Clear Sky Science · tr
Farsça romatoloji uzmanlık sınavlarında büyük dil modellerinin performansının değerlendirilmesi: GPT-4o vs. GPT-5.1’in doğruluğu ve klinik akıl yürütmesi
Bu neden doktorlar ve hastalar için önemli
Yapay zeka hızla tıp sınıflarına ve kliniklere giriyor, ancak bu araçların çoğu testi İngilizceye odaklanıyor. Bu çalışma milyonlarca Farsça konuşan kişi için önemli bir soruyu gündeme getiriyor: gelişmiş yapay zeka sohbet robotları —özellikle GPT‑4o ve GPT‑5.1— Farsça yazılmış karmaşık romatoloji sınav sorularını ne kadar iyi yanıtlıyor? Cevap, eğitimcilere, eğitim görenlere ve hastalara bu araçların nerede güvenli şekilde öğrenmeye yardımcı olabileceğini ve nerede insan uzmanlığının vazgeçilmez kaldığını anlamada yardımcı olur.
Yapay zekayı teste sokmak
Araştırmacılar, uzmanların sertifika almak için geçmesi gereken 2023 ve 2024 İran Romatoloji Board sınavlarından 204 çoktan seçmeli soru topladı. Yedi kusurlu soru çıkarıldıktan sonra 197 madde kullanıldı. Her soru, eşlik eden görüntü veya grafikler dahil olmak üzere, ayrı ve temiz sohbetlerde Farsça olarak GPT‑4o ve GPT‑5.1’e girildi. Modellerden en iyi seçeneği seçmeleri ve gerekçelerini açıklamaları istendi; bu, bir eğitimlinin çalışırken bir yapay zeka aracına nasıl soru sorabileceğini yansıtıyor.
Cevaplar ve akıl yürütmenin kontrolü
Performans iki şekilde değerlendirildi. İlk olarak, modellerin seçtiği seçenekler resmi cevap anahtarıyla karşılaştırılarak basit bir doğru‑yanlış doğruluk ölçüsü elde edildi. İkinci olarak, altı board sertifikalı romatolog her bir açıklamanın kalitesini açıkça yanlış akıl yürütmeden tam ve klinik açıdan sağlam akıl yürütmeye kadar beş puanlı bir ölçekle bağımsız olarak puanladı. Her modelin cevapları, birbirlerinin puanlarından ve resmi cevap anahtarından habersiz iki farklı romatolog tarafından değerlendirildi. Bu yaklaşım, yapay zekanın sadece "doğru tahmin" yapıp yapmadığını değil, mantığının uzmanların düşünme biçimine benzer olup olmadığını görmeyi sağladı.
Yeni modelin performansı nasıl oldu
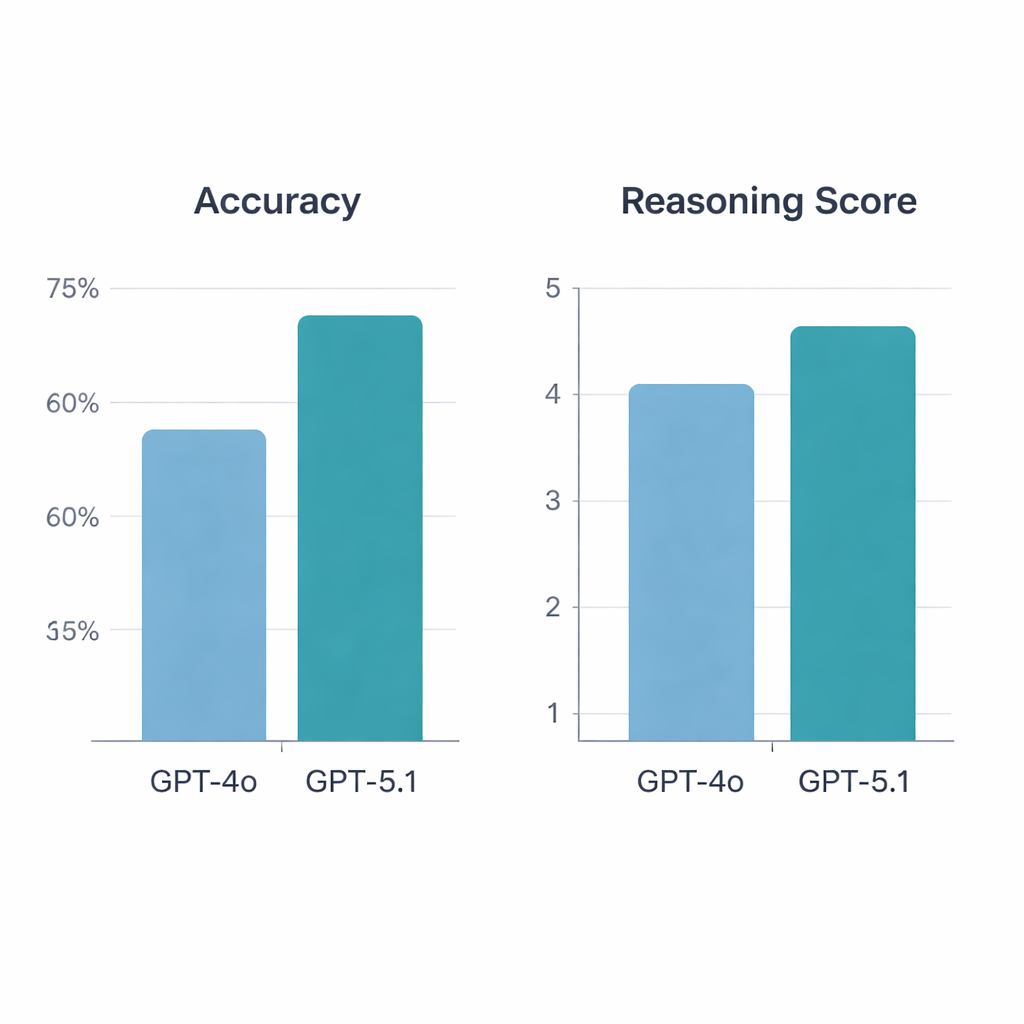
GPT‑5.1, GPT‑4o’ya karşı açık bir üstünlük gösterdi. 197 geçerli soruda GPT‑4o %64,5 doğruluk sağlarken GPT‑5.1 %76 doğruluğa ulaştı—istatistiksel olarak anlamlı bir artış. Her iki model de 113 soruyu doğru, 34 soruyu yanlış yanıtladı, ancak GPT‑5.1 tek başına GPT‑4o’nun kaçırdığı 36 ek soruyu çözdü; GPT‑4o ise yalnızca 13 soruda tek doğru olan modeldi. Romatologlar açıklamaları puanladığında GPT‑5.1 yine önde çıktı; ortalama akıl yürütme puanı 5 üzerinden 4,47 iken GPT‑4o için 4,13’tü ve en yüksek puanları daha sık aldı. GPT‑4o’nun akıl yürütme kalitesi temel bilimler, vaka öyküleri, tanı veya tedavi odaklı sorulara göre değişkenlik gösterirken, GPT‑5.1 tüm kategorilerde daha dengeli bir performans sergiledi.
Güçlü yönler, boşluklar ve insan anlaşmazlıkları
Çalışma önemli nüansları ortaya koydu. Bir modelin nihai cevabı yanlış olsa bile, uzmanlar bazen onun akıl yürütmesini oldukça tutarlı buldu; bu durum sınav puanlaması ile gerçek dünya klinik düşüncesi arasındaki bir boşluğu vurguluyor. Aynı zamanda, romatolog puanlayıcılar arasındaki uzlaşma sadece ılımlı düzeydeydi; bu da klinisyenlerin "iyi akıl yürütme"nin ne olduğuna kendilerinin de farklı baktığını gösteriyor. Dil de etkili görünüyordu: İngilizce ve İspanyolca üzerine önceki çalışmalar benzer modeller için daha yüksek puanlar bildirdi; bu da yapay zekanın büyük dünya dillerini Farsçadan daha iyi işlediğini düşündürüyor. Yazarlar, bu sohbet robotlarının ikna edici açıklamalar üretebileceğini ve bunların gerçek hataları gizleyebileceğini; ayrıca sistemler güncellendikçe performanslarının değişebileceğini vurguluyor.
İleriye dönük anlamı nedir
Halk için mesaj şu: Yapay zekanın en yeni nesli Farsça uzman tıp sınavlarını ele almada giderek daha iyi oluyor, ancak sıkı eğitimin veya uzman yargısının yerini alacak durumda değil. GPT‑5.1, romatoloji eğitim görenler için konu özetleri sunma, vakaları adım adım ele alma ve yapılandırılmış açıklamalar sağlama gibi yararlı bir çalışma arkadaşı olabilir—ancak tanı veya tedaviyle ilgili yüksek riskli kararlar için nihai söz olarak güvenilmemelidir. Yazarlar, bu araçların tıp eğitimine ve nihayetinde günlük hasta bakımına güvenli biçimde entegre edilmesini belirlemek için daha büyük çokdilli çalışmalar, zaman içinde tekrarlanan testler ve gerçekçi klinik simülasyonlar çağrısında bulunuyor.
Atıf: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Anahtar kelimeler: romatoloji, Farsça tıp eğitimi, büyük dil modelleri, klinik akıl yürütme, board sınavları