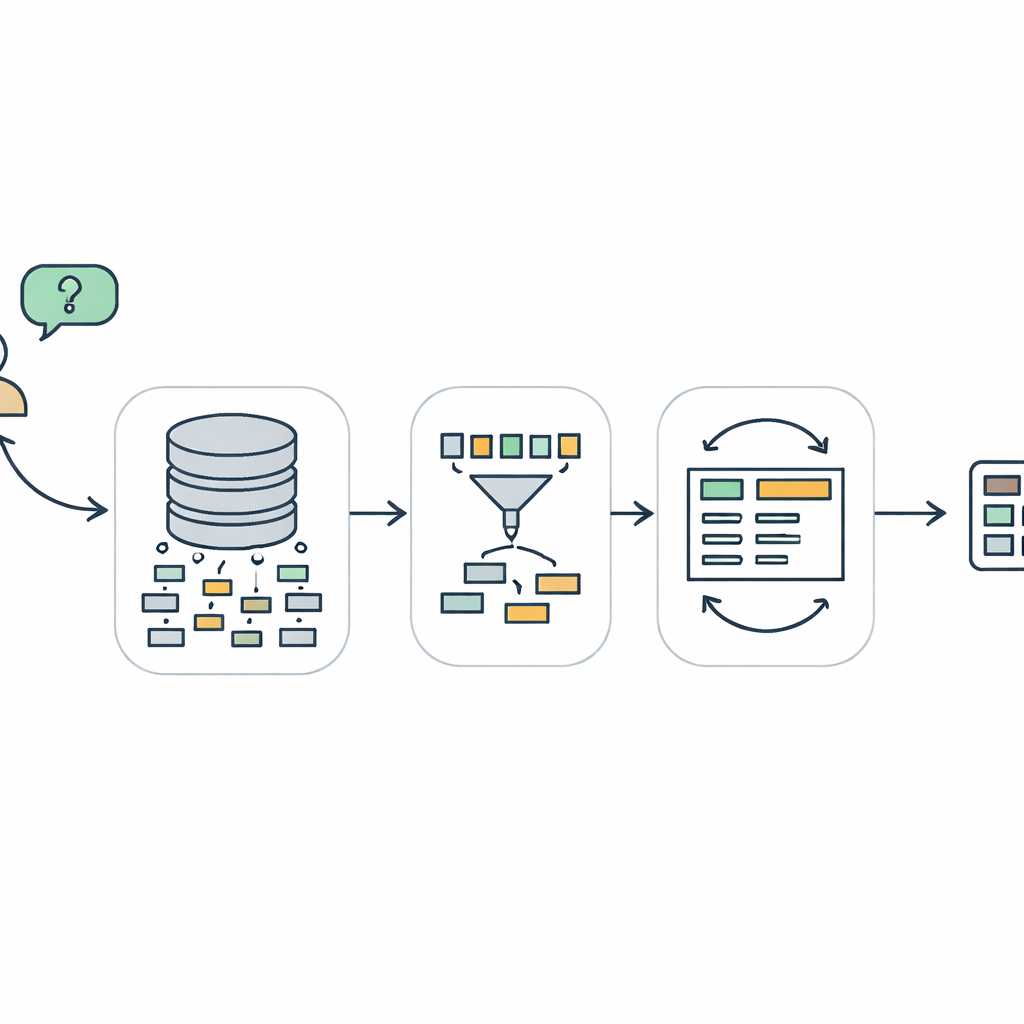
Veritabanlarıyla Konuşmanın Neden Bu Kadar Zor Olduğu
Birisi “Hangi müşteriler geçen ay beşten fazla ürün satın aldı?” gibi bir soru yazdığında bilgisayar bunu çoğu veritabanında kullanılan özel dil olan SQL’e çevirmek zorunda kalır. text-to-SQL olarak adlandırılan bu görev basit gibi görünse de şaşırtıcı derecede zordur. Sistem kullanıcının ne istediğini anlamalı, bazen devasa ve dağınık olabilen veritabanının içinde doğru tabloları ve sütunları bulmalı ve ardından hem yapısal olarak geçerli hem de orijinal niyete sadık bir sorgu oluşturmalıdır. Önceki sistemler, büyük dil modelleriyle desteklenenler de dahil, birden çok tablo, iç içe mantık veya ince koşullar içeren sorularda sıklıkla başarısız oluyor. Çalıştırıldığında ya çalışmayan ya da yanlış sonuçlar döndüren, doğru görünmesine rağmen hatalı sorgular üretebiliyorlar.
Soruya Doğru Üç Aşamalı Yol
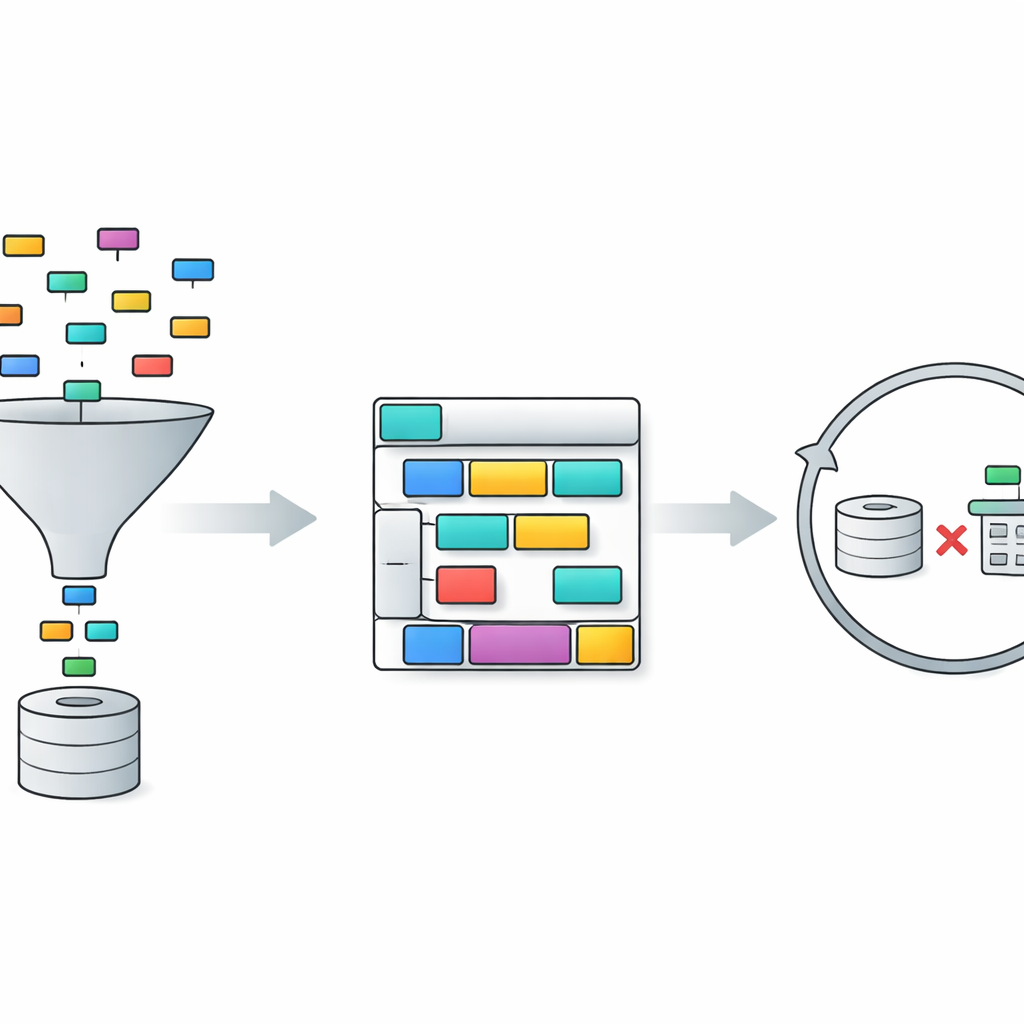
TriSQL bu sorunları üç aşamalı bir boru hattı ile ele alıyor. Önce, soru odaklı bir seçici kullanıcının sözcüklerine ve tam veritabanı yapısına bakar ve hangi tablo ve sütunların gerçekten ilgili olduğuna karar verir. Dili modeli tüm şemaya körü körüne maruz bırakmak yerine, yalnızca önemli parçaları daraltır. İkinci olarak, yapı farkında bir üreteç SQL sorgusunun biçimini detayları doldurmadan önce planlar. Önce hangi deyimlerin gerektiğini ve bunların nasıl bir araya geldiğini gösteren yüksek seviyeli bir iskelet taslağı oluşturur, ardından belirli tabloları, birleştirmeleri ve koşulları yerleştirir. Bu “önce yapı, sonra içerik” yaklaşımı, özellikle uzun ve karışık sorgular için SQL’in katı dil bilgisini korumaya yardımcı olur. Son olarak, karmaşıklık farkında bir iyileştirici ilk taslak sorguyu kontrol eder ve geliştirir; bunu, sorunun ne kadar zor göründüğüne bağlı olarak farklı stratejiler kullanarak yapar.
Soru Zorluğuna Göre Çabayı Ayarlamak
İyileştirme aşaması, TriSQL’in büyük dil modellerini özellikle yenilikçi biçimde kullandığı yerdir. Sistem her sorunun ve taslak sorgunun ne kadar karmaşık olduğunu, kaç tablonun birleştirildiği, iç içe derinlik ve kullanılan kısıt türleri gibi faktörleri göz önünde bulundurarak puanlar. Basit durumlarda yalnızca küçük sözdizimi hatalarını düzeltmek gibi hafif düzeltmeler uygular. Orta zorlukta, deyimleri yeniden düzenler ve sorgunun seçilen şema ile uyumlu olduğundan emin olur. En zorlu sorularda, daha derin muhakeme için dil modelini devreye sokar, bazen problemi alt görevlere bölerek alternatif sorgular yürütür. Kritik olarak, TriSQL hem orijinal hem de iyileştirilmiş sorguları veritabanında çalıştırır ve bunların davranışını—çalışıp çalışmadıkları, ne kadar sürdükleri ve ne döndürdükleri—kullanarak hangi sürümü saklayacağına veya başka bir iyileştirme turu denemeye karar verir.
Sistemi Teste Sokmak
TriSQL’in ne kadar iyi çalıştığını görmek için yazarlar onu Spider adlı yaygın kullanılan bir kıyas seti ve alan bilgisi, alışılmadık cümle kalıpları ve daha gerçekçi sorgu yapıları ekleyen birkaç daha zorlu varyant üzerinde test ederler. İki şeyi ölçerler: üretilen SQL dizgesinin insan yazımı bir referansla tamamen aynı olup olmadığını kontrol eden tam eşleşme ve gerçek çalıştırıldığında doğru cevabı verip vermediğini kontrol eden yürütme doğruluğu. Bu veri kümeleri genelinde, TriSQL şimdiye kadar bildirilen en yüksek yürütme doğruluğuna ulaşırken tam eşleşmede en iyi önceki sistemlerle rekabetçi kalır. Ayrıca daha dayanıklıdır: sorular kolaydan son derece zora doğru ilerledikçe TriSQL’in performansı rakip yöntemlere göre çok daha yavaş düşer. Gerçek dünya bir enerji şebekesi yönetimi veri setindeki ek deneyler, aynı çerçevenin yalnızca veri alma değil, ayrıca ekleme, güncelleme, silme ve tablo oluşturma komutlarını da işleyebildiğini gösterir. Graf veritabanları (Cypher) ve MongoDB boru hatlarına yönelik pilot uyarlamalar, üç aşamalı tasarımın klasik SQL’in ötesine genişleyebileceğini düşündürür.
Günlük Veri Kullanımı İçin Anlamı
Düz bir ifadeyle, bu çalışma insanların artık arama motorlarıyla sohbet ettikleri kadar kolay bir şekilde karmaşık veritabanlarıyla konuşabildiği bir dünyaya bizi daha da yaklaştırıyor. Veritabanının hangi bölümlerine bakılacağını dikkatle seçerek, bir sorgunun yapısını detayları doldurmadan önce planlayarak ve büyük dil modellerinin kullanımını her sorunun zorluğuna göre ayarlayarak, TriSQL çalıştırılma olasılığı ve istenen sonuçları döndürme olasılığı daha yüksek sorgular üretiyor. Belirsiz sorularla ve görülmemiş şemalarla başa çıkmak gibi zorluklar sürse de çalışma, düşünceli, aşamalı bir tasarımın doğal dil arayüzlerini hem daha güçlü hem de günlük kullanıcılar için daha öngörülebilir kılabileceğini gösteriyor.
Atıf: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Anahtar kelimeler: text-to-SQL, doğal dil arayüzleri, veritabanı sorgulama, büyük dil modelleri, sorgu sağlamlığı