Clear Sky Science · tr
Büyük dil modelleri çok dilli gerçek doğrulamada Dunning-Kruger benzeri etkiler gösteriyor
Neden akıllı gerçek doğrulama herkes için önemli
Yanlış bilgiler artık her zamankinden daha hızlı yayılıyor ve insanların sağlık, siyaset, bilim ve günlük yaşam hakkında neye inandıklarını şekillendiriyor. Birçok platform ve haber ekibi, doğru veya yanlış olduğunu kontrol etmeye yardımcı olması için özellikle büyük dil modelleri (LLM'ler) gibi yapay zekâya dayanmaya başladı. Bu çalışma görünüşte basit ama kritik bir soruyu soruyor: Bu sistemlere gerçekleri değerlendirme yetkisi verdiğimizde ne sıklıkta doğru oluyorlar, ne kadar emin davranıyorlar ve bu durum farklı diller ve dünya bölgeleri arasında değişiyor mu?
Araştırmacıların yapay zekâyı gerçek dünya söylentilerine karşı nasıl test ettiği
Yapay örnekler üretmek yerine, yazarlar testlerini dünyadaki profesyonel gerçek doğrulama kuruluşlarının zaten araştırdığı 5.000 gerçek iddiadan oluşturdu. Bu iddialar 47 dili kapsıyor ve hem Küresel Kuzey hem de Küresel Güney’den geldi; çevrimiçi söylentilerin karışık, çok kültürlü gerçeğini yansıtıyor. Birden fazla gerçek doğrulayıcı tarafından üzerinde uzlaşılan, açık “doğru” veya “yanlış” kararları içeren beyanlar seçilerek karşılaştırma için sağlam bir yer gerçeği (ground truth) oluşturuldu.
Daha sonra dokuz yaygın kullanılan dil modeli—küçük açık kaynak sistemlerden gelişmiş ticari modellere kadar—her iddia üzerinde çalıştırıldı. İnsanların sohbet botlarına nasıl geribildirim verdiğini yansıtmak için, çoğu istem (prompt) iddianın yazıldığı aynı dilde “Bu doğru mu?” veya “Bu yanlış mı?” gibi basit sorular şeklindeydi. Dördüncü ve daha profesyonel tarzda bir düzenleme ise modeli sanal bir gerçek doğrulayıcıya dönüştüren ayrıntılı bir İngilizce talimat kullanarak yapılandırılmış çıktılar talep etti. İnsan değerlendiriciler modellerin yanıtlarını dikkatle okuyup iddianın doğru, yanlış olduğunu söyleyen veya net bir hüküm vermeyi reddeden ifadeler olarak etiketledi.
Sadece doğru ya da yanlış değil, aynı zamanda "Bilmiyorum" demeyi de ölçmek
Ekip yalnızca isabetleri ve hataları saymakla kalmadı. Modellerin davranışını yakalamak için üç ana ölçüt kullandılar. Birincisi, “seçici doğruluk” bir modelin gerçekten bir tutum alıp bir iddiayı doğru veya yanlış ilan ettiğinde ne sıklıkta doğru olduğuna baktı. İkincisi, “çekimserliğe uygun doğruluk” modelin tahmin yapmak yerine belirsizliği kabul etmesini, hatta bunu arzu edilir görmeyi değerlendirdi; bu, tıp veya seçimler gibi hassas alanlarda hayati önem taşıyor. Üçüncüsü, “kesinlik oranı” modelin ne sıklıkta kati bir cevap verdiğini izleyerek davranışındaki özgüvenin kaba bir göstergesi oldu.
Adım adım rehberlik sunan profesyonel tarzda istem, tüm modellerde tutarlı şekilde doğruluğu yükseltti. Ancak bu aynı zamanda bir takasın da ortaya çıkmasına yol açtı: daha küçük modeller sıklıkla daha kararlı hale gelirken daha güvenilir olmadılar; daha büyük modeller ise yapıdan yararlanarak daha az ama daha iyi yanıtlar verdiler. Günlük, sohbet benzeri istemler özellikle daha zayıf modellerde daha temkinli davranış üretti, ancak doğruluklarını bir miktar düşürdü.
Daha az yetenekli sistemlerin daha emin davranması
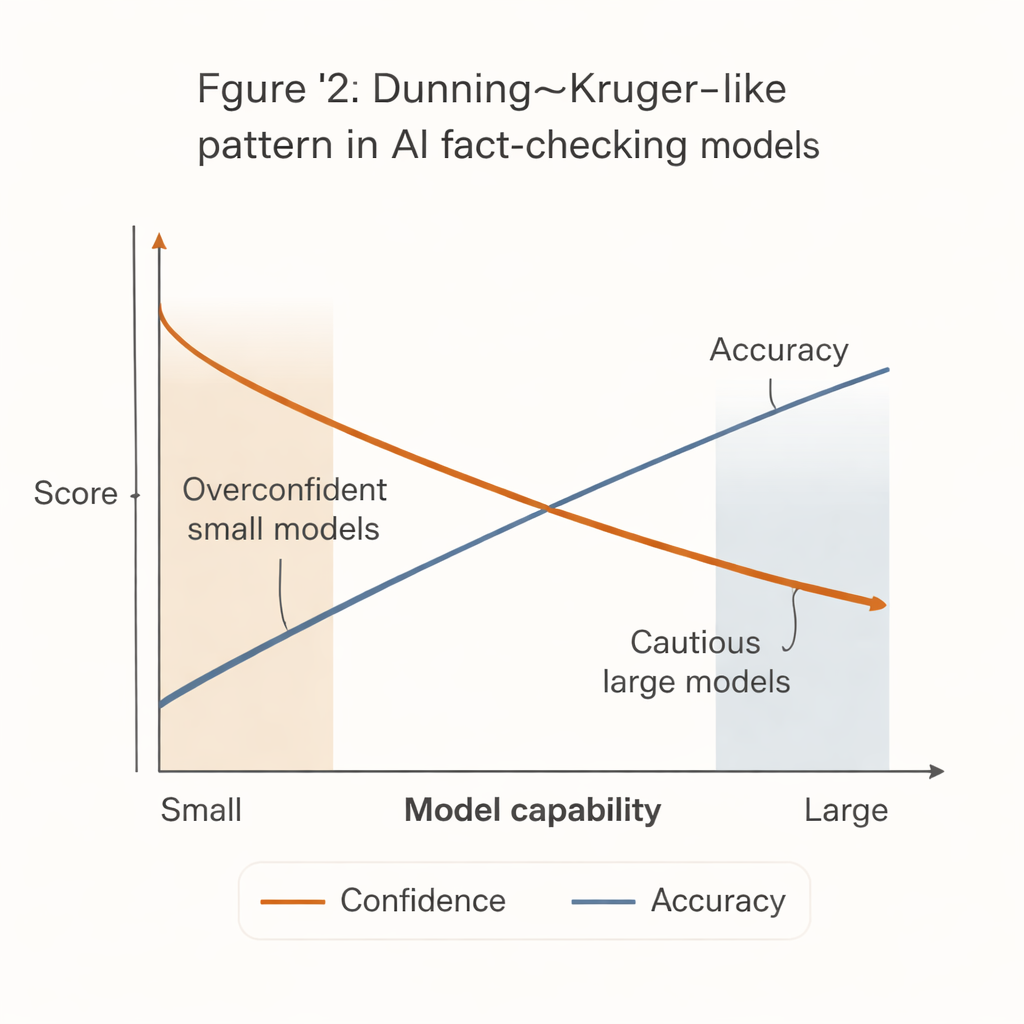
İnsan psikolojisindeki iyi bilinen Dunning–Kruger etkisini anımsatan çarpıcı bir desen ortaya çıktı: en az yetenekli sistemler en kendinden emin görünenlerdi. Küçük, ucuz modeller çoğu iddiada kesin hükümler verme eğilimindeydi, ancak doğrulukları belirgin şekilde daha düşüktü. Buna karşılık, gelişmiş GPT sürümleri gibi en güçlü modeller taahhütte bulunduklarında çok daha doğru olurken, özellikle zor veya belirsiz ifadelerde çekimser kalmaya daha yatkındılar.
Bu “güven–yeterlik boşluğu”nun gerçek dünya sonuçları var. Birçok sınırlı bütçeli haber odası, sivil toplum grubu ve yerel gerçek doğrulama kuruluşu en güçlü yapay zekâ sistemlerini karşılayamıyor. Daha kararlı görünen ama daha sık yanlış yapan daha küçük, ucuz modelleri benimseme olasılıkları daha yüksek. Bu araçlar iş akışlarına veya topluluk moderasyon sistemlerine dikkatli korumalar olmadan entegre edilirse, kendinden emin ama yanlış gerçek doğrulamalar üreterek yanlış bilgiyi güçlendirebilirler.
Diller ve bölgeler arasında eşitsiz performans
Çalışma ayrıca bu sistemlerin herkese eşit şekilde iyi performans göstermediğini açığa çıkardı. Birkaç büyük dil arasında modeller genel olarak İngilizce iddialarda en iyi, Portekizce ve Hintçe’de ise biraz daha kötü performans gösterdi. Daha büyük modeller İngilizce dışındaki dillerde daha temkinli yanıtlar verme eğilimindeydi, ancak doğruluk açısından yine de daha küçük modelleri geride bıraktı. Yazarlar Küresel Kuzey ile Küresel Güney’e bağlı iddiaları karşılaştırdıklarında, çoğu modelde Güney’e ait iddialarda daha fazla zorlanma görüldü. Küçük sistemler çoğu zaman doğruluk kaybı yaşarken kendinden emin kalmaya devam ederken, büyük modeller kesinlikte daha büyük düşüşler ama doğrulukta daha küçük düşüşler gösterdi; bu da kendi belirsizliklerini sezdiklerini ve geri çekildiklerini düşündürüyor.
Güvenilir yapay zekâ araçlarının geleceği için ne anlama geliyor
Uzman olmayan biri için temel mesaj açık: bugünün yapay zekâ gerçek doğrulayıcıları eşit değil ve en erişilebilir olanları en yanıltıcı olabilir. Güçlü modeller dikkatli ve doğru olabilir, ancak maliyetlidir ve bazen aşırı ölçülü davranır. Daha zayıf modeller cesurdur ama özellikle İngilizce dışındaki dillerde ve Küresel Güney’e ait hikâyelerde yanılma olasılıkları daha yüksektir. Yazarlar, yapay zekânın insan gerçek doğrulayıcıları desteklemesi gerektiğini, onları ikame etmemesi gerektiğini ve tasarım ile politika seçimlerinin sistemlere ne zaman susmaları gerektiğini öğretecek daha iyi kalibrasyon ile yüksek kaliteli araçlara daha adil erişim yönünde ilerlemesi gerektiğini savunuyor. Aksi takdirde, yanlış bilgiyi önlemek için geliştirilen aynı teknoloji, çözmeyi amaçladığı bilgi eşitsizliklerini derinleştirebilir.
Atıf: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Anahtar kelimeler: yanlış bilgi, gerçek doğrulama, büyük dil modelleri, Yapay Zeka güveni, çok dilli önyargı