Clear Sky Science · tr
Dengesiz veri kümeleriyle başa çıkmak için sınır taşınmasını kullanan bir yaklaşım
Günlük verilerde nadir durumların önemi
Banka dolandırıcılığı ve tıbbi tanıdan müşteri kaybını tahmin etmeye kadar, bilgisayarlardan istediğimiz birçok karar nadir ama kritik olayları tespit etmeye dayanır. Gerçek dünyadaki veri kümelerinin çoğunda bu önemli olaylar sıradan olanların yanında çok azdır. Çoğunlukla "işler yolundaymış" örnekleri gören bir model, en çok önem verdiğimiz durumlara kör olabilir. Bu makale, öğrenme algoritmalarının nadir ve yüksek etkili durumlara uygun dikkat göstermesini sağlamak için böyle çarpık verileri yeniden dengelemeye yönelik yeni bir yöntem sunuyor.
Dengesiz verinin gizli tuzağı
Bir tür örneğin diğerine göre çok daha fazla olduğu durumda, standart makine öğrenimi yöntemleri çoğunluğa odaklanma eğilimindedir ve azınlığı sessizce göz ardı eder. Örneğin bir müşteri kaybı tahmin sistemi, gerçek kaybedenler çok az olduğu için neredeyse herkesi sadık müşteri olarak etiketleyip yine yüksek doğruluk oranı gösterebilir. Benzer sorunlar kaza tespiti, dolandırıcılık izleme ve tıbbi taramada ortaya çıkar; pozitif vakalar nadirdir ama kaçırılması maliyetlidir. Bunu düzeltmenin geleneksel yolları ikiye ayrılır: öğrenme algoritmasını azınlığa "daha fazla önem vermesi" için ayarlamak veya veriyi yeniden şekillendirmek — ya bazı çoğunluk örneklerini kaldırmak (alt örnekleme) ya da ekstra azınlık örnekleri yaratmak (aşırı örnekleme). SMOTE gibi popüler aşırı örnekleme araçları sentetik azınlık örnekleri üretir, ancak bunlar iki sınıfın buluştuğu hassas sınır bölgesini istemeden kalabalıklaştırabilir.
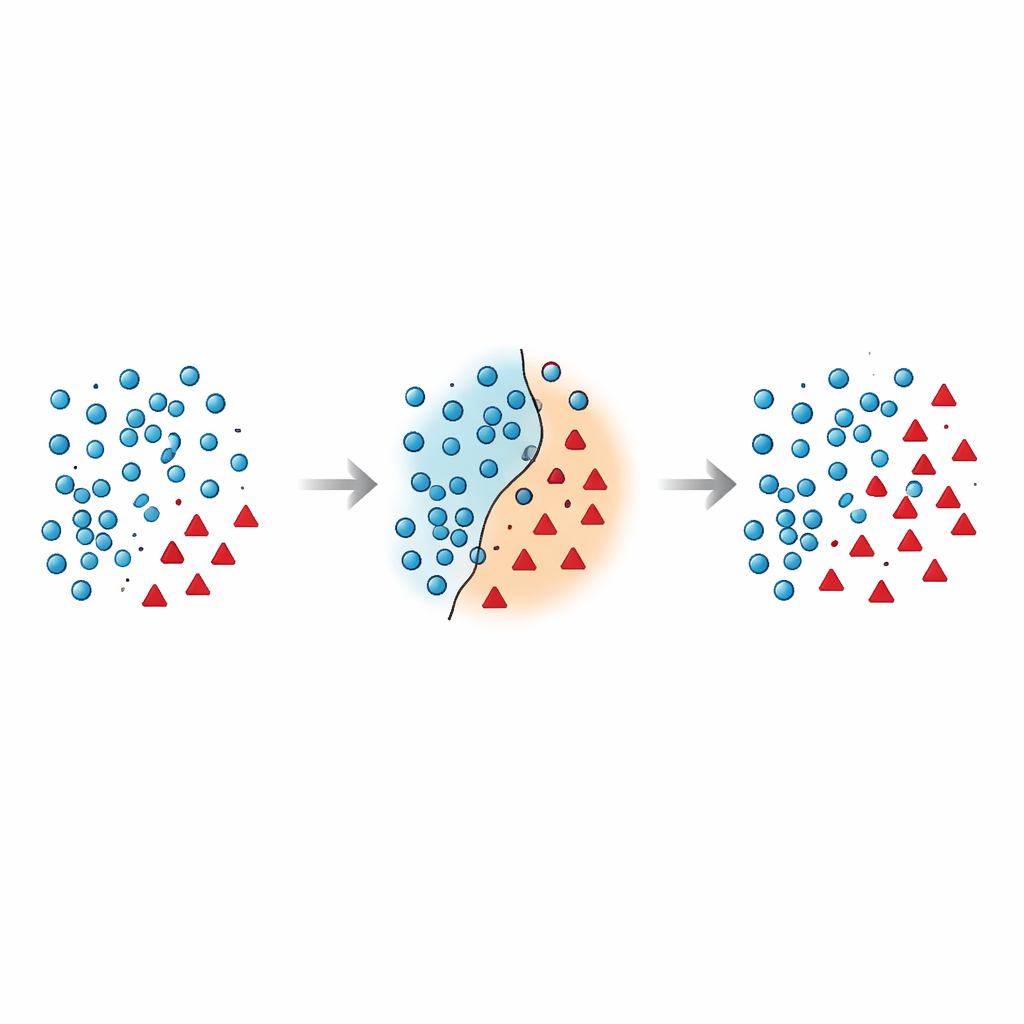
Sınıflar arasındaki sınır neden bu kadar kırılgandır
Yazarlar en tehlikeli hataların karar sınırının yakınında — çoğunluk ve azınlık örneklerinin özellik uzayında örtüştüğü bölgede — gerçekleştiğini savunuyor. Mevcut birçok teknik ya bu riskli bölgeye sentetik noktalar ekliyor ama temizlemiyor, ya da veriyi agresifçe siliyor ve kazayla bilgilendirici örnekleri ortadan kaldırıyor. Son araştırmalar bunu geometrik kısıtlamalar, yerel yoğunluk tahminleri veya gürültü filtreleri kullanarak kontrol altına almaya çalıştı; yine de çoğu yöntem azınlık noktalarını yerinde ele alıyor ve sınır yakınındaki çoğunluk noktalarının nasıl işleneceğini nadiren yeniden düşünüyor. Bu, sınıflandırıcıyı karıştıran ve özellikle yeni verilerde istikrarsız tahminlere yol açan örtüşen ve gürültülü örnekler gibi süregelen bir sorun bırakıyor.
Sınırı düzene sokmak için iki aşamalı bir yol
Makale, bu sorunlu sınır bölgesini açıkça hedef alan iki aşamalı bir veri yeniden şekillendirme yöntemi olan Borderline Shifting Oversampling (BSO) yöntemini tanıtıyor. İlk olarak, her bir çoğunluk örneğinin komşuluğunu tarayıp bunun güvenli bir bölge mi, sınırda mı yoksa açıkça yanlış bir yerde mi (gürültü) olduğunu belirliyor. Azınlık komşularıyla çevrili çoğunluk noktaları ya azınlık tarafına doğru yeniden sınıflandırılıyor ya da gürültü olarak işaretlenip kaldırılıyor; bu, sınırı temizleyip kaydırarak altındaki deseni daha iyi yansıtmasını sağlıyor. İkinci aşamada, yöntem SMOTE benzeri bir enterpolasyon kullanarak yeni sentetik azınlık noktaları üretiyor, ancak yalnızca rafine edilmiş sınır yakınındaki azınlık örnekleri etrafında. Yeni verileri en bilgilendirici oldukları yere yoğunlaştırarak ve açıkça gürültülü noktaları kaçınarak, BSO hem boyut açısından daha dengeli hem de yapısal olarak daha temiz bir eğitim seti oluşturuyor.
Yöntemi teste sokmak
Bunun pratikte ne kadar iyi çalıştığını görmek için araştırmacılar BSO’yu farklı dengesizlik ve örtüşme derecelerine sahip 30 kıyas veri kümesinde değerlendirdi. Bunu Random Over- ve Under-Sampling, SMOTE, Borderline-SMOTE, NearMiss ve aşırı örneklemeyi gürültü temizleme ile karıştıran iki hibrit yöntem (SMOTE-Tomek ve SMOTE-ENN) dahil olmak üzere yedi yaygın alternatifle karşılaştırdılar. Üç yaygın sınıflandırıcı — Destek Vektör Makineleri, Naive Bayes ve Random Forestlar — her yeniden örneklenmiş veri kümesi üzerinde eğitildi. Ham doğruluğa güvenmek yerine, çalışma dengesizlik altında daha bilgilendirici olan F1 skoru, G-mean, recall, precision ve ROC Eğrisi Altındaki Alan (AUC) gibi metrikleri kullandı. Neredeyse tüm veri kümeleri ve sınıflandırıcılar genelinde BSO daha yüksek veya karşılaştırılabilir skorlar verirken daha az varyasyon gösterdi; bu da faydalarının belirli bir model veya ayara bağlı olmaktan ziyade tutarlı olduğunu gösteriyor.
Gerçek dünya kararları için bunun anlamı
Günlük dilde Borderline Shifting yaklaşımı, dağınık veriler için dikkatli bir editör gibi davranır: sınıflar arasındaki ayırıcı çizgiye yakın kafa karıştırıcı örnekleri temizler ve ardından doğru yerlere yeterli sayıda gerçekçi azınlık örneği ekler. Sonuç, öğrenme algoritmalarının nadir ama önemli olayları tanımada, gürültülü örtüşmeler tarafından yanıltılmadan daha başarılı olmasıdır. Ağır maliyetli olabilecek bir azınlık örneğinin kaçırılmasının ciddi sonuçları olduğu dolandırıcılık tespiti, kaza tahmini veya tıbbi triaj gibi uygulamalarda bu yöntem, modelleri daha adil, daha hassas ve daha güvenilir hale getirmenin pratik bir yolunu sunar; üstelik bunun hesaplama yükü de görece mütevazıdır.
Atıf: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Anahtar kelimeler: sınıf dengesizliği, aşırı örnekleme, karar sınırı, anomaliliği tespit, makine öğrenimi sağlamlığı