Clear Sky Science · tr
Alt ekstremite rehabilitasyon robotlarında artan konfor için derin pekiştirmeli öğrenmeye dayalı insansı bir kontrol stratejisi
İnsanların Yeniden Yürümesine Yardımcı Olan Robotlar
İnme veya omurilik yaralanması sonrası yürümekte zorluk çeken biri için terapi yavaş, yorucu ve rahatsız edici olabilir. Alt ekstremite rehabilitasyon robotları, hastanın bacaklarını uygulama sırasında desteklemek ve yönlendirmek üzere tasarlanmıştır, ancak günümüz makineleri sık sık sert ve "robotik" hissi verir. Bu çalışma, bu robotlara daha insanvari bir beyin kazandırmanın —gelişmiş öğrenme algoritmaları kullanarak— eğitimleri nasıl daha nazik, daha doğal ve nihayetinde hastalar için daha etkili kılabileceğini araştırıyor.
Neden Yürüme Çalışması Doğal Hissettirmeli
Nüfus yaşlandıkça, ciddi yürüme sorunlarıyla yaşayanların sayısı artıyor ve pek çoğu robot destekli rehabilitasyona yöneliyor. Geleneksel robotlar önceden programlanmış bacak yollarını izler ve eklemleri hareket ettirmek için basit kontrol kuralları kullanır. Güvenilir olmalarına karşın, bu yöntemler insan hareketinin karmaşık gerçekliğiyle başa çıkmakta zorlanır: herkesin gait'i biraz farklıdır ve katı bir robot garip veya hatta ağrılı çekiş/itme kuvvetleri uygulayabilir. Yazarlar, rehabilitasyonun iyi işler hale gelmesi için robotun hastayı dik ve hareket halinde tutmasının ötesinde, doğal yürüme örüntülerine uyum sağlaması ve vücuda uyguladığı kuvvetleri en aza indirmesi gerektiğini savunuyorlar.
Gerçek İnsan Adımlarından Öğrenme
Robota insanların gerçekten nasıl yürüdüğünü öğretmek için araştırmacılar önce bacaklar ve gövde için basitleştirilmiş bir matematiksel model kurdular. Ardından beş sağlıklı gönüllüden yüksek hassasiyetli 3B hareket yakalama sistemi ve zemin kuvvet plakaları kullanarak gait verileri kaydettiler. Kalça, diz, ayak bileği ve gövde üzerine yerleştirilen reflektif işaretleyiciler sayesinde her eklemin bir adım boyunca nasıl hareket ettiği hesaplandı; ayak altındaki sensörler ise her bacağın zemine ne kadar kuvvet uyguladığını ölçtü. Bu ölçümlerden, kalça ve diz açıları için düzgün referans eğrileri oluşturdular ve eklem kuvvetlerinin zaman içindeki değişimini izleyerek normal yürüyüşün hem şekil hem de ritmini yakaladılar.
Güvenliği Koruyan Daha Akıllı Bir Kontrolör
Makalede merkezî olan şey, derin pekiştirmeli öğrenme (DRL) ile klasik bir orantı-türev (PD) kontrolörünü birleştiren yeni bir "insansı" kontrol stratejisidir. DRL, sanal bir ajanın eylemleri dener, sonuçları gözlemler ve bir ödül sinyalini maksimize ederek kademeli olarak neyin en iyi olduğunu keşfettiği yapay zeka türüdür. Bu durumda ajan PD kontrolörünün üstünde oturur: robotun eklem açılarını ve hızlarını görür ve hangi torkları uygulayacağına karar verirken, PD katmanı eklemlerin güvenli, insanvari hedef açılardan çok uzaklaşmamasını sağlar. Ödül fonksiyonu, stabil ileri yürümeyi teşvik edecek şekilde dikkatle tasarlanmıştır; ani hareketler, eklemde büyük kuvvetler veya aşırı eğilme ya da düşük ayak yerden kalkışı gibi hastada rahatsızlık yaratacak duruşlar cezalandırılır.
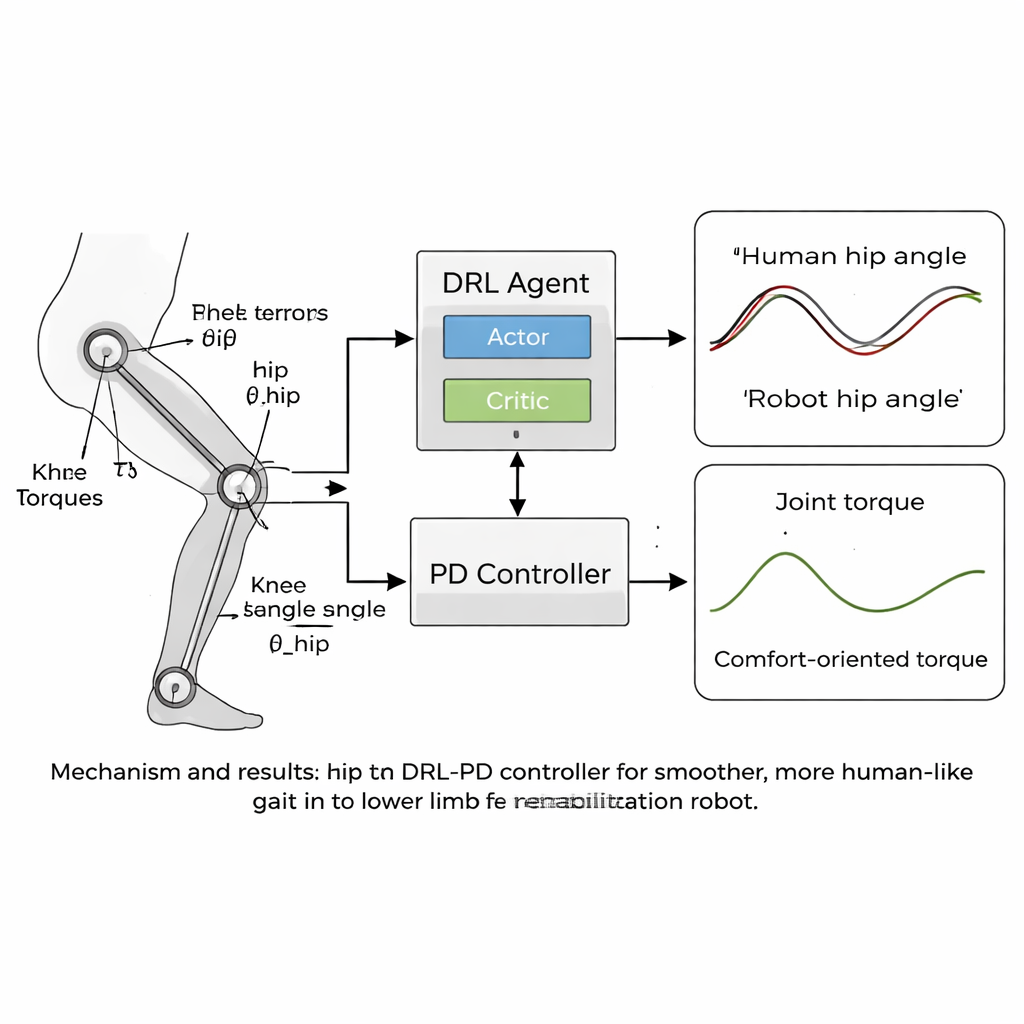
Daha Akıcı Hareket, İnsan Gait'ine Daha Yakın
Ekip, yaklaşımlarını kalça ve diz eklemleri gait verileriyle uyumlu bir alt ekstremite rehabilitasyon robotu modelinde bilgisayar simülasyonlarında test etti. Binlerce eğitim bölümünde DRL-PD kontrolörü, eklem açılarını insan referans desenlerine sıkı sıkıya uyduran tekrarlayan bir yürüyüş döngüsü üretmeyi öğrendi. Robotun kalçaları ve dizleri düzenli, kararlı döngüler halinde hareket etti; bu güvenilir, tekrarlanabilir bir gait işaretiydi. Kritik olarak, eklemleri sürdürmek için gereken torklar standart bir PD kontrolöre kıyasla daha düzgün ve daha küçük hale geldi. Nicel ölçümler, takip hatalarının sadece birkaç yüzbinde radyana düştüğünü ve eklem torklarının değişim hızının —hastada kuvvetlerin ne kadar "sarsıntılı" hissedileceğinin bir vekili— yarıdan fazla azaldığını gösterdi. Kontrolör ayrıca modelin bacak kütleleri birkaç yüzdeyle değiştirildiğinde bile kararlı kaldı; bu da gerçek kullanıcılar arasındaki farklılıklara tolerans gösterebileceğini düşündürüyor.
Geleceğin Rehabilitasyon Robotları İçin Ne Anlama Geliyor
Uzman olmayanlar için çıkarılacak ders basit: bir robotun gerçek verilerden insan yürüyüşünün ritimlerini ve sınırlarını öğrenmesine izin vererek ve onu düzgün ve nazik olmaya ödüllendirerek, insanların yürümeyi daha doğal ve daha az stresli hissettiren bir şekilde çalışmasına yardımcı olan makineler tasarlayabiliriz. Robot, kişiyle birlikte hareket ederse onunla değil ona karşı hareket ederse hastalar daha uzun ve daha sık seanslara katılmaya istekli olabilir. Mevcut sonuçlar simülasyonlardan geliyor ve eğitim için güçlü bilgisayarlara ihtiyaç duyuyor olsa da, öğrenme tamamlandığında kontrolör gerçek cihazlarda verimli çalıştırılabilir. Yazarlar bu çalışmayı her hastanın benzersiz gait'ine ve konfor gereksinimlerine uyum sağlayan kişiselleştirilmiş, uyarlanabilir rehabilitasyon robotlarına doğru bir adım olarak görüyor; bu da hem iyileşmeyi hem de yaşam kalitesini potansiyel olarak iyileştirebilir.
Atıf: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Anahtar kelimeler: rehabilitasyon robotları, yürüme eğitimi, derin pekiştirmeli öğrenme, ekzoskeleton, hasta konforu